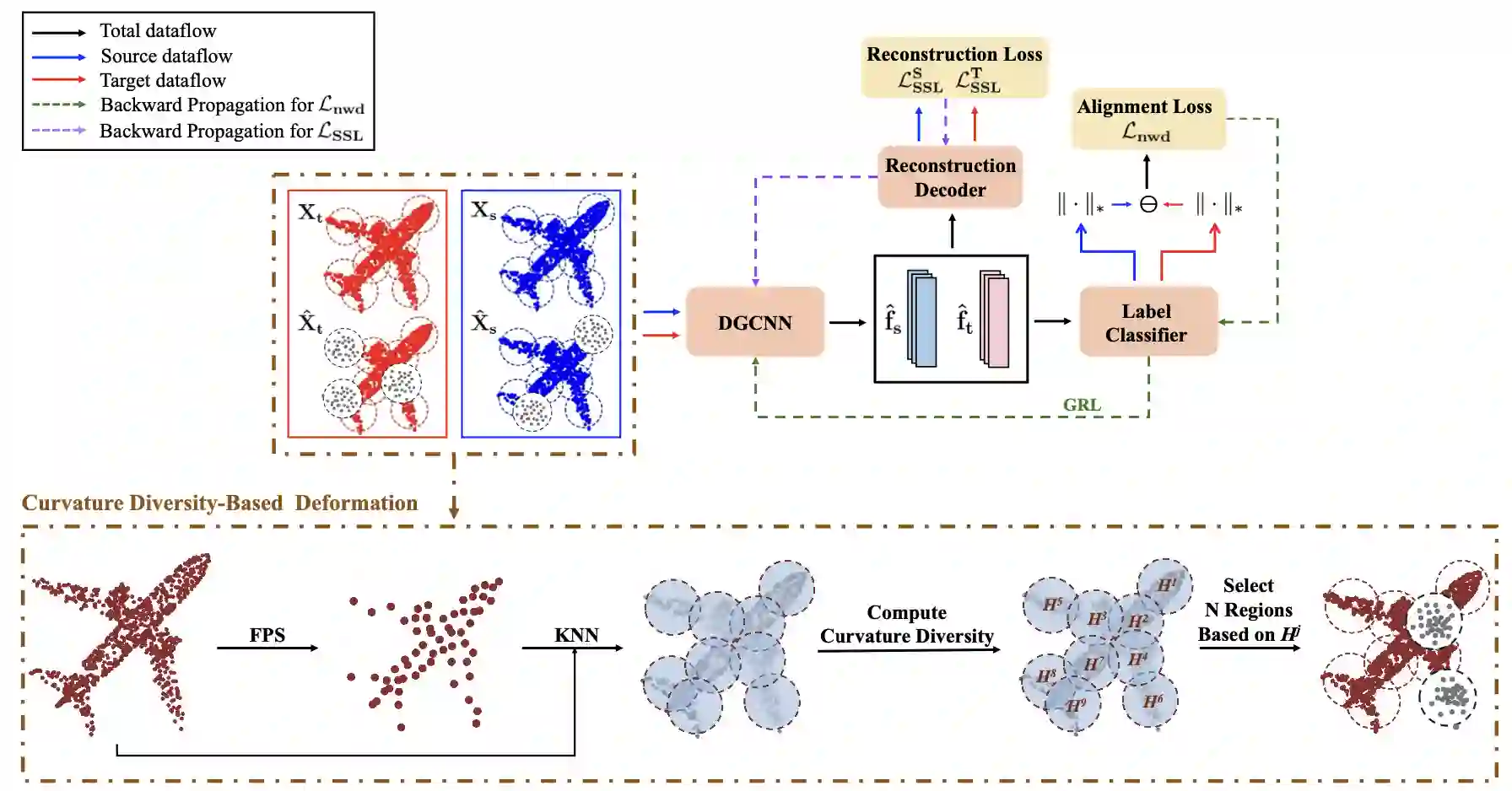
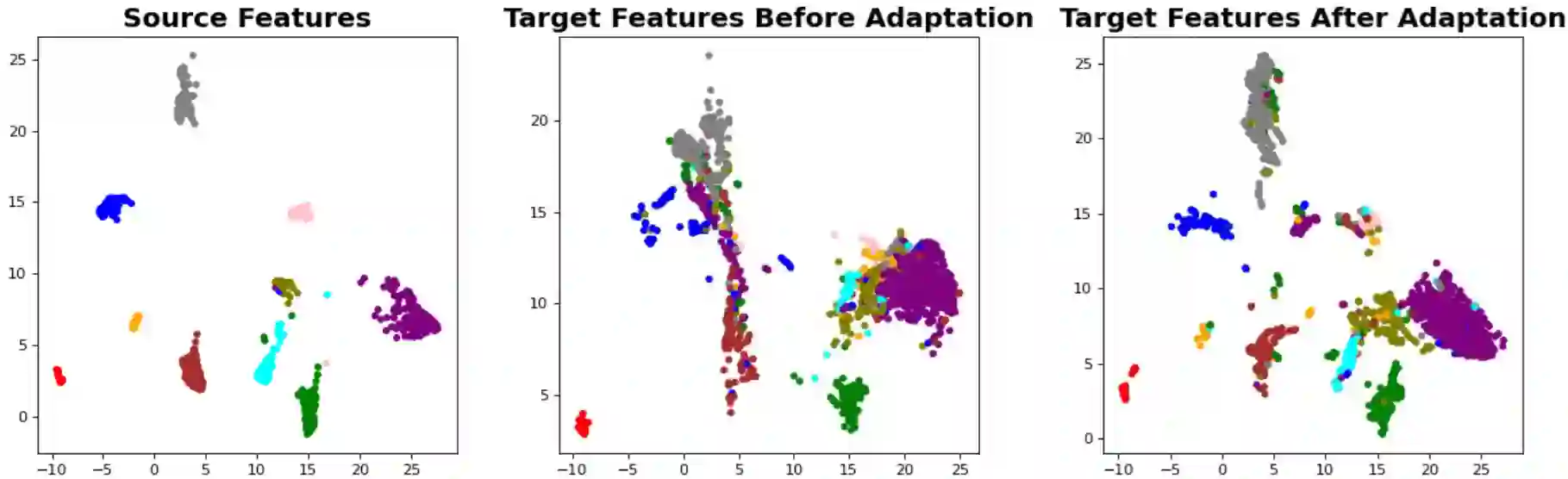
Unsupervised Domain Adaptation (UDA) is crucial for reducing the need for extensive manual data annotation when training deep networks on point cloud data. A significant challenge of UDA lies in effectively bridging the domain gap. To tackle this challenge, we propose \textbf{C}urvature \textbf{D}iversity-Driven \textbf{N}uclear-Norm Wasserstein \textbf{D}omain Alignment (CDND). Our approach first introduces a \textit{\textbf{Curv}ature Diversity-driven Deformation \textbf{Rec}onstruction (CurvRec)} task, which effectively mitigates the gap between the source and target domains by enabling the model to extract salient features from semantically rich regions of a given point cloud. We then propose \textit{\textbf{D}eformation-based \textbf{N}uclear-norm \textbf{W}asserstein \textbf{D}iscrepancy (D-NWD)}, which applies the Nuclear-norm Wasserstein Discrepancy to both \textit{deformed and original} data samples to align the source and target domains. Furthermore, we contribute a theoretical justification for the effectiveness of D-NWD in distribution alignment and demonstrate that it is \textit{generic} enough to be applied to \textbf{any} deformations. To validate our method, we conduct extensive experiments on two public domain adaptation datasets for point cloud classification and segmentation tasks. Empirical experiment results show that our CDND achieves state-of-the-art performance by a noticeable margin over existing approaches.
翻译:无监督域适应(UDA)对于减少点云数据训练深度网络时对大量人工标注的依赖至关重要。UDA的一个主要挑战在于有效弥合域间差异。为解决这一挑战,我们提出了**曲率多样性驱动的核范数Wasserstein域对齐**(CDND)。我们的方法首先引入一个**曲率多样性驱动的形变重建**(CurvRec)任务,该任务通过使模型能够从给定点云的语义丰富区域提取显著特征,有效缓解源域与目标域之间的差异。随后,我们提出**基于形变的核范数Wasserstein差异**(D-NWD),将核范数Wasserstein差异应用于**形变后与原始**数据样本,以实现源域与目标域的对齐。此外,我们从理论上论证了D-NWD在分布对齐中的有效性,并证明其具有足够的**普适性**,可应用于**任意**形变方法。为验证所提方法,我们在两个公开的点云分类与分割域适应数据集上进行了大量实验。实证结果表明,我们的CDND方法以显著优势超越了现有方法,达到了最先进的性能水平。