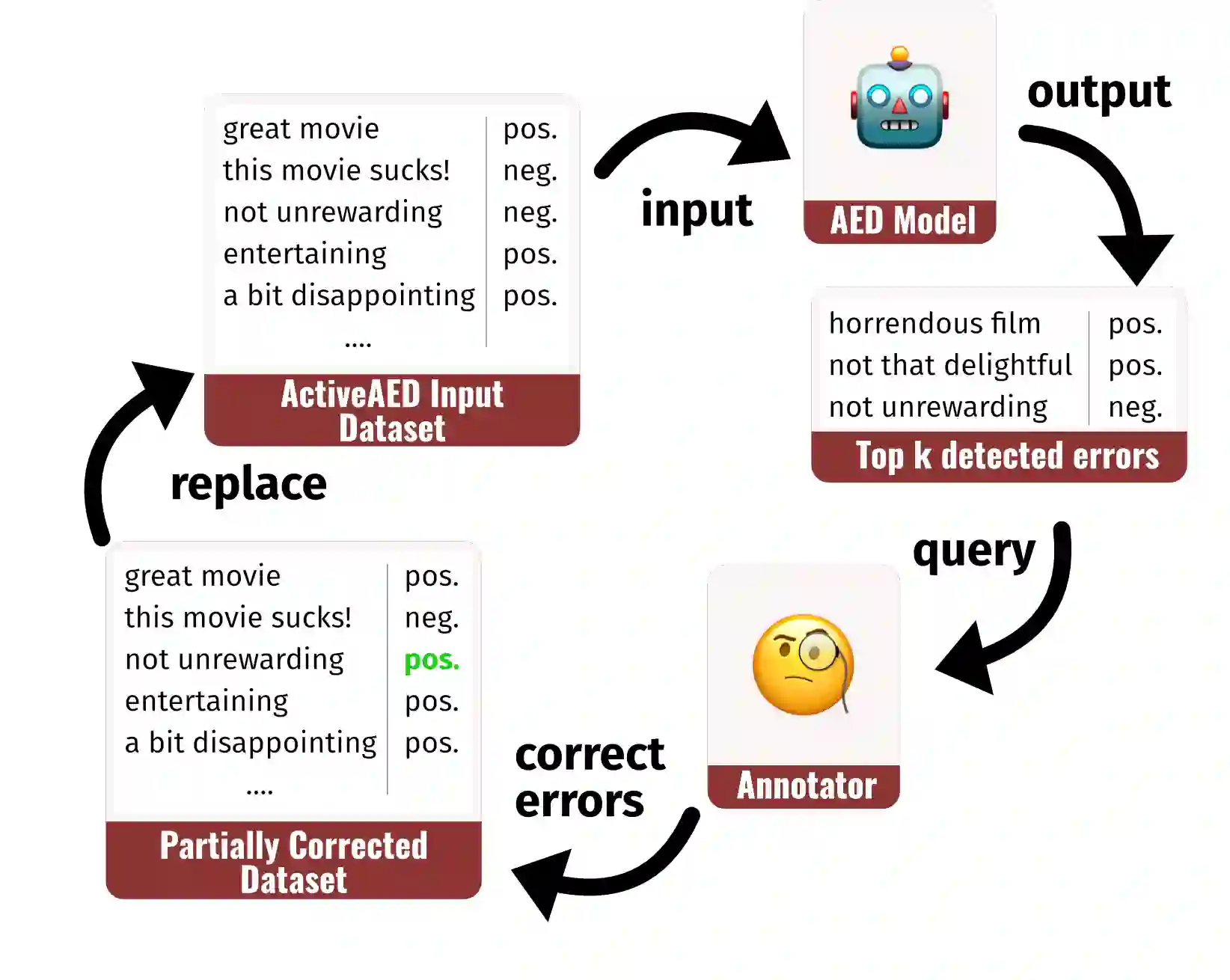
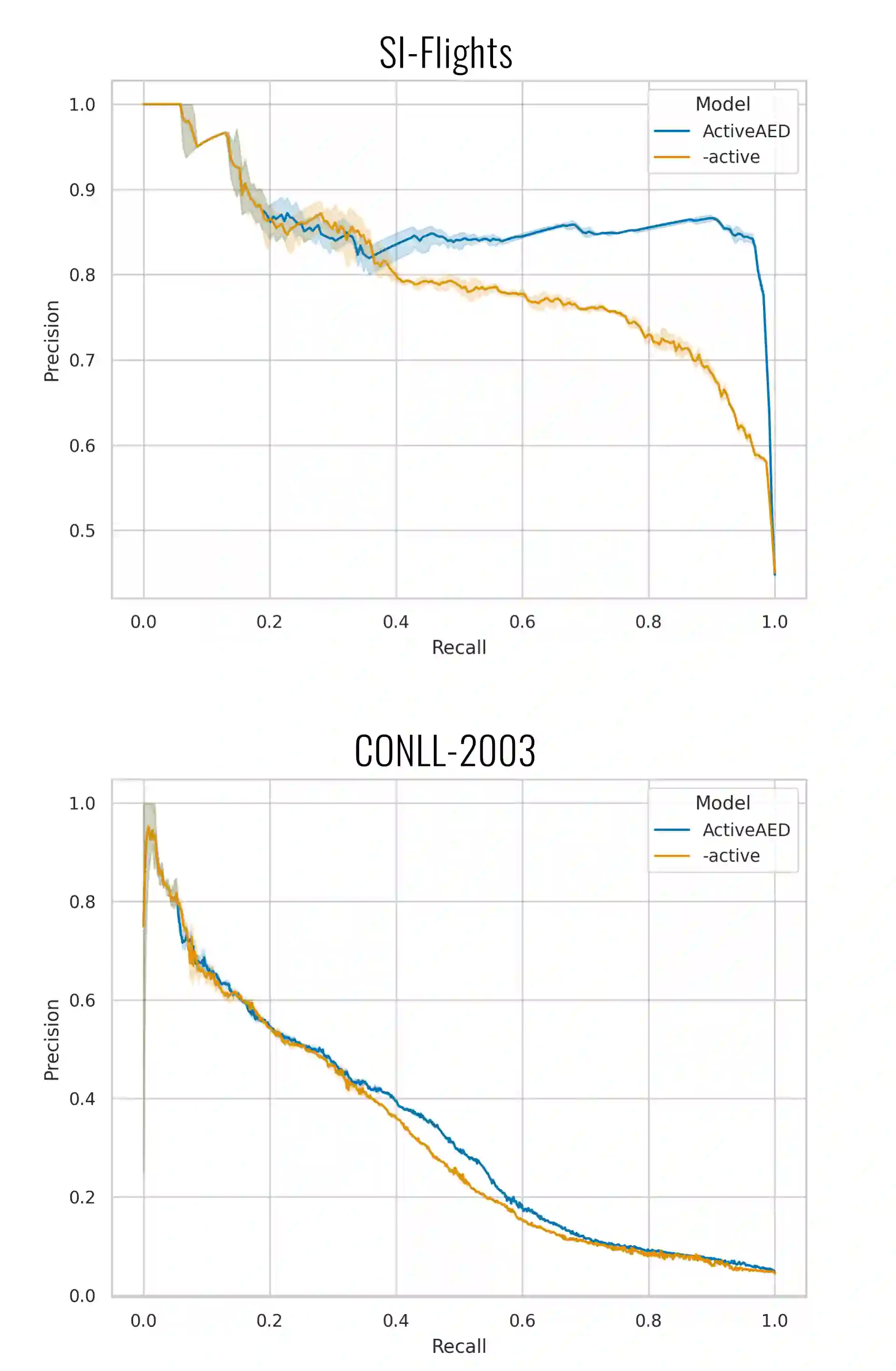
Manually annotated datasets are crucial for training and evaluating Natural Language Processing models. However, recent work has discovered that even widely-used benchmark datasets contain a substantial number of erroneous annotations. This problem has been addressed with Annotation Error Detection (AED) models, which can flag such errors for human re-annotation. However, even though many of these AED methods assume a final curation step in which a human annotator decides whether the annotation is erroneous, they have been developed as static models without any human-in-the-loop component. In this work, we propose ActiveAED, an AED method that can detect errors more accurately by repeatedly querying a human for error corrections in its prediction loop. We evaluate ActiveAED on eight datasets spanning five different tasks and find that it leads to improvements over the state of the art on seven of them, with gains of up to six percentage points in average precision.
翻译:人工标注的数据集对于训练和评估自然语言处理模型至关重要。然而,近期研究发现,即便是广泛使用的基准数据集也包含大量错误标注。针对这一问题,研究者提出了标注错误检测(AED)模型,该模型可标记此类错误以供人工重新标注。然而,尽管许多AED方法假设最终需要人工审核步骤——由标注者判断标注是否存在错误——这些方法仍被开发为不含人在循环组件的静态模型。本研究提出ActiveAED方法,该方法通过在其预测循环中反复向人类查询错误修正,从而更准确地检测错误。我们在涵盖五项任务的八个数据集上评估ActiveAED,发现其在七个数据集上的性能击败了当前最优方法,平均精确率提升高达六个百分点。