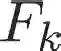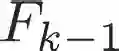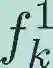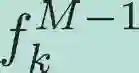The development of artificial intelligence (AI) for science has led to the emergence of learning-based research paradigms, necessitating a compelling reevaluation of the design of multi-objective optimization (MOO) methods. The new generation MOO methods should be rooted in automated learning rather than manual design. In this paper, we introduce a new automatic learning paradigm for optimizing MOO problems, and propose a multi-gradient learning to optimize (ML2O) method, which automatically learns a generator (or mappings) from multiple gradients to update directions. As a learning-based method, ML2O acquires knowledge of local landscapes by leveraging information from the current step and incorporates global experience extracted from historical iteration trajectory data. By introducing a new guarding mechanism, we propose a guarded multi-gradient learning to optimize (GML2O) method, and prove that the iterative sequence generated by GML2O converges to a Pareto critical point. The experimental results demonstrate that our learned optimizer outperforms hand-designed competitors on training multi-task learning (MTL) neural network.
翻译:人工智能(AI)与科学领域的融合发展催生了基于学习的研究范式,这要求我们对多目标优化(MOO)方法的设计进行重新审视。新一代MOO方法应根植于自动化学习而非人工设计。本文提出了一种面向MOO问题的新型自动学习范式,并提出了多梯度学习优化(ML2O)方法,该方法能够自动学习从多个梯度到更新方向的生成器(或映射关系)。作为一种基于学习的方法,ML2O通过利用当前步的局部地形信息,并结合从历史迭代轨迹数据中提取的全局经验来获取知识。通过引入新的保护机制,我们进一步提出了受保护的多梯度学习优化(GML2O)方法,并证明了GML2O生成的迭代序列收敛至帕累托临界点。实验结果表明,我们的学习优化器在训练多任务学习(MTL)神经网络时优于手工设计的竞争方法。