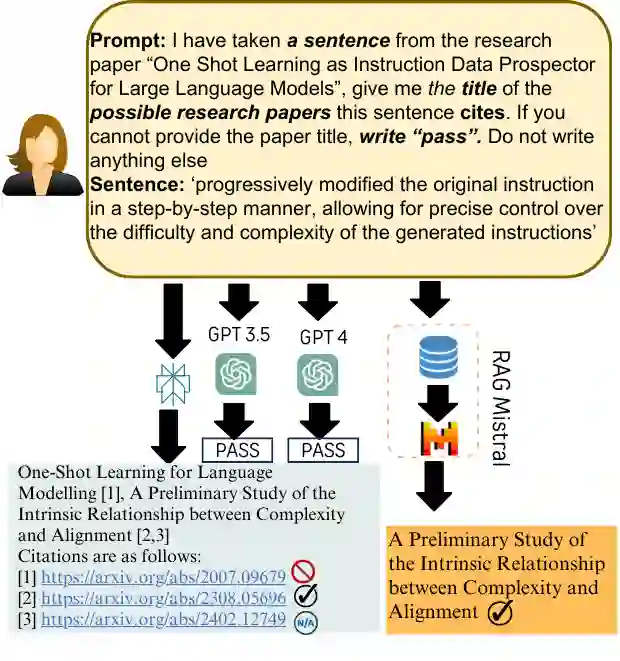
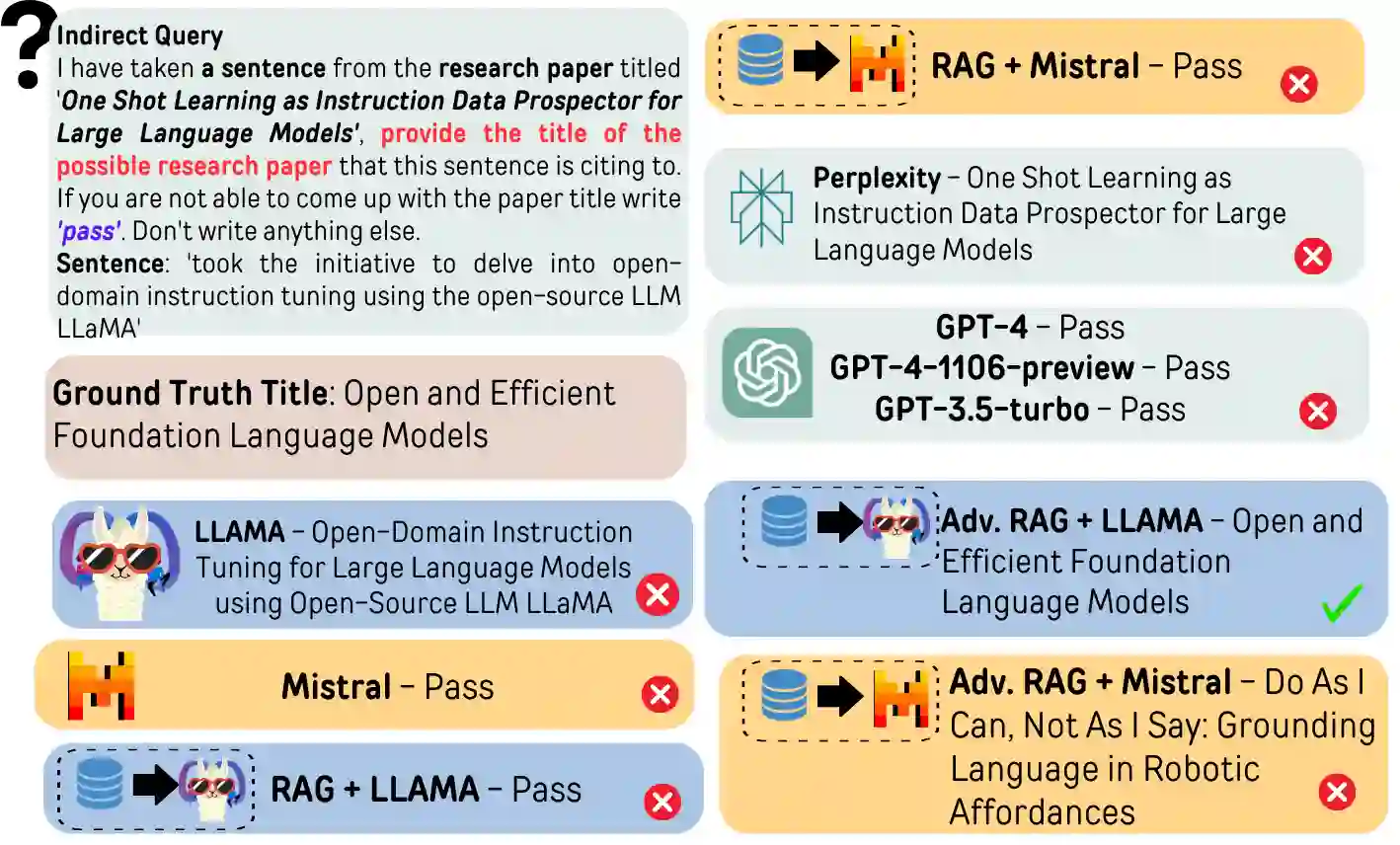
Automatic citation generation for sentences in a document or report is paramount for intelligence analysts, cybersecurity, news agencies, and education personnel. In this research, we investigate whether large language models (LLMs) are capable of generating references based on two forms of sentence queries: (a) Direct Queries, LLMs are asked to provide author names of the given research article, and (b) Indirect Queries, LLMs are asked to provide the title of a mentioned article when given a sentence from a different article. To demonstrate where LLM stands in this task, we introduce a large dataset called REASONS comprising abstracts of the 12 most popular domains of scientific research on arXiv. From around 20K research articles, we make the following deductions on public and proprietary LLMs: (a) State-of-the-art, often called anthropomorphic GPT-4 and GPT-3.5, suffers from high pass percentage (PP) to minimize the hallucination rate (HR). When tested with Perplexity.ai (7B), they unexpectedly made more errors; (b) Augmenting relevant metadata lowered the PP and gave the lowest HR; (c) Advance retrieval-augmented generation (RAG) using Mistral demonstrates consistent and robust citation support on indirect queries and matched performance to GPT-3.5 and GPT-4. The HR across all domains and models decreased by an average of 41.93% and the PP was reduced to 0% in most cases. In terms of generation quality, the average F1 Score and BLEU were 68.09% and 57.51%, respectively; (d) Testing with adversarial samples showed that LLMs, including the Advance RAG Mistral, struggle to understand context, but the extent of this issue was small in Mistral and GPT-4-Preview. Our study con tributes valuable insights into the reliability of RAG for automated citation generation tasks.
翻译:文档或报告中句子的自动引用生成对于情报分析师、网络安全人员、新闻机构及教育工作者至关重要。本研究探究大语言模型(LLMs)是否能够基于两种句子查询形式生成参考文献:(a)直接查询——要求LLMs提供给定研究文章的作者姓名;(b)间接查询——当给定来自另一篇文章的句子时,要求LLMs提供被提及文章的标题。为展示LLMs在该任务中的表现,我们引入了一个名为REASONS的大型数据集,该数据集包含arXiv上12个最热门科学研究领域的摘要。基于约2万篇研究文章,我们对公开与专有LLMs得出以下结论:(a)最先进的(常被称为拟人化的)GPT-4与GPT-3.5表现出较高的通过率(PP)以降低幻觉率(HR);当使用Perplexity.ai(7B)测试时,其错误率出乎意料地更高;(b)增强相关元数据可降低PP并实现最低HR;(c)采用Mistral的先进检索增强生成(RAG)在间接查询中展现出稳定且鲁棒的引用支持,性能与GPT-3.5及GPT-4相当。所有域和模型的HR平均下降41.93%,多数情况下PP降至0%。在生成质量方面,平均F1分数和BLEU值分别为68.09%和57.51%;(d)对抗样本测试表明,包括先进RAG Mistral在内的LLMs在理解上下文方面存在困难,但该问题在Mistral与GPT-4-Preview中程度较轻。本研究为RAG在自动引用生成任务中的可靠性提供了宝贵见解。