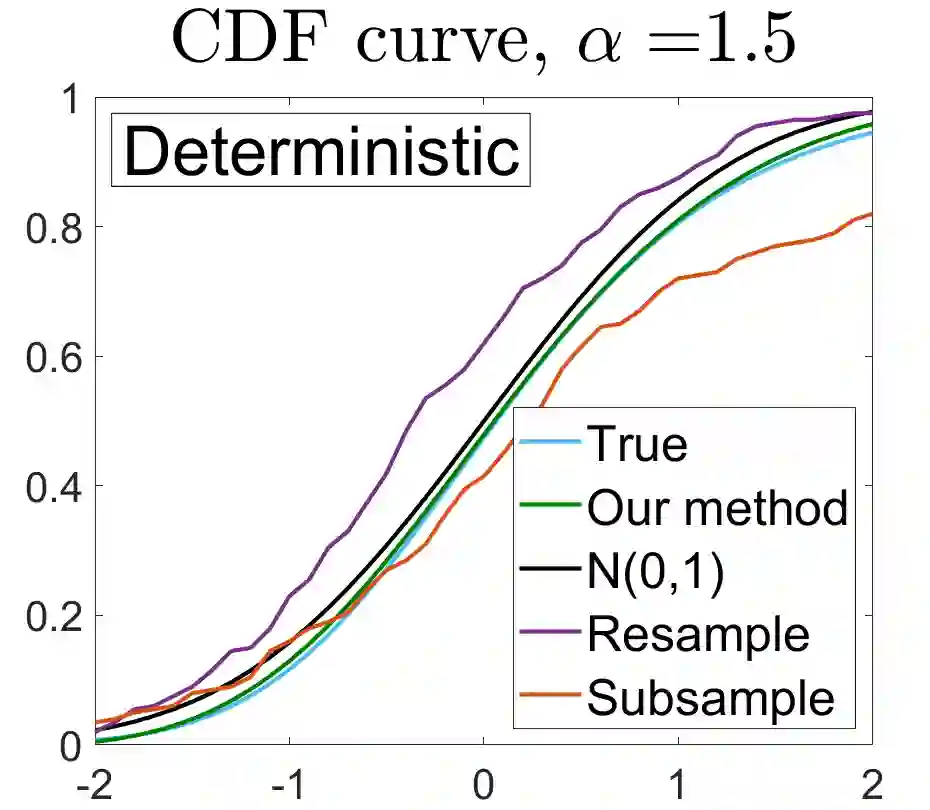
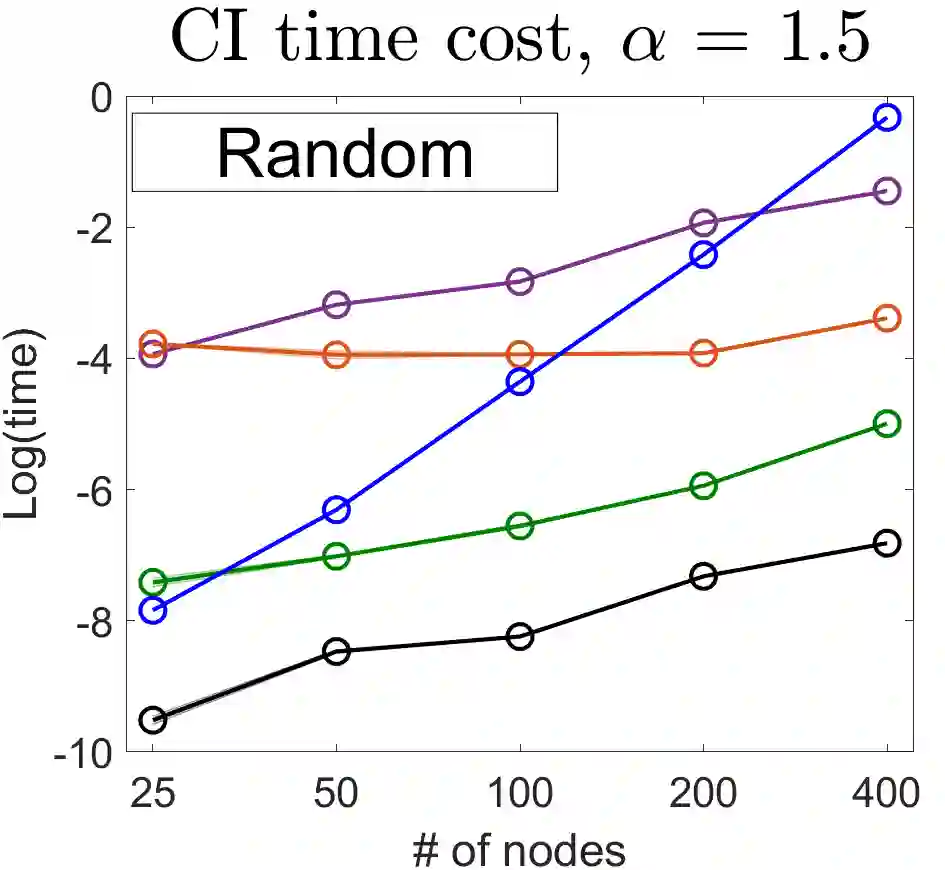
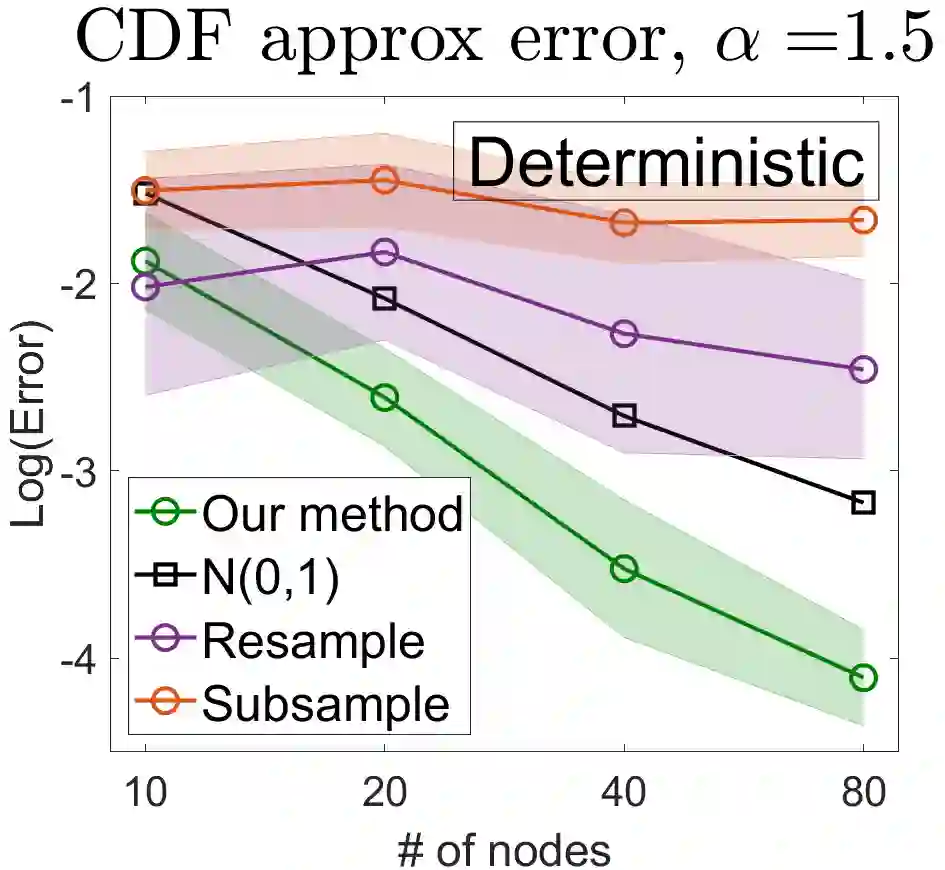
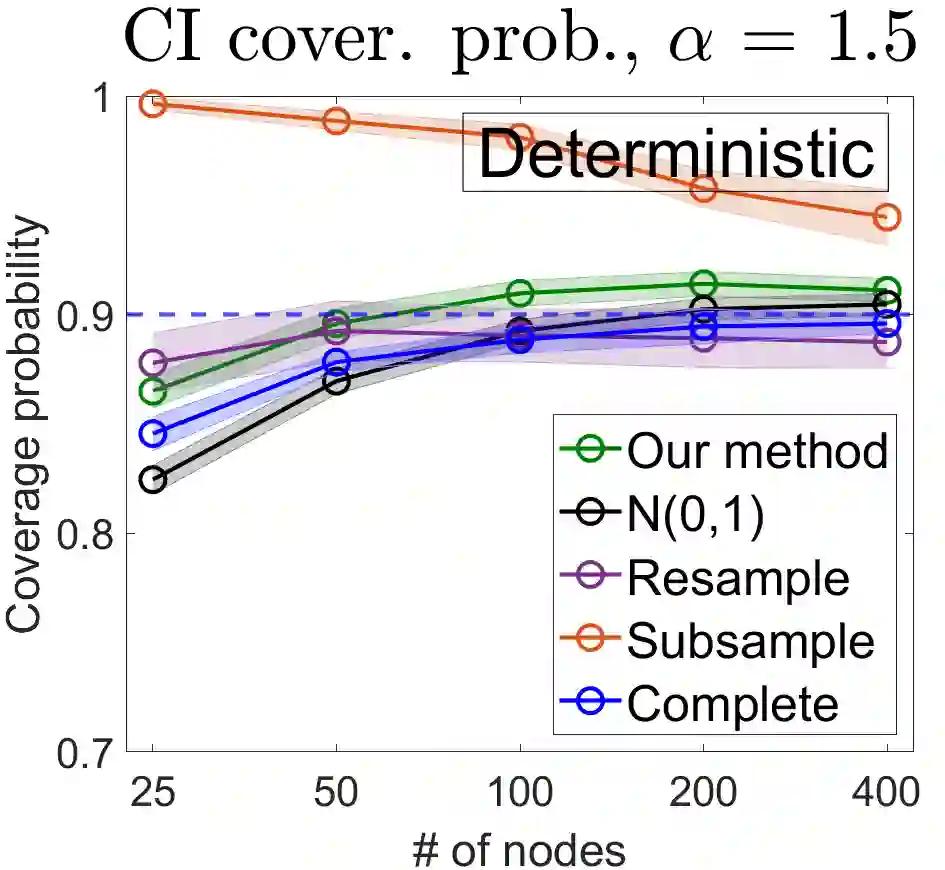
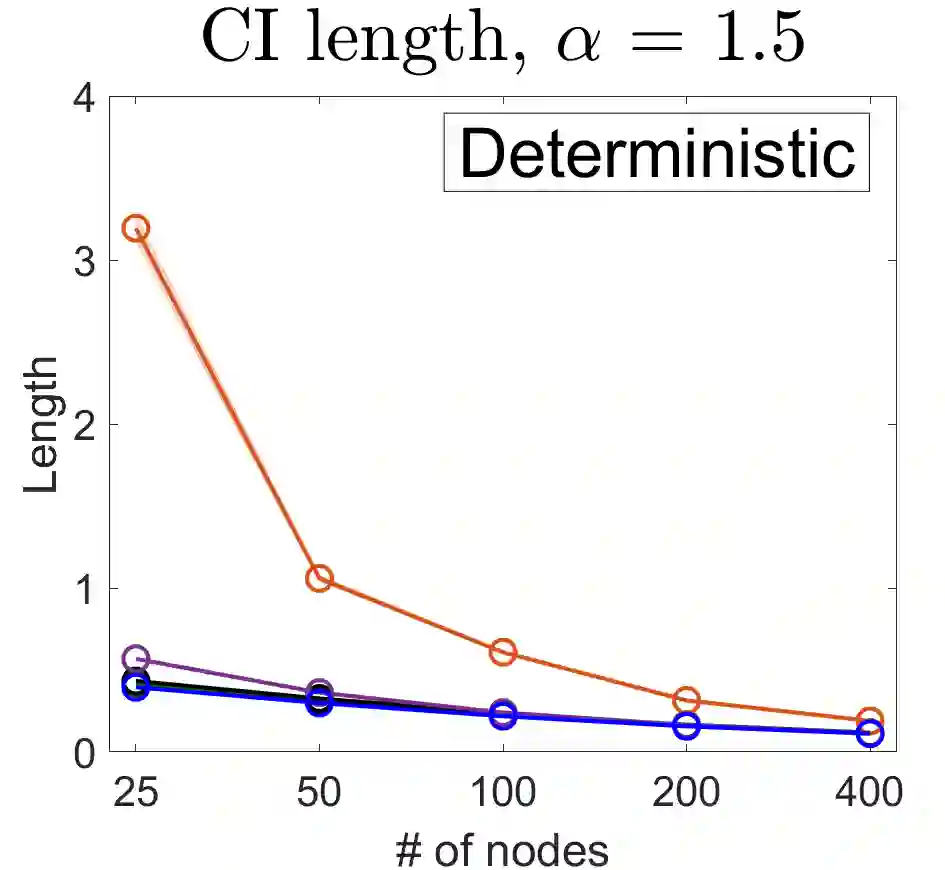
U-statistics play central roles in many statistical learning tools but face the haunting issue of scalability. Significant efforts have been devoted into accelerating computation by U-statistic reduction. However, existing results almost exclusively focus on power analysis, while little work addresses risk control accuracy -- comparatively, the latter requires distinct and much more challenging techniques. In this paper, we establish the first statistical inference procedure with provably higher-order accurate risk control for incomplete U-statistics. The sharpness of our new result enables us to reveal how risk control accuracy also trades off with speed for the first time in literature, which complements the well-known variance-speed trade-off. Our proposed general framework converts the long-standing challenge of formulating accurate statistical inference procedures for many different designs into a surprisingly routine task. This paper covers non-degenerate and degenerate U-statistics, and network moments. We conducted comprehensive numerical studies and observed results that validate our theory's sharpness. Our method also demonstrates effectiveness on real-world data applications.
翻译:U-统计量在许多统计学习工具中扮演着核心角色,但面临可扩展性这一棘手问题。已有大量研究致力于通过U-统计量约简来加速计算。然而,现有结果几乎完全集中于功效分析,而很少涉及风险控制精度——相比之下,后者需要截然不同且更具挑战性的技术。在本文中,我们建立了首个针对非完全U-统计量具有可证明高阶精确风险控制的统计推断程序。我们新结果的精确性使我们能够首次在文献中揭示风险控制精度如何与速度进行权衡,从而补充了众所周知的方差-速度权衡。我们提出的通用框架将针对多种不同设计构建精确统计推断程序这一长期挑战,转化为一项出奇常规的任务。本文涵盖非退化与退化U-统计量,以及网络矩。我们进行了全面的数值研究,观察到的结果验证了我们理论的精确性。我们的方法在真实世界数据应用中也展现了有效性。