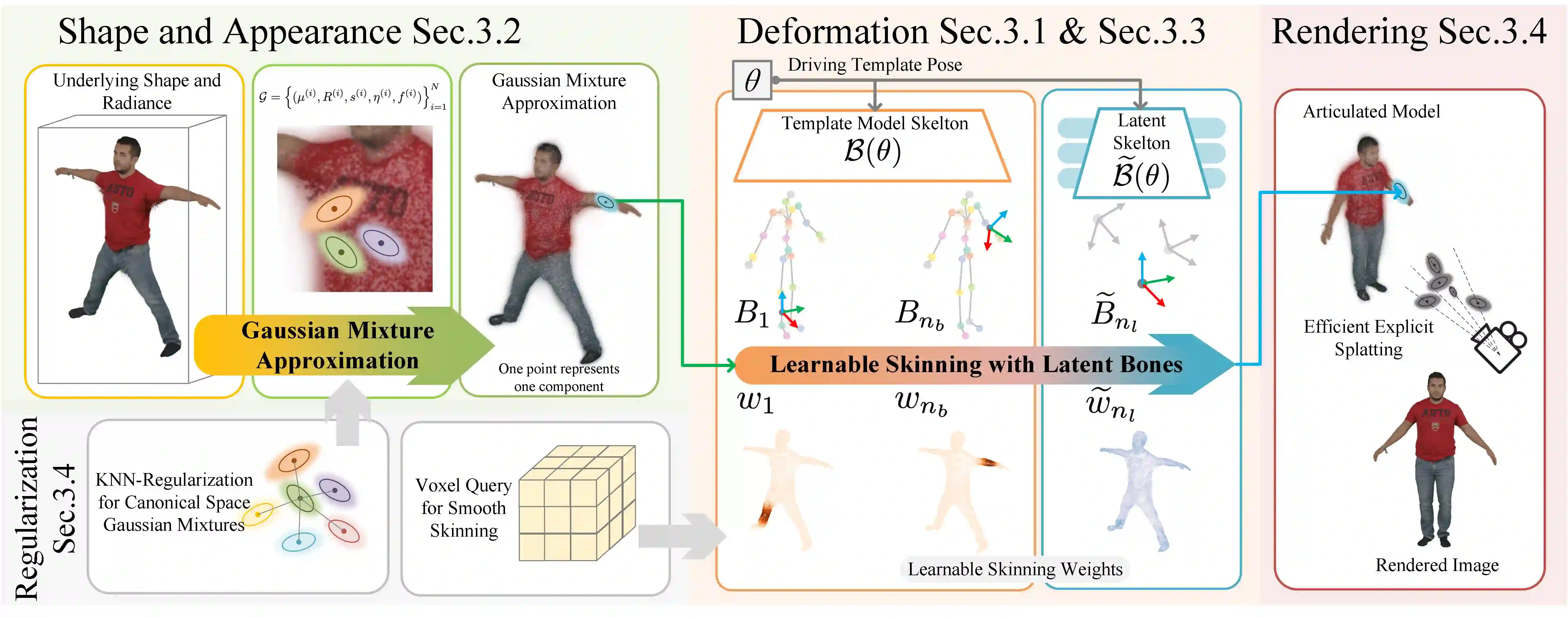
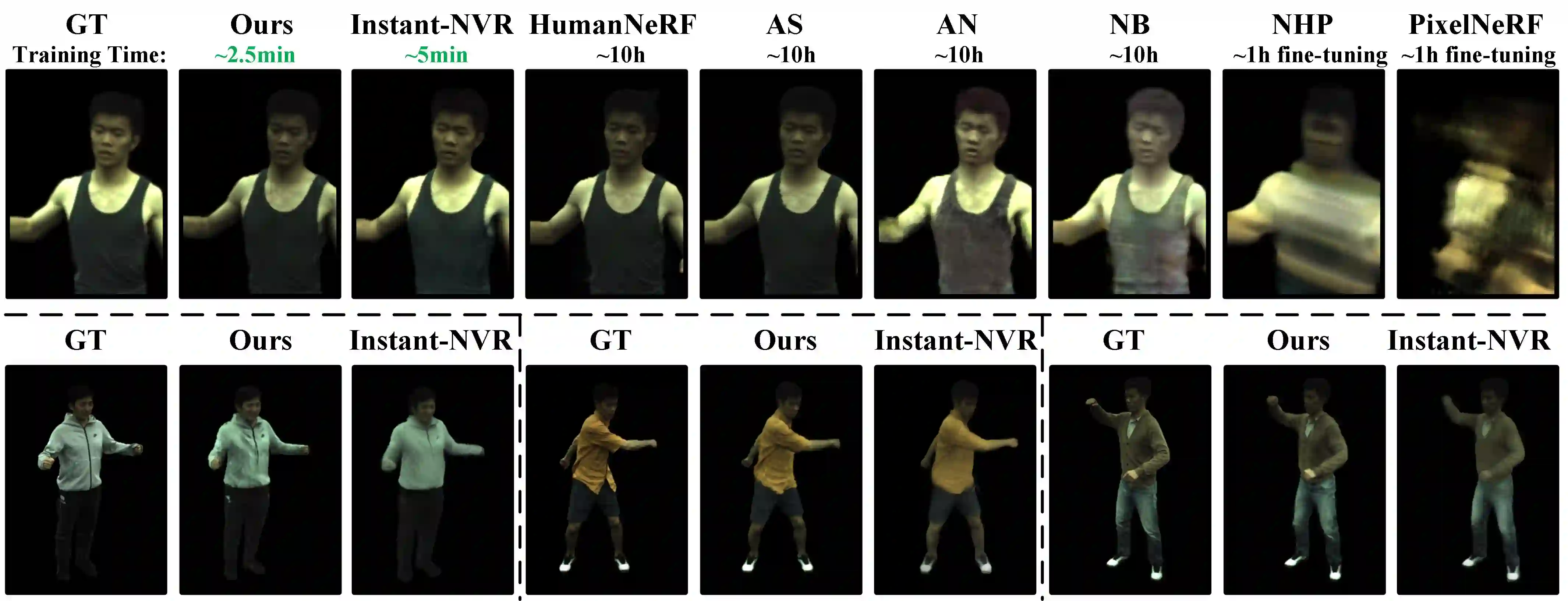
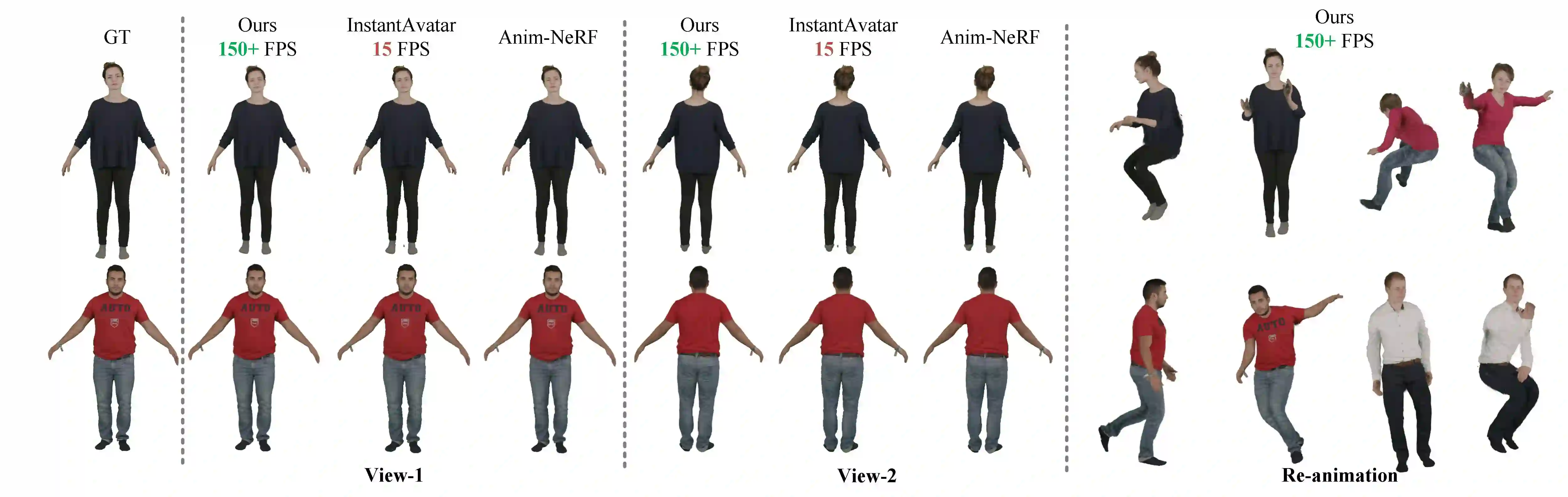
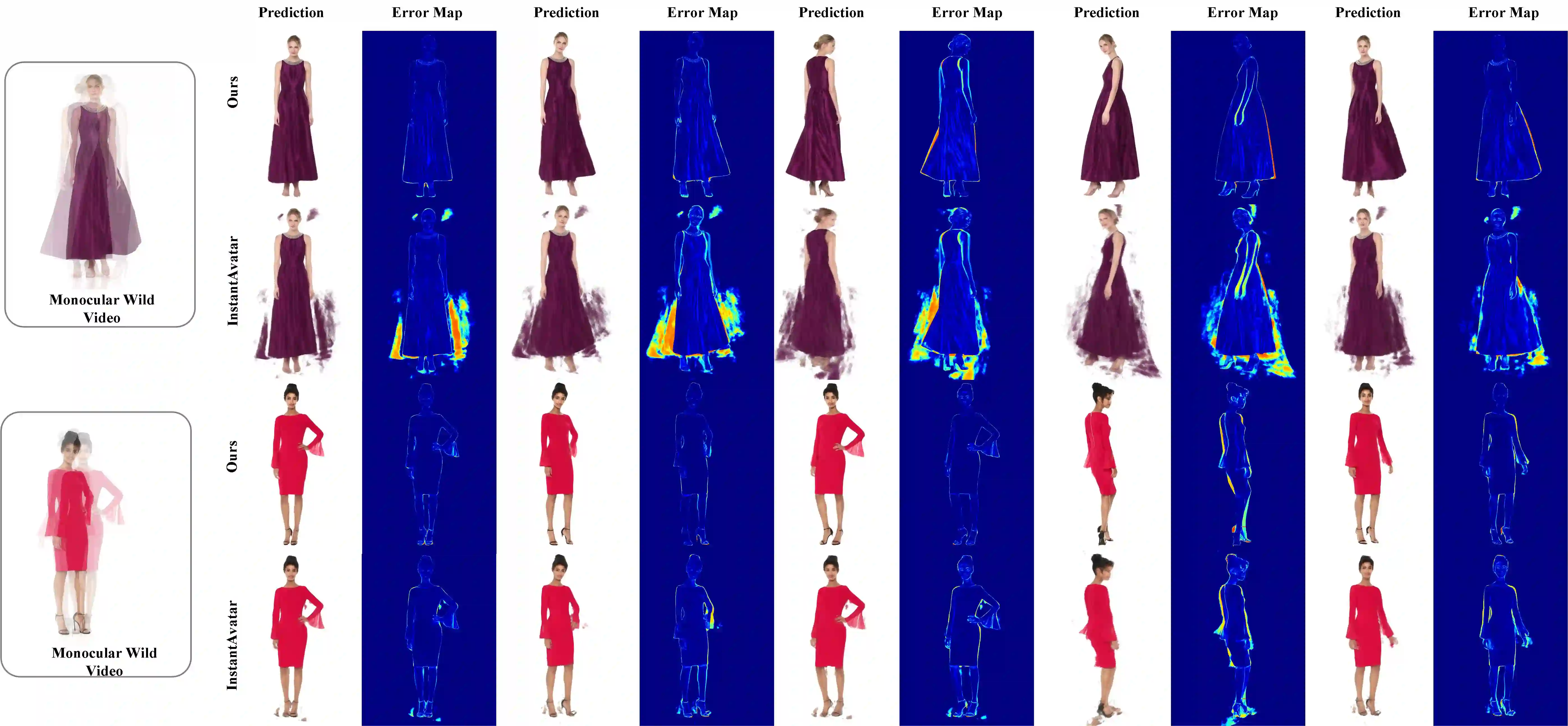
We introduce Gaussian Articulated Template Model GART, an explicit, efficient, and expressive representation for non-rigid articulated subject capturing and rendering from monocular videos. GART utilizes a mixture of moving 3D Gaussians to explicitly approximate a deformable subject's geometry and appearance. It takes advantage of a categorical template model prior (SMPL, SMAL, etc.) with learnable forward skinning while further generalizing to more complex non-rigid deformations with novel latent bones. GART can be reconstructed via differentiable rendering from monocular videos in seconds or minutes and rendered in novel poses faster than 150fps.
翻译:我们提出高斯关节模板模型GART,这是一类用于从单目视频捕捉和渲染非刚性关节对象的显式、高效且富有表现力的表示方法。GART利用移动三维高斯混合模型显式近似可变形对象的几何与外观,借助带有可学习前向蒙皮技术的类别模板模型先验(如SMPL、SMAL等),并通过新颖的潜骨骼进一步推广至更复杂的非刚性变形。GART可在数秒至数分钟内通过单目视频的可微渲染完成重建,并以超过150fps的帧率生成新姿态下的渲染结果。