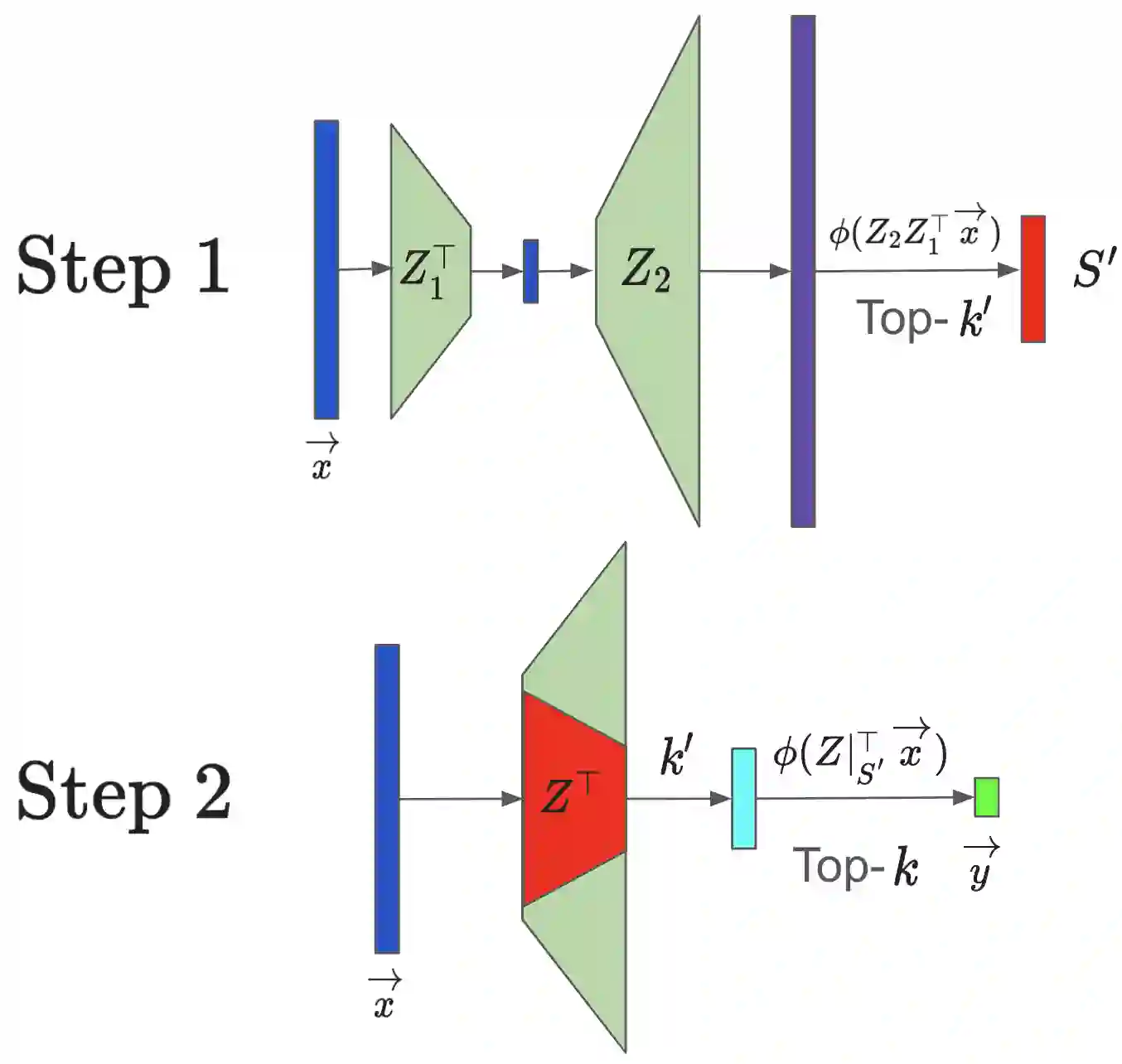
Autoregressive decoding with generative Large Language Models (LLMs) on accelerators (GPUs/TPUs) is often memory-bound where most of the time is spent on transferring model parameters from high bandwidth memory (HBM) to cache. On the other hand, recent works show that LLMs can maintain quality with significant sparsity/redundancy in the feedforward (FFN) layers by appropriately training the model to operate on a top-$k$ fraction of rows/columns (where $k \approx 0.05$), there by suggesting a way to reduce the transfer of model parameters, and hence latency. However, exploiting this sparsity for improving latency is hindered by the fact that identifying top rows/columns is data-dependent and is usually performed using full matrix operations, severely limiting potential gains. To address these issues, we introduce HiRE (High Recall Approximate Top-k Estimation). HiRE comprises of two novel components: (i) a compression scheme to cheaply predict top-$k$ rows/columns with high recall, followed by full computation restricted to the predicted subset, and (ii) DA-TOP-$k$: an efficient multi-device approximate top-$k$ operator. We demonstrate that on a one billion parameter model, HiRE applied to both the softmax as well as feedforward layers, achieves almost matching pretraining and downstream accuracy, and speeds up inference latency by $1.47\times$ on a single TPUv5e device.
翻译:摘要:在加速器(GPU/TPU)上使用生成式大语言模型进行自回归解码时,通常受限于内存带宽——大部分时间用于将模型参数从高带宽内存传输至缓存。另一方面,近期研究表明,通过适当训练使模型仅操作前馈层中前$k$%的行/列(其中$k \approx 0.05$),大语言模型能够在保持质量的同时实现显著的稀疏性/冗余性,从而提供一种减少模型参数传输量、进而降低延迟的途径。然而,由于识别前$k$行/列的过程依赖于具体数据,且通常需通过完整矩阵运算实现,这严重限制了潜在加速收益,导致难以利用这种稀疏性来改善延迟。针对这些问题,我们提出HiRE(高召回近似Top-$k$估计)。HiRE包含两个新颖组件:(i)一种压缩方案,以高召回率低成本预测前$k$行/列,随后仅对预测子集进行完整计算;(ii)DA-TOP-$k$:一种高效的多设备近似Top-$k$算子。实验表明,在十亿参数规模模型上,将HiRE同时应用于软最大层和前馈层,可达到几乎匹配的预训练与下游任务精度,并在单个TPUv5e设备上实现$1.47\times$的推理加速。