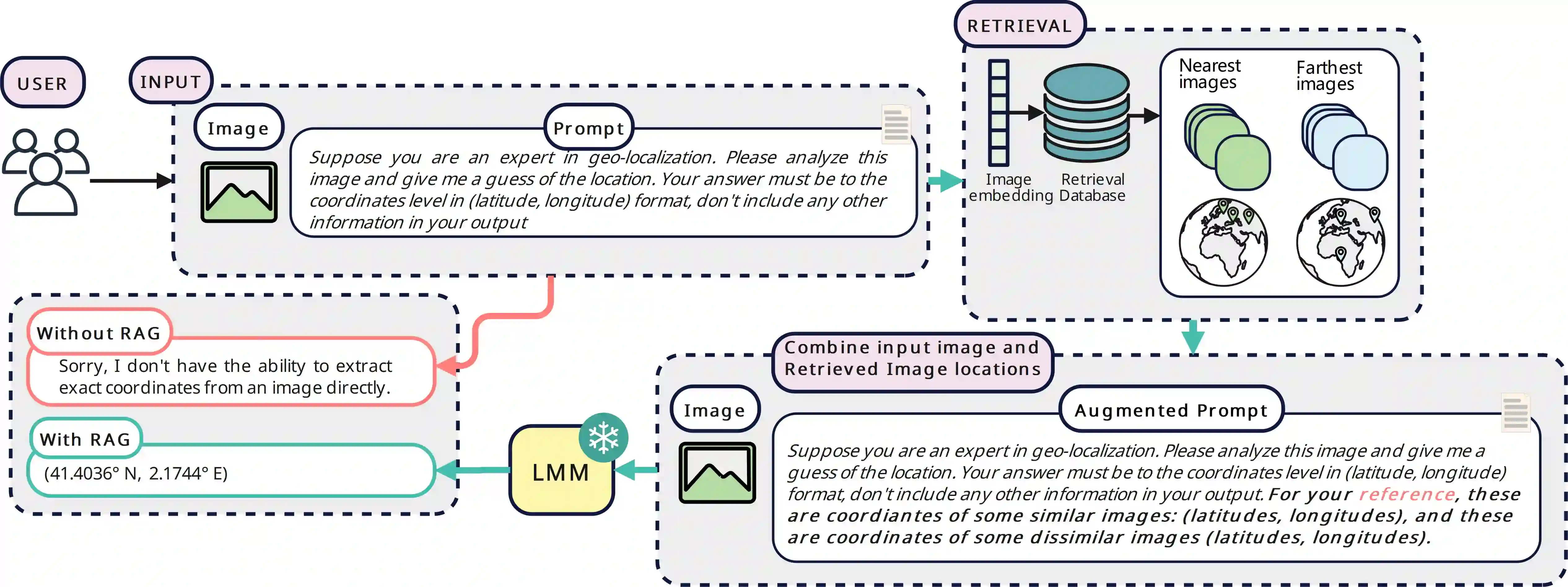
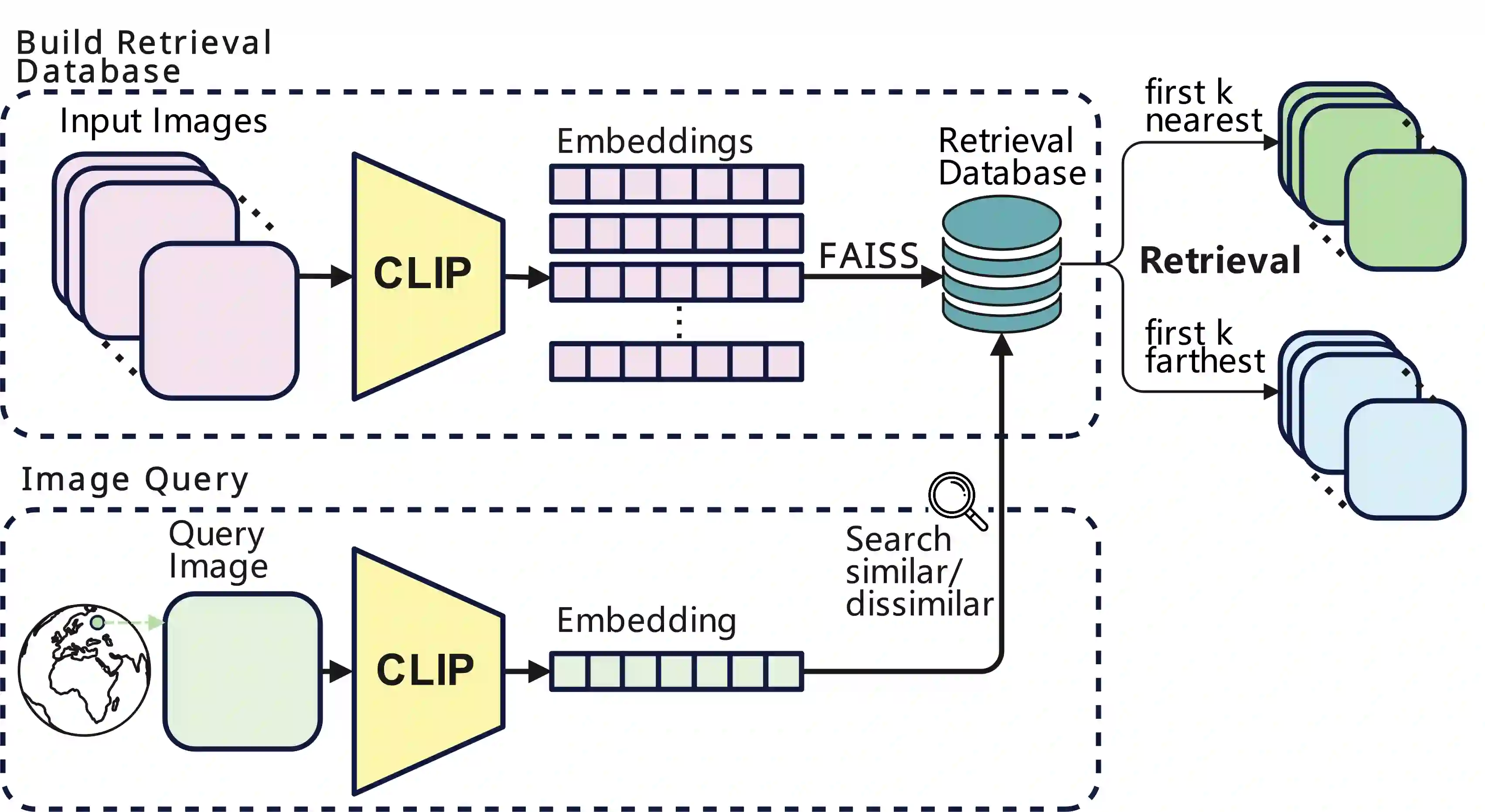
Geolocating precise locations from images presents a challenging problem in computer vision and information retrieval.Traditional methods typically employ either classification, which dividing the Earth surface into grid cells and classifying images accordingly, or retrieval, which identifying locations by matching images with a database of image-location pairs. However, classification-based approaches are limited by the cell size and cannot yield precise predictions, while retrieval-based systems usually suffer from poor search quality and inadequate coverage of the global landscape at varied scale and aggregation levels. To overcome these drawbacks, we present Img2Loc, a novel system that redefines image geolocalization as a text generation task. This is achieved using cutting-edge large multi-modality models like GPT4V or LLaVA with retrieval augmented generation. Img2Loc first employs CLIP-based representations to generate an image-based coordinate query database. It then uniquely combines query results with images itself, forming elaborate prompts customized for LMMs. When tested on benchmark datasets such as Im2GPS3k and YFCC4k, Img2Loc not only surpasses the performance of previous state-of-the-art models but does so without any model training.
翻译:从图像中精准定位地理位置是计算机视觉与信息检索领域的一项挑战性课题。传统方法主要分为两类:分类法将地球表面划分为网格单元并进行图像分类,检索法则通过将图像与图像-位置配对数据库进行匹配来定位。然而,基于分类的方法受限于单元格尺寸,难以生成精确预测;而基于检索的系统常因搜索质量低下及对全球不同尺度与聚合层面的覆盖不足而受限。为克服这些缺陷,我们提出Img2Loc系统——一种将图像地理定位重构为文本生成任务的新型方法。该系统利用GPT4V或LLaVA等前沿大型多模态模型,结合检索增强生成技术实现。Img2Loc首先采用基于CLIP的表示构建图像坐标查询数据库,随后创新性地将查询结果与原始图像融合,生成专为多模态大模型定制的精细提示。在Im2GPS3k和YFCC4k等基准数据集上的测试表明,Img2Loc无需任何模型训练即可超越现有最先进模型的性能。