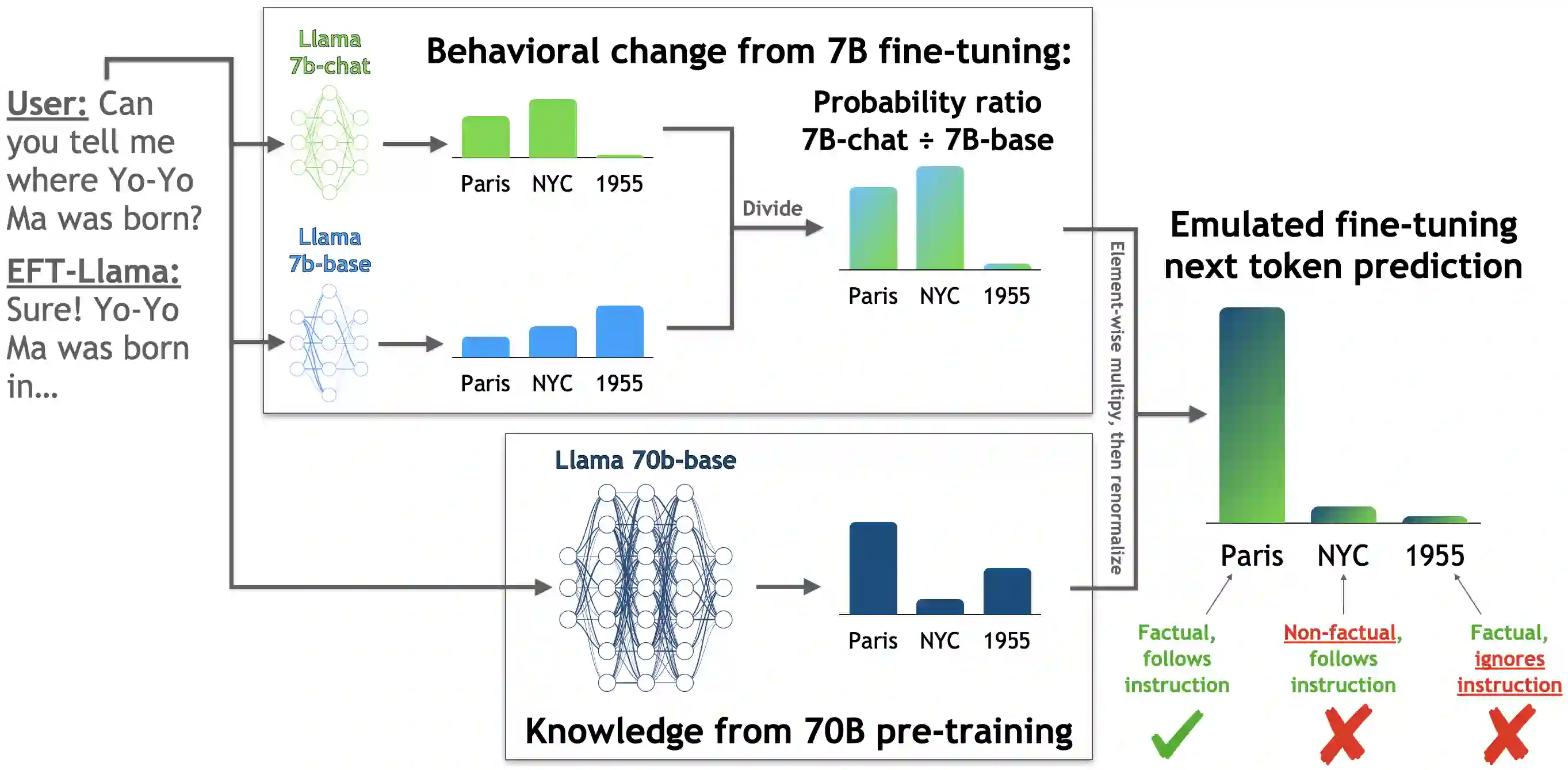
Widely used language models (LMs) are typically built by scaling up a two-stage training pipeline: a pre-training stage that uses a very large, diverse dataset of text and a fine-tuning (sometimes, 'alignment') stage that uses targeted examples or other specifications of desired behaviors. While it has been hypothesized that knowledge and skills come from pre-training, and fine-tuning mostly filters this knowledge and skillset, this intuition has not been extensively tested. To aid in doing so, we introduce a novel technique for decoupling the knowledge and skills gained in these two stages, enabling a direct answer to the question, "What would happen if we combined the knowledge learned by a large model during pre-training with the knowledge learned by a small model during fine-tuning (or vice versa)?" Using an RL-based framework derived from recent developments in learning from human preferences, we introduce emulated fine-tuning (EFT), a principled and practical method for sampling from a distribution that approximates (or 'emulates') the result of pre-training and fine-tuning at different scales. Our experiments with EFT show that scaling up fine-tuning tends to improve helpfulness, while scaling up pre-training tends to improve factuality. Beyond decoupling scale, we show that EFT enables test-time adjustment of competing behavioral traits like helpfulness and harmlessness without additional training. Finally, a special case of emulated fine-tuning, which we call LM up-scaling, avoids resource-intensive fine-tuning of large pre-trained models by ensembling them with small fine-tuned models, essentially emulating the result of fine-tuning the large pre-trained model. Up-scaling consistently improves helpfulness and factuality of instruction-following models in the Llama, Llama-2, and Falcon families, without additional hyperparameters or training.
翻译:广泛使用的语言模型(LMs)通常通过扩展两阶段训练流程构建:预训练阶段利用大规模、多样化的文本数据集,微调(有时称为"对齐")阶段则使用目标示例或行为规范。尽管已有假设认为知识和技能来自预训练,而微调主要是过滤这些知识与技能集,但这种直觉尚未得到充分验证。为促进相关研究,我们提出一种解耦两阶段知识获取的新型技术,可直接回答:"如果将大模型在预训练阶段学到的知识与小模型在微调阶段学到的知识进行组合(或反之),会产生什么结果?"基于近期从人类偏好中学习的最新进展,我们引入基于强化学习的框架——模拟微调(EFT),这是一种可采样近似(或"模拟")不同规模下预训练与微调结果分布的原则性实用方法。实验表明,扩大微调规模倾向于提升实用性,而扩大预训练规模则倾向于改善事实准确性。除解耦规模外,我们证明EFT无需额外训练即可在测试时调整相互竞争的行为特性(如实用性与无害性)。最后,EFT的特例——大语言模型升尺度(LM up-scaling),通过将大型预训练模型与小规模微调模型集成,避免了对大型预训练模型进行资源密集型的微调,从而模拟其微调效果。升尺度方法在Llama、Llama-2和Falcon系列指令遵循模型中持续提升实用性与事实准确性,且无需额外超参数或训练。