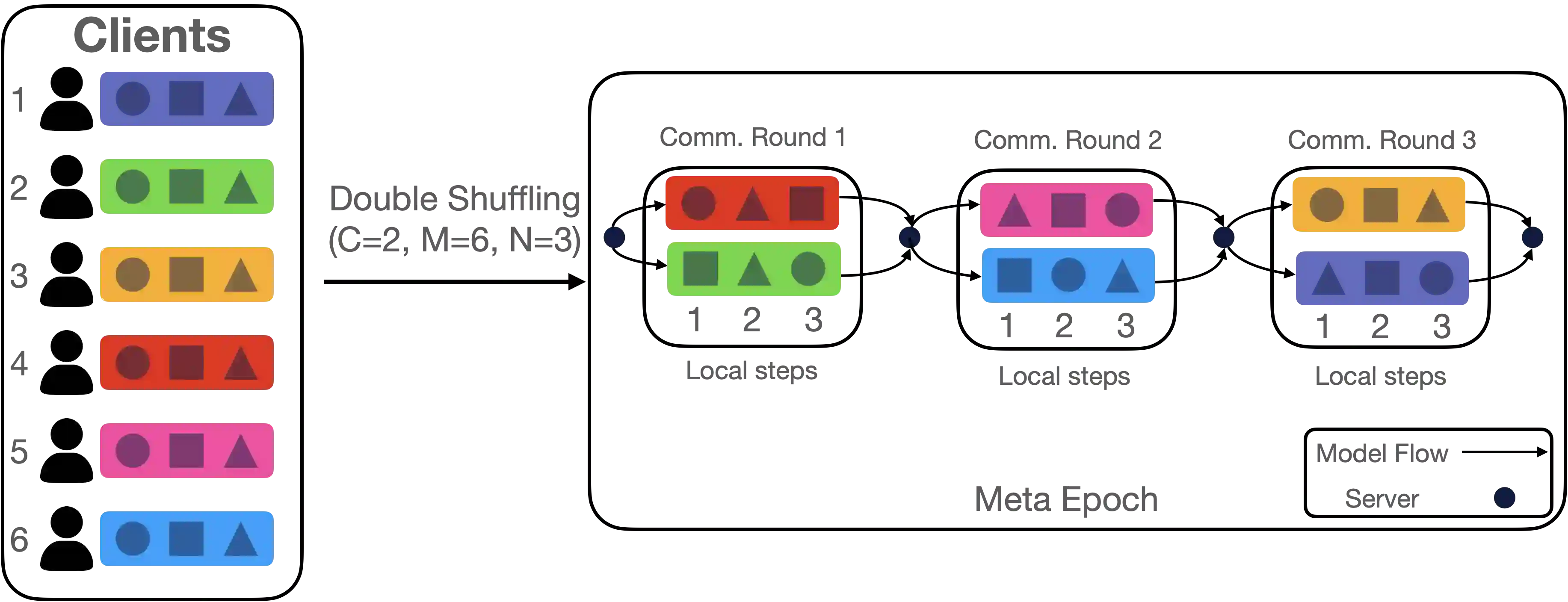
Federated Learning (FL) is a distributed machine learning approach where multiple clients work together to solve a machine learning task. One of the key challenges in FL is the issue of partial participation, which occurs when a large number of clients are involved in the training process. The traditional method to address this problem is randomly selecting a subset of clients at each communication round. In our research, we propose a new technique and design a novel regularized client participation scheme. Under this scheme, each client joins the learning process every $R$ communication rounds, which we refer to as a meta epoch. We have found that this participation scheme leads to a reduction in the variance caused by client sampling. Combined with the popular FedAvg algorithm (McMahan et al., 2017), it results in superior rates under standard assumptions. For instance, the optimization term in our main convergence bound decreases linearly with the product of the number of communication rounds and the size of the local dataset of each client, and the statistical term scales with step size quadratically instead of linearly (the case for client sampling with replacement), leading to better convergence rate $\mathcal{O}\left(\frac{1}{T^2}\right)$ compared to $\mathcal{O}\left(\frac{1}{T}\right)$, where $T$ is the total number of communication rounds. Furthermore, our results permit arbitrary client availability as long as each client is available for training once per each meta epoch.
翻译:联邦学习(FL)是一种分布式机器学习方法,允许多个客户端协同解决机器学习任务。联邦学习的关键挑战之一是部分参与问题,即当大量客户端参与训练过程时出现的情况。解决该问题的传统方法是在每轮通信中随机选取一个客户端子集。本研究提出了一种新技术,设计了一种新颖的规则化客户端参与方案。在该方案下,每个客户端每隔$R$轮通信(称为元周期)加入学习过程。我们发现,这一参与方案能够降低因客户端采样引起的方差。当与流行的FedAvg算法(McMahan等人,2017年)结合时,该方案在标准假设下实现了更优的收敛速率。例如,我们主要收敛界中的优化项随通信轮次与各客户端本地数据集的乘积线性递减,而统计项则按步长的二次方而非线性关系(即替换采样的案例)缩放,从而得到比$\mathcal{O}\left(\frac{1}{T}\right)$更优的收敛速率$\mathcal{O}\left(\frac{1}{T^2}\right)$,其中$T$为总通信轮次。此外,只要每个客户端在每个元周期内至少参与一次训练,我们的结果即可适用于任意客户端可用性场景。