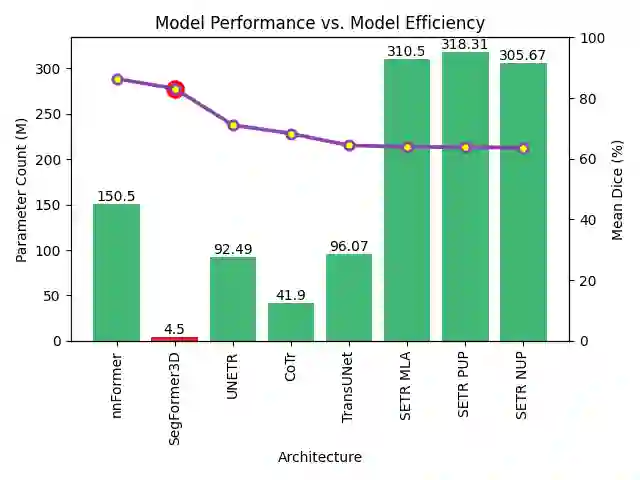
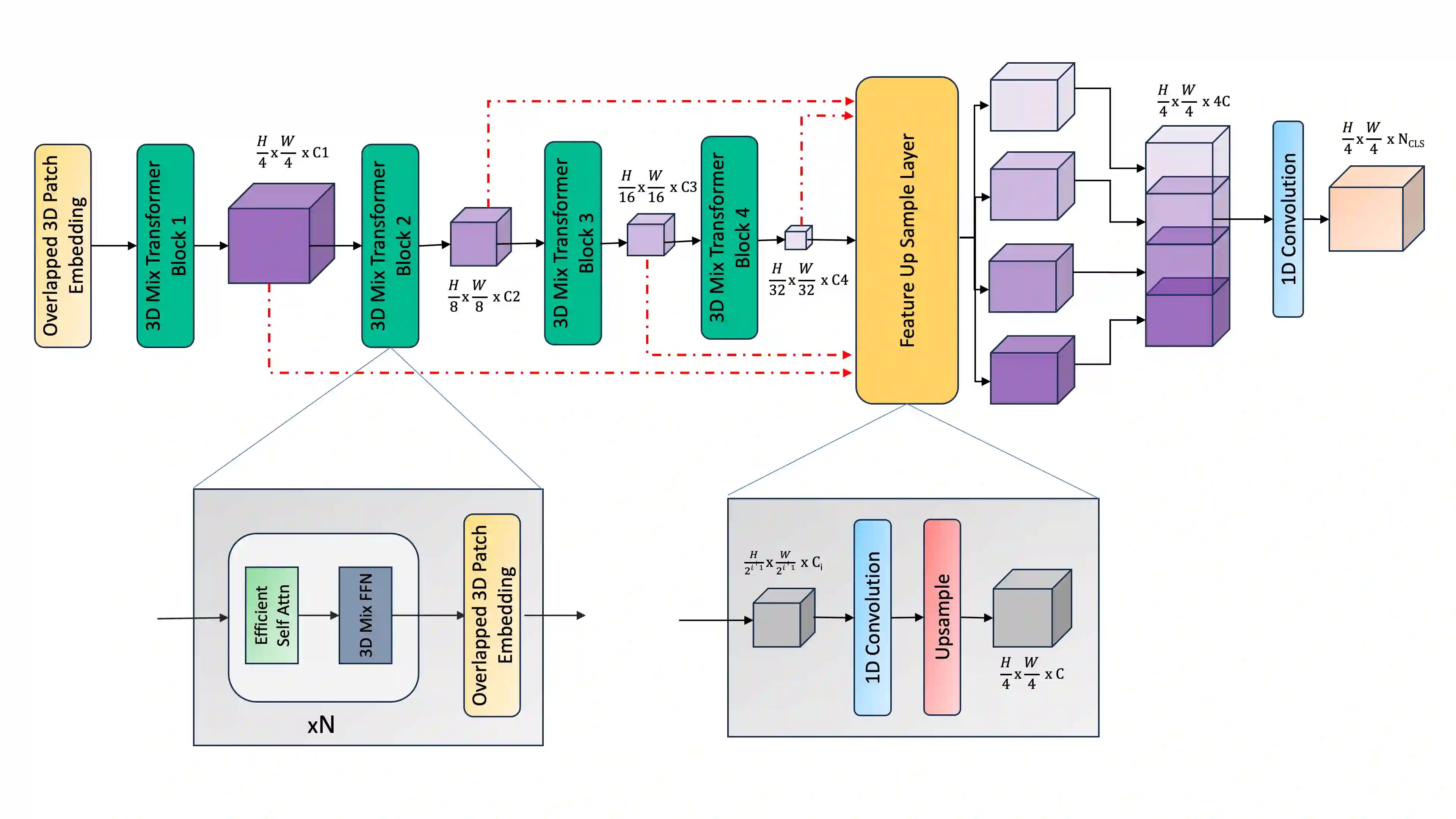
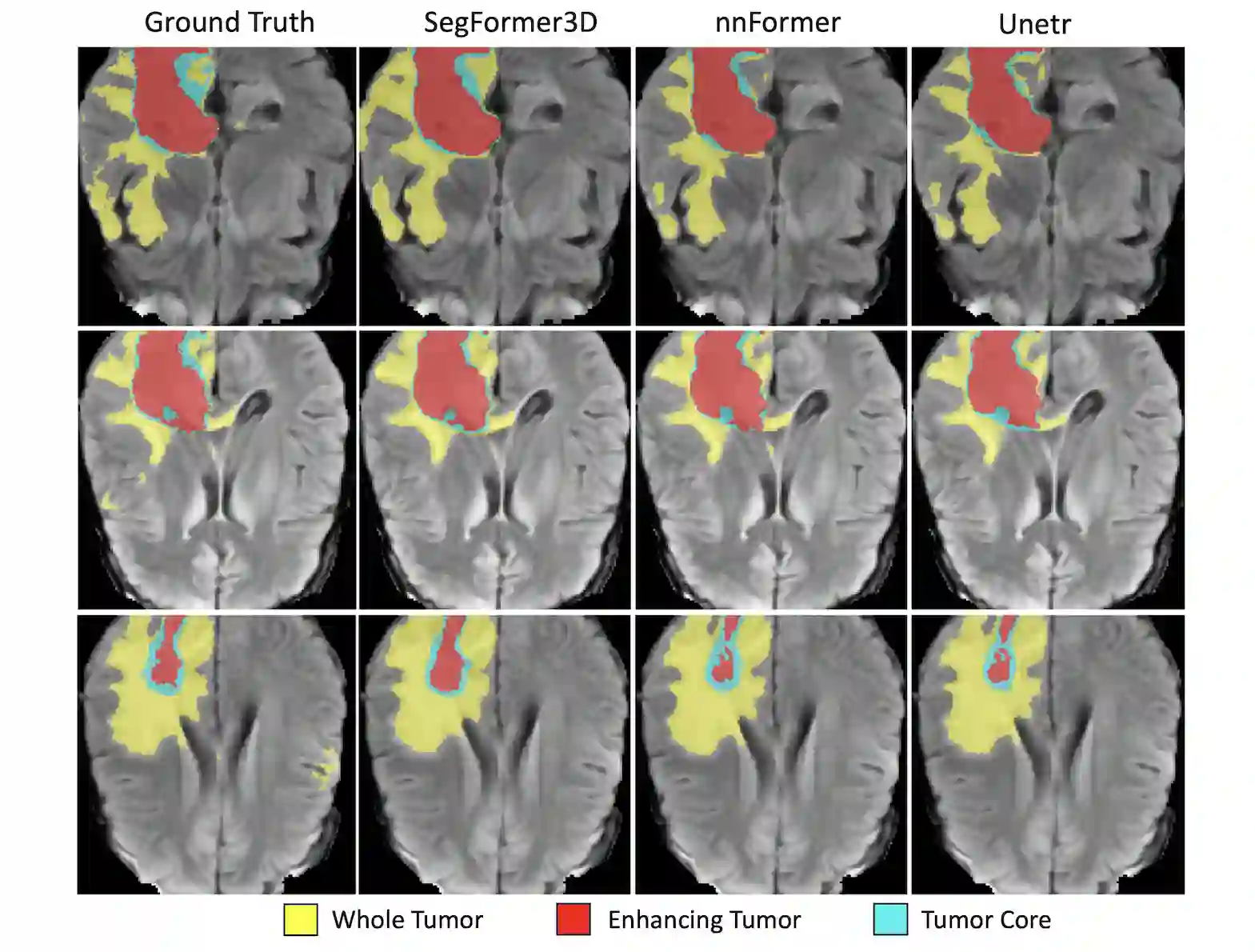
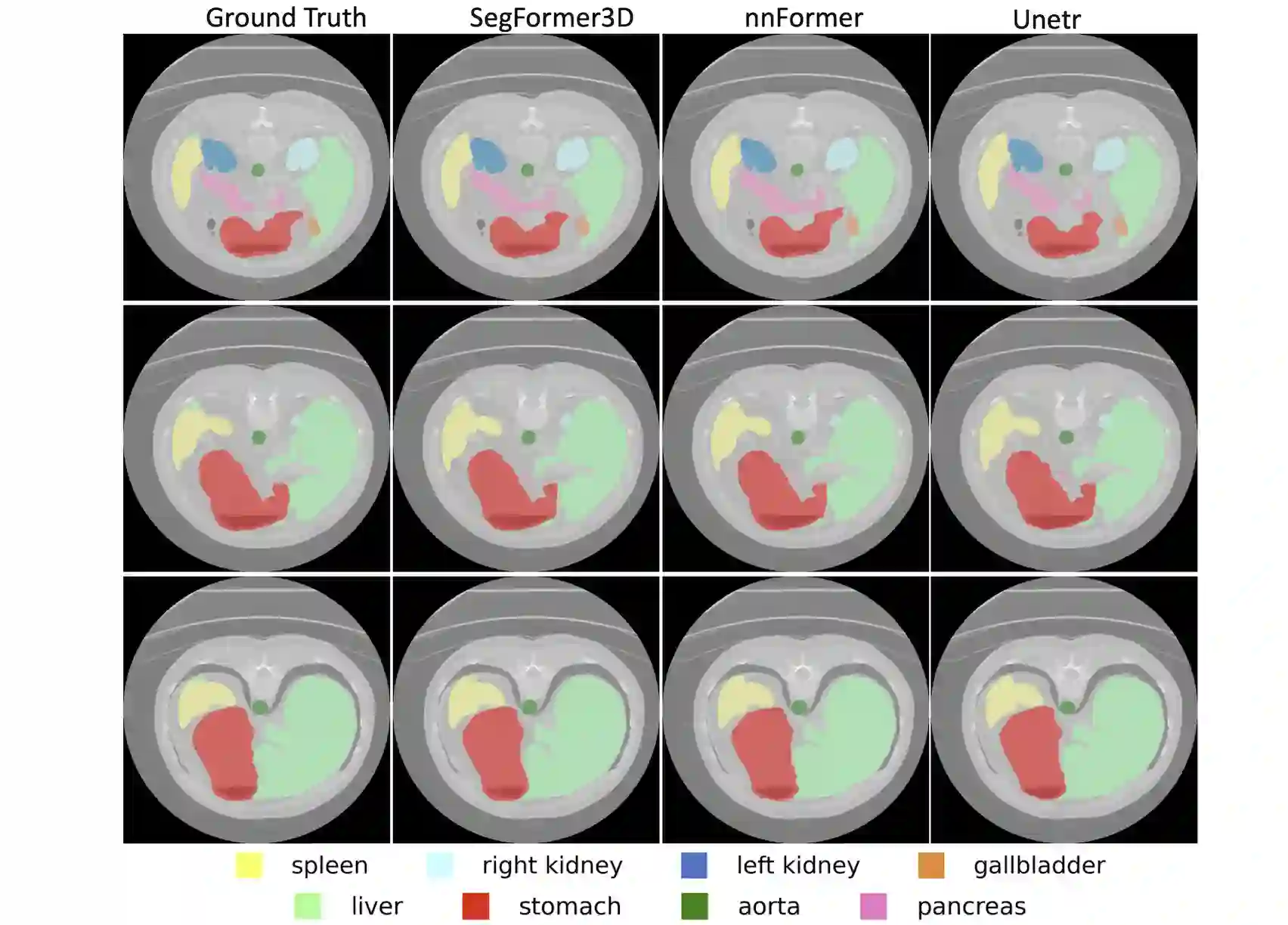
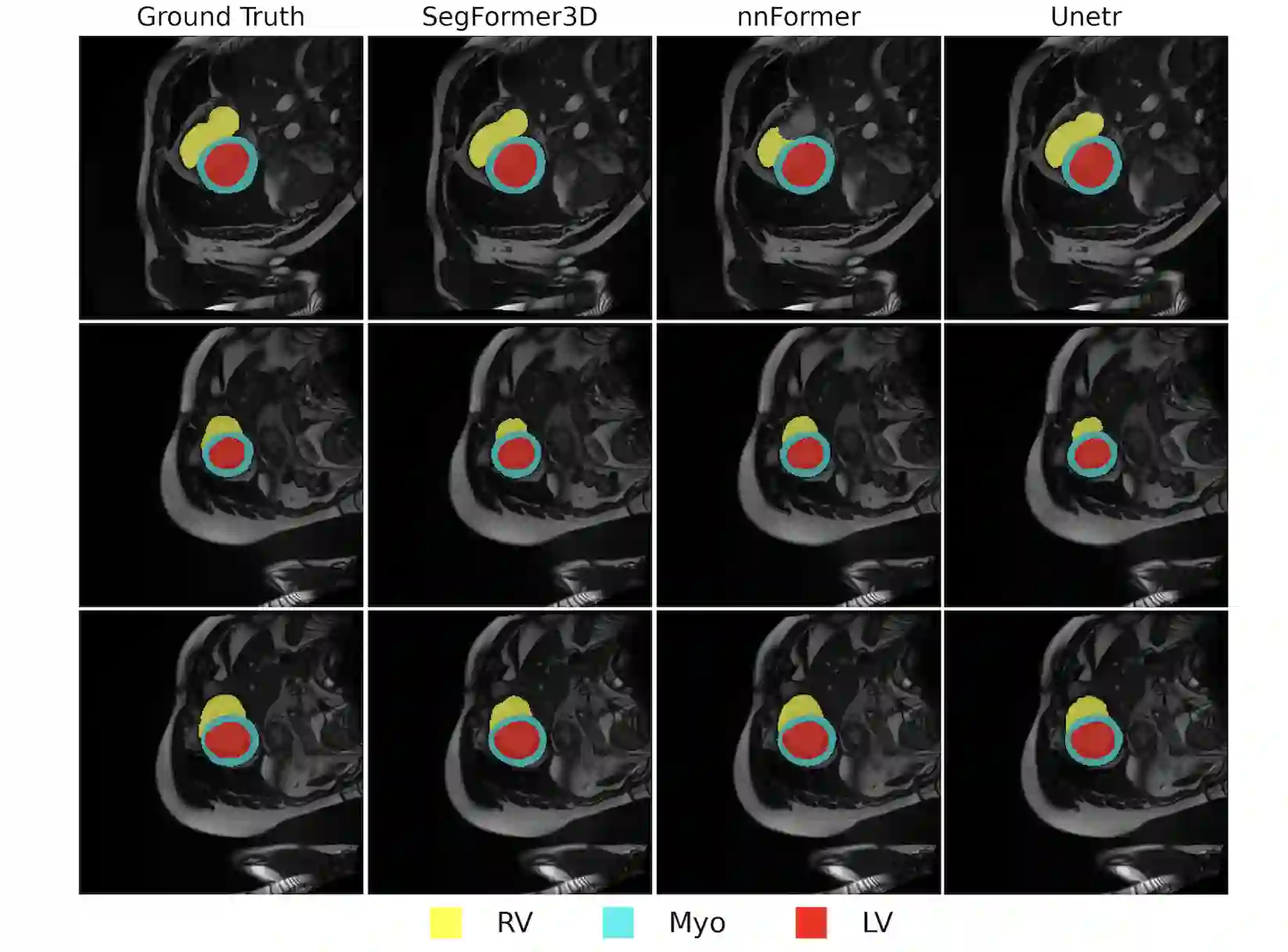
The adoption of Vision Transformers (ViTs) based architectures represents a significant advancement in 3D Medical Image (MI) segmentation, surpassing traditional Convolutional Neural Network (CNN) models by enhancing global contextual understanding. While this paradigm shift has significantly enhanced 3D segmentation performance, state-of-the-art architectures require extremely large and complex architectures with large scale computing resources for training and deployment. Furthermore, in the context of limited datasets, often encountered in medical imaging, larger models can present hurdles in both model generalization and convergence. In response to these challenges and to demonstrate that lightweight models are a valuable area of research in 3D medical imaging, we present SegFormer3D, a hierarchical Transformer that calculates attention across multiscale volumetric features. Additionally, SegFormer3D avoids complex decoders and uses an all-MLP decoder to aggregate local and global attention features to produce highly accurate segmentation masks. The proposed memory efficient Transformer preserves the performance characteristics of a significantly larger model in a compact design. SegFormer3D democratizes deep learning for 3D medical image segmentation by offering a model with 33x less parameters and a 13x reduction in GFLOPS compared to the current state-of-the-art (SOTA). We benchmark SegFormer3D against the current SOTA models on three widely used datasets Synapse, BRaTs, and ACDC, achieving competitive results. Code: https://github.com/OSUPCVLab/SegFormer3D.git
翻译:基于视觉Transformer(ViTs)的架构的采用代表了三维医学图像分割领域的一项重大进展,通过增强全局上下文理解能力超越了传统卷积神经网络模型。尽管这种范式转变显著提升了三维分割性能,但现有最先进的架构需要极为庞大且复杂的结构以及大规模计算资源进行训练和部署。此外,在医学影像中常见的小规模数据集背景下,更大的模型可能在模型泛化和收敛方面带来挑战。针对这些问题,并为了证明轻量化模型是三维医学成像领域有价值的研究方向,我们提出了SegFormer3D——一种层次化Transformer,可跨多尺度体素特征计算注意力。此外,SegFormer3D避免了复杂的解码器,采用全MLP解码器聚合局部与全局注意力特征,以生成高精度的分割掩膜。所提出的内存高效Transformer在紧凑设计中保留了显著更大模型的性能特征。SegFormer3D通过提供相比当前最先进模型参数减少33倍、GFLOPS降低13倍的模型,推动了三维医学图像分割深度学习的普及化。我们在三个广泛使用的数据集(Synapse、BRaTs和ACDC)上对SegFormer3D与当前最先进模型进行了基准测试,取得了竞争性的结果。代码:https://github.com/OSUPCVLab/SegFormer3D.git