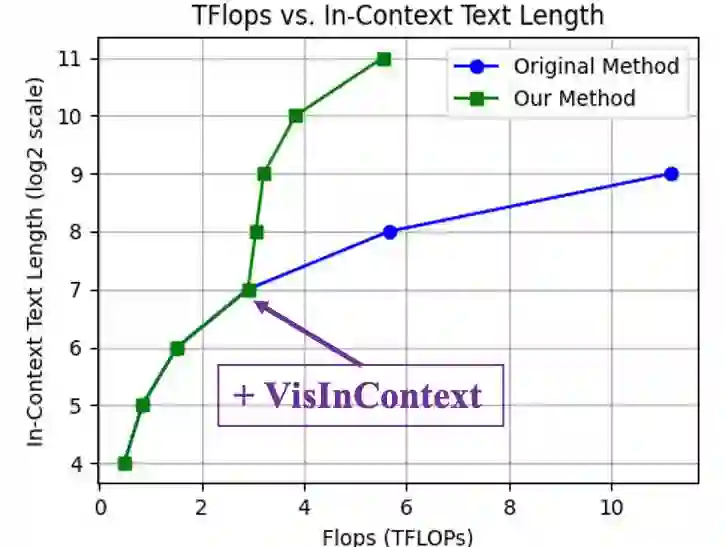
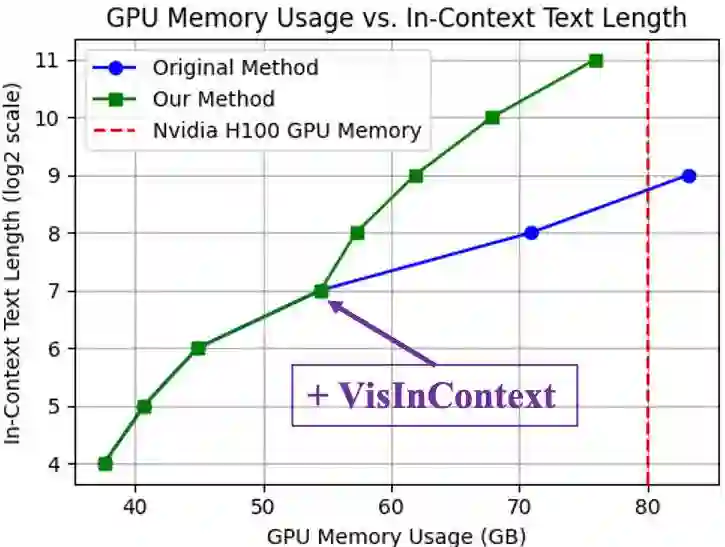
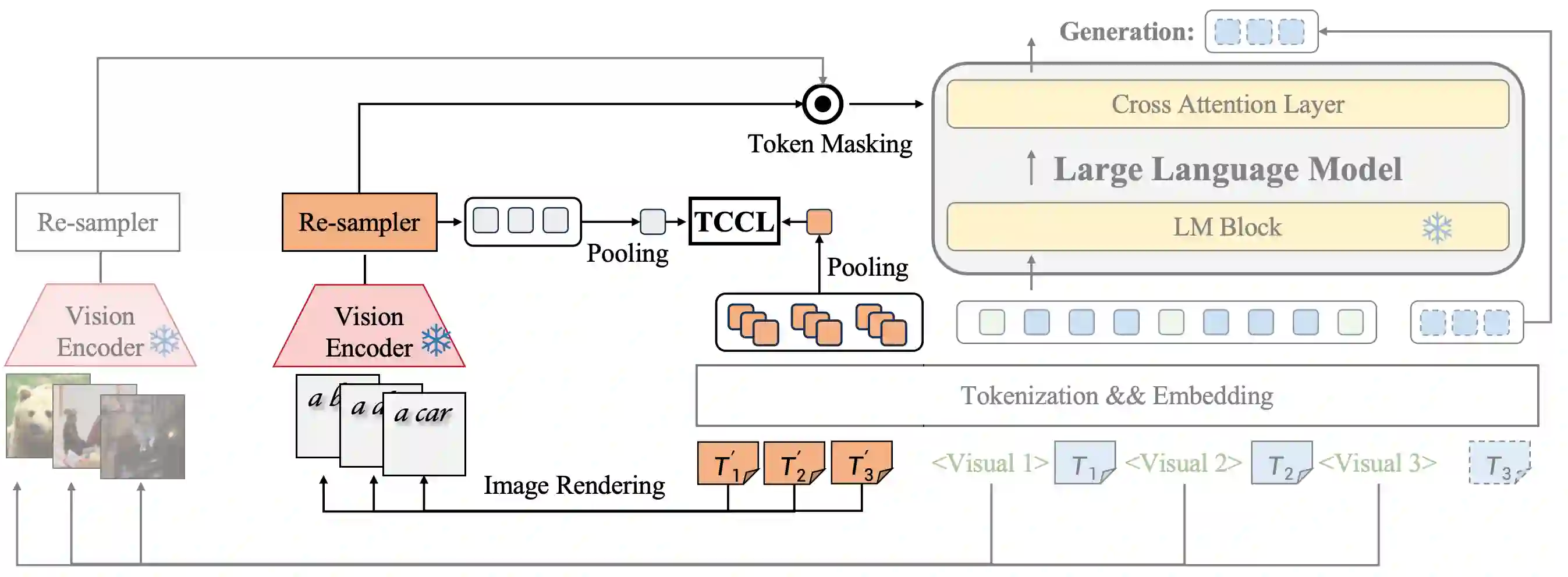
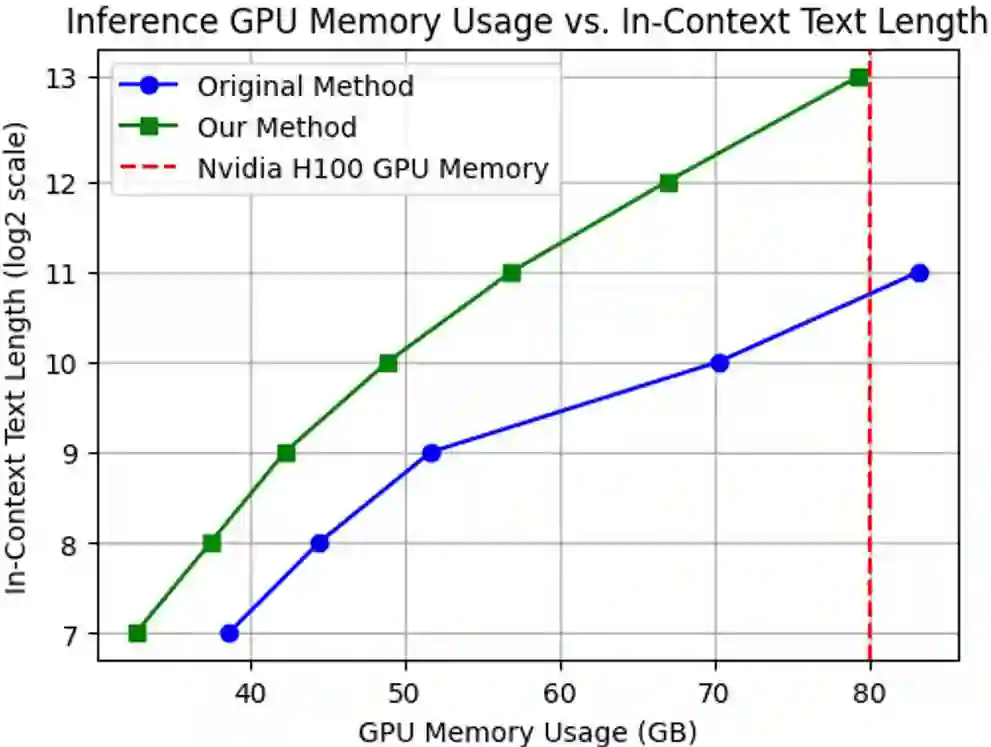
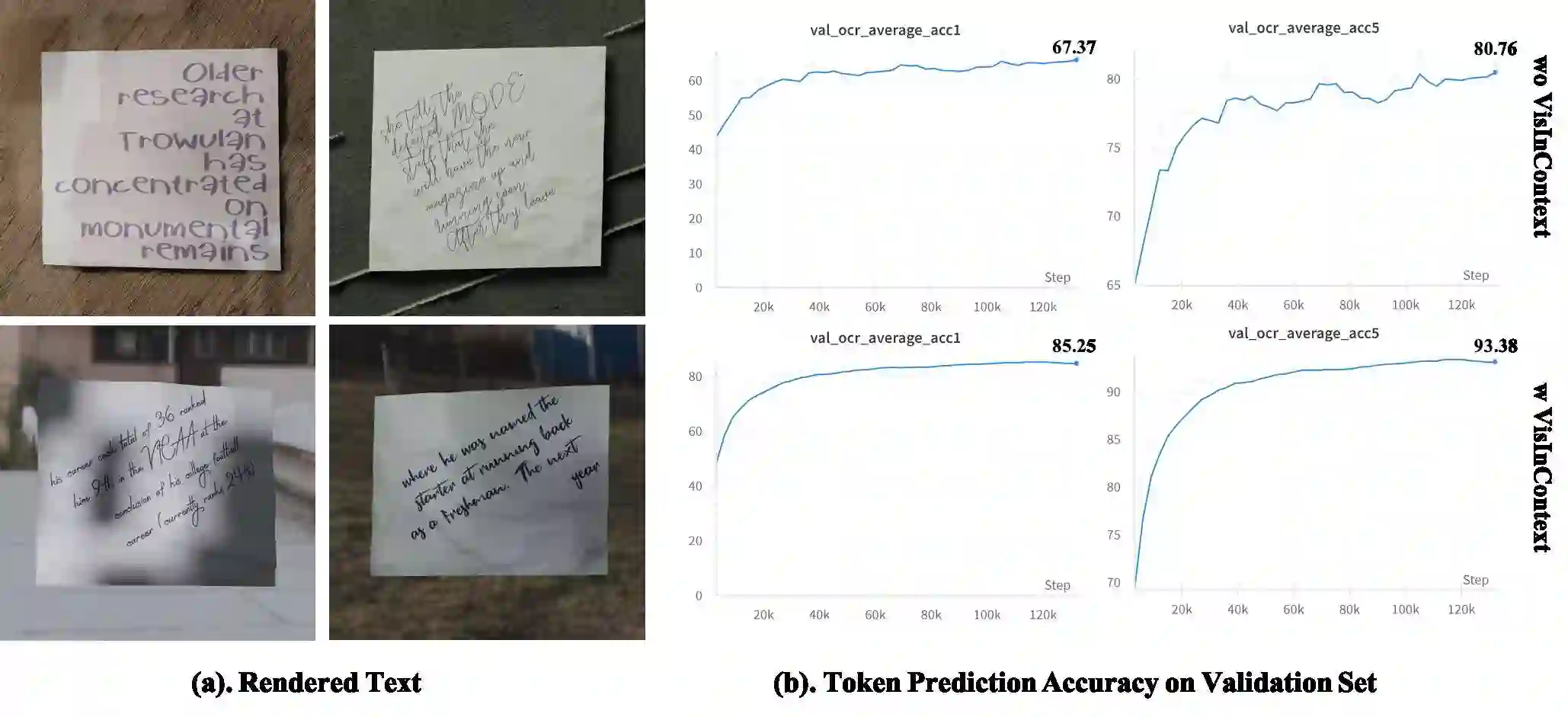
Training models with longer in-context lengths is a significant challenge for multimodal model due to substantial GPU memory and computational costs. This exploratory study does not present state-of-the-art models; rather, it introduces an innovative method designed to increase in-context text length in multi-modality large language models (MLLMs) efficiently. We present Visualized In-Context Text Processing (VisInContext), which processes long in-context text using visual tokens. This technique significantly reduces GPU memory usage and floating point operations (FLOPs) for both training and inferenceing stage. For instance, our method expands the pre-training in-context text length from 256 to 2048 tokens with nearly same FLOPs for a 56 billion parameter MOE model. Experimental results demonstrate that model trained with VisInContext delivers superior performance on common downstream benchmarks for in-context few-shot evaluation. Additionally, VisInContext is complementary to existing methods for increasing in-context text length and enhances document understanding capabilities, showing great potential in document QA tasks and sequential document retrieval.
翻译:在多模态模型中,由于巨大的GPU内存和计算成本,训练具有更长上下文长度的模型是一项重大挑战。这项探索性研究并未提出最先进的模型,而是引入了一种创新方法,旨在高效增加多模态大语言模型(MLLMs)中的上下文文本长度。我们提出了可视化上下文文本处理(VisInContext),该方法利用视觉标记处理长上下文文本。此技术显著降低了训练和推理阶段的GPU内存使用量及浮点运算(FLOPs)。例如,对于一个560亿参数的MOE模型,我们的方法将预训练的上下文文本长度从256个标记扩展到2048个标记,而FLOPs几乎保持不变。实验结果表明,使用VisInContext训练的模型在常见的上下文少样本评估下游基准测试中表现出更优的性能。此外,VisInContext与现有增加上下文文本长度的方法具有互补性,并增强了文档理解能力,在文档问答任务和顺序文档检索中展现出巨大潜力。