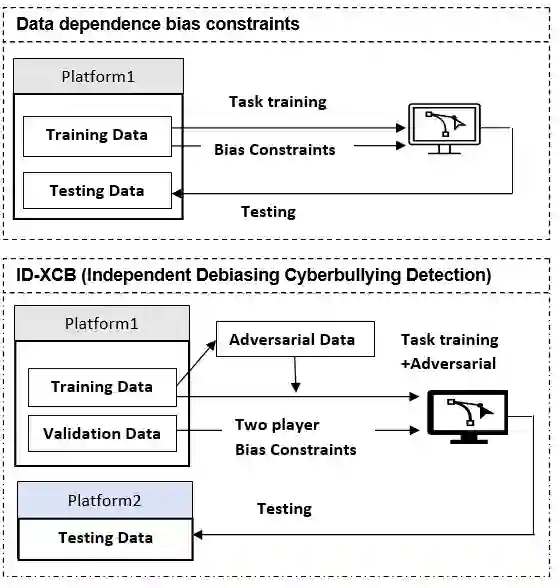
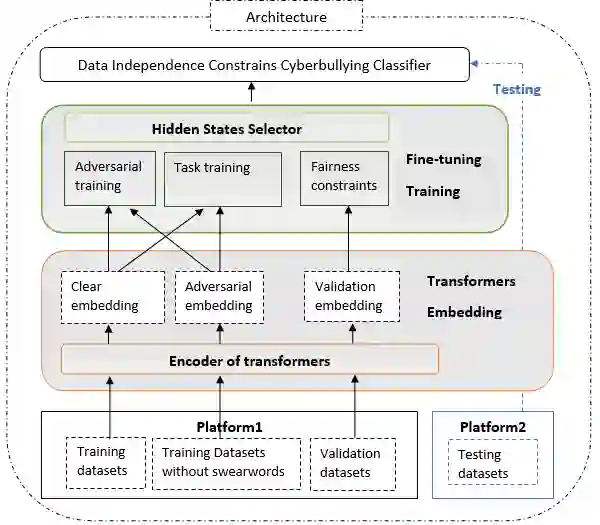
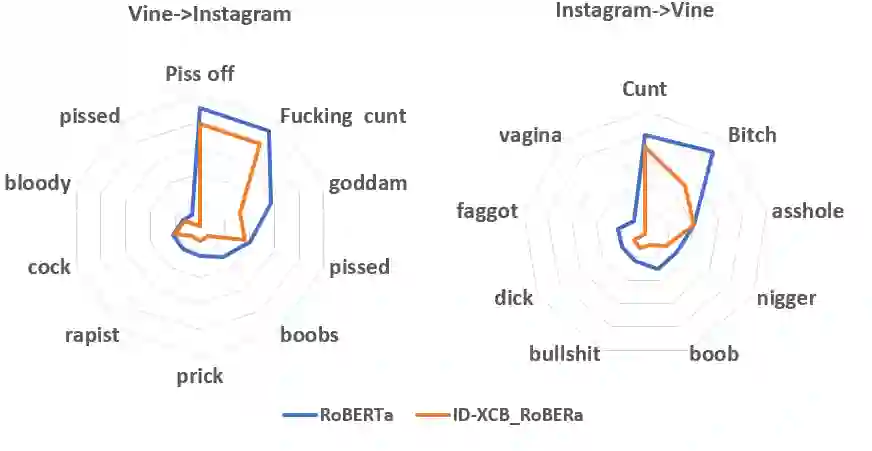
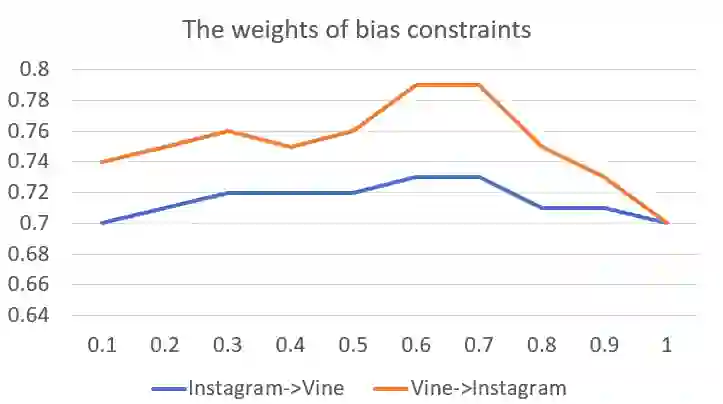
Swear words are a common proxy to collect datasets with cyberbullying incidents. Our focus is on measuring and mitigating biases derived from spurious associations between swear words and incidents occurring as a result of such data collection strategies. After demonstrating and quantifying these biases, we introduce ID-XCB, the first data-independent debiasing technique that combines adversarial training, bias constraints and debias fine-tuning approach aimed at alleviating model attention to bias-inducing words without impacting overall model performance. We explore ID-XCB on two popular session-based cyberbullying datasets along with comprehensive ablation and generalisation studies. We show that ID-XCB learns robust cyberbullying detection capabilities while mitigating biases, outperforming state-of-the-art debiasing methods in both performance and bias mitigation. Our quantitative and qualitative analyses demonstrate its generalisability to unseen data.
翻译:摘要:脏话常被用作收集网络欺凌事件数据的代理指标。我们聚焦于测量和减轻因这种数据收集策略导致的脏话与事件之间虚假关联所产生的偏差。在证明并量化这些偏差后,我们提出ID-XCB——首种数据无关的去偏技术,该技术结合了对抗训练、偏差约束与去偏微调方法,旨在减轻模型对引发偏差词的注意力而不影响整体性能。我们在两个流行的基于会话的网络欺凌数据集上评估ID-XCB,并开展全面的消融实验与泛化研究。结果表明,ID-XCB能在缓解偏差的同时学习鲁棒的网络欺凌检测能力,在性能与偏差减轻两方面均优于最先进的去偏方法。我们的定量与定性分析证明了其对未见数据的泛化能力。