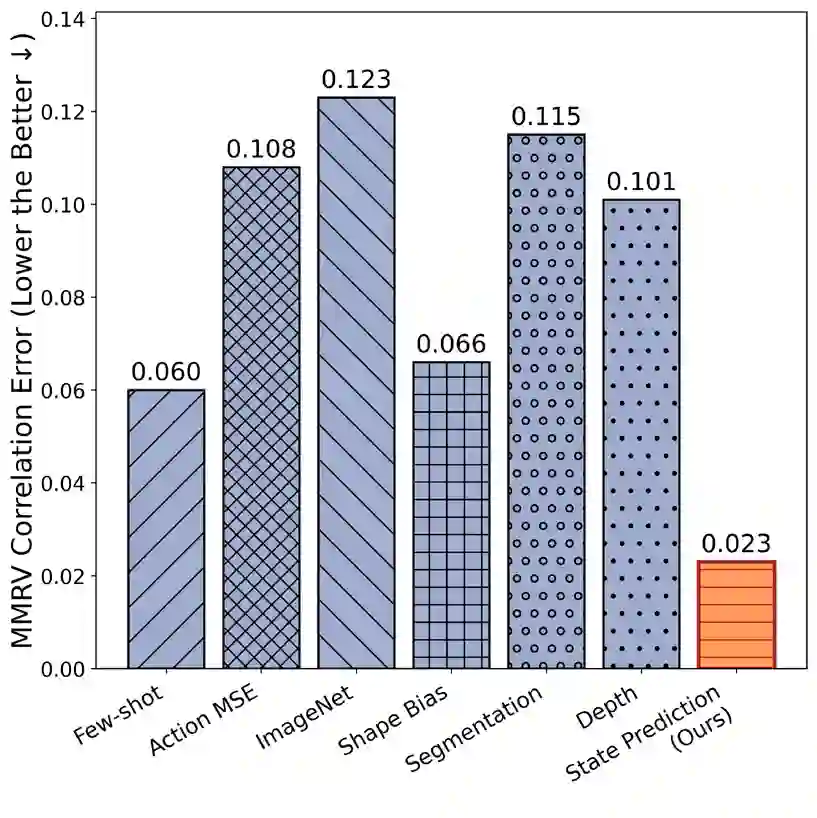
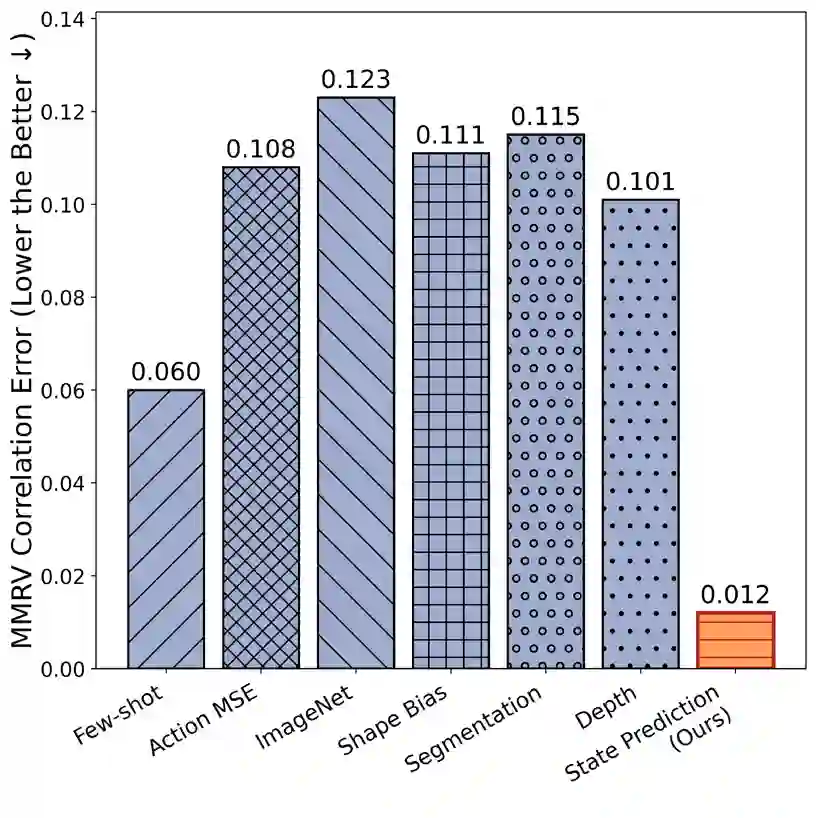
The choice of visual representation is key to scaling generalist robot policies. However, direct evaluation via policy rollouts is expensive, even in simulation. Existing proxy metrics focus on the representation's capacity to capture narrow aspects of the visual world, like object shape, limiting generalization across environments. In this paper, we take an analytical perspective: we probe pretrained visual encoders by measuring how well they support decoding of environment state -- including geometry, object structure, and physical attributes -- from images. Leveraging simulation environments with access to ground-truth state, we show that this probing accuracy strongly correlates with downstream policy performance across diverse environments and learning settings, significantly outperforming prior metrics and enabling efficient representation selection. More broadly, our study provides insight into the representational properties that support generalizable manipulation, suggesting that learning to encode the latent physical state of the environment is a promising objective for control.
翻译:视觉表征的选择对于扩展通用机器人策略至关重要。然而,即使是在仿真环境中,通过策略部署进行直接评估的成本也十分高昂。现有的代理指标主要关注表征捕捉视觉世界局部特征(如物体形状)的能力,这限制了其在不同环境间的泛化能力。本文采用分析视角:我们通过测量预训练视觉编码器从图像中解码环境状态(包括几何结构、物体结构和物理属性)的能力来探究其特性。利用能够获取真实状态数据的仿真环境,我们证明这种探测精度与多种环境和学习设置下的下游策略性能高度相关,显著优于现有指标,并实现了高效的表征选择。更广泛而言,我们的研究揭示了支持可泛化操作的表示特性,表明学习编码环境的潜在物理状态是实现控制的一个有前景的目标。