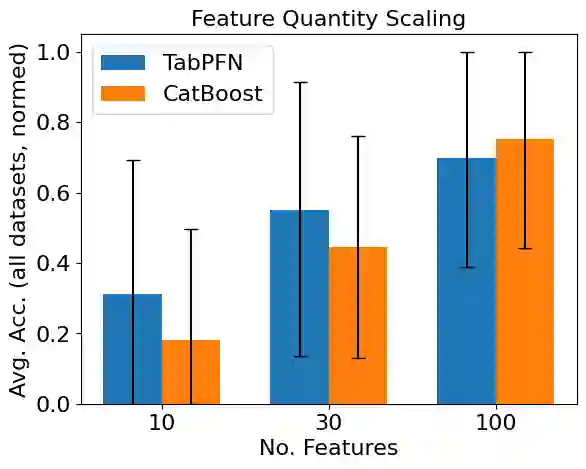
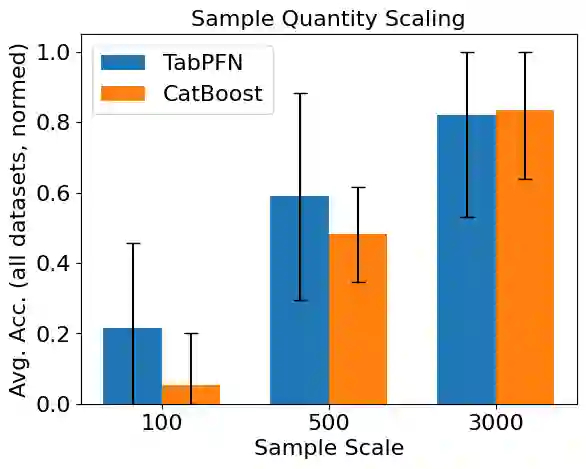
Tabular classification has traditionally relied on supervised algorithms, which estimate the parameters of a prediction model using its training data. Recently, Prior-Data Fitted Networks (PFNs) such as TabPFN have successfully learned to classify tabular data in-context: the model parameters are designed to classify new samples based on labelled training samples given after the model training. While such models show great promise, their applicability to real-world data remains limited due to the computational scale needed. Here we study the following question: given a pre-trained PFN for tabular data, what is the best way to summarize the labelled training samples before feeding them to the model? We conduct an initial investigation of sketching and feature-selection methods for TabPFN, and note certain key differences between it and conventionally fitted tabular models.
翻译:表格分类传统上依赖于监督学习算法,这类算法通过训练数据估计预测模型的参数。近期,基于先验数据拟合网络(PFN)的TabPFN等模型成功实现了表格数据的上下文内分类:模型参数被设计为在模型训练后,基于给定的标注训练样本对新样本进行分类。尽管这类模型前景广阔,但受限于计算规模,其在实际数据中的应用仍有限。本文研究以下问题:针对表格数据的预训练PFN,在将标注训练样本输入模型之前,对其进行总结的最佳方式是什么?我们初步探索了针对TabPFN的草图绘制与特征选择方法,并指出了其与传统拟合表格模型之间的关键差异。