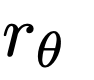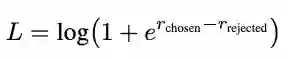Reinforcement learning from human feedback (RLHF) has emerged as a powerful technique to make large language models (LLMs) easier to use and more effective. A core piece of the RLHF process is the training and utilization of a model of human preferences that acts as a reward function for optimization. This approach, which operates at the intersection of many stakeholders and academic disciplines, remains poorly understood. RLHF reward models are often cited as being central to achieving performance, yet very few descriptors of capabilities, evaluations, training methods, or open-source models exist. Given this lack of information, further study and transparency is needed for learned RLHF reward models. In this paper, we illustrate the complex history of optimizing preferences, and articulate lines of inquiry to understand the sociotechnical context of reward models. In particular, we highlight the ontological differences between costs, rewards, and preferences at stake in RLHF's foundations, related methodological tensions, and possible research directions to improve general understanding of how reward models function.
翻译:基于人类反馈的强化学习(RLHF)已成为一种强大的技术,使大型语言模型(LLMs)更易用且更高效。RLHF流程的核心在于训练并利用一个人类偏好模型,该模型作为优化过程的奖励函数。这种方法涉及众多利益相关者和学科领域,但至今仍未被充分理解。尽管RLHF奖励模型常被认为是实现性能的关键,但关于其能力、评估、训练方法或开源模型的描述却寥寥无几。鉴于信息的匮乏,对经训练的RLHF奖励模型进行进一步研究和透明化至关重要。本文阐述了偏好优化的复杂历史,并提出了理解奖励模型社会技术背景的研究思路。我们特别强调了RLHF基础中成本、奖励和偏好之间本体论的差异、相关方法论的张力,以及旨在提升对奖励模型运行机制普遍理解的可能研究方向。