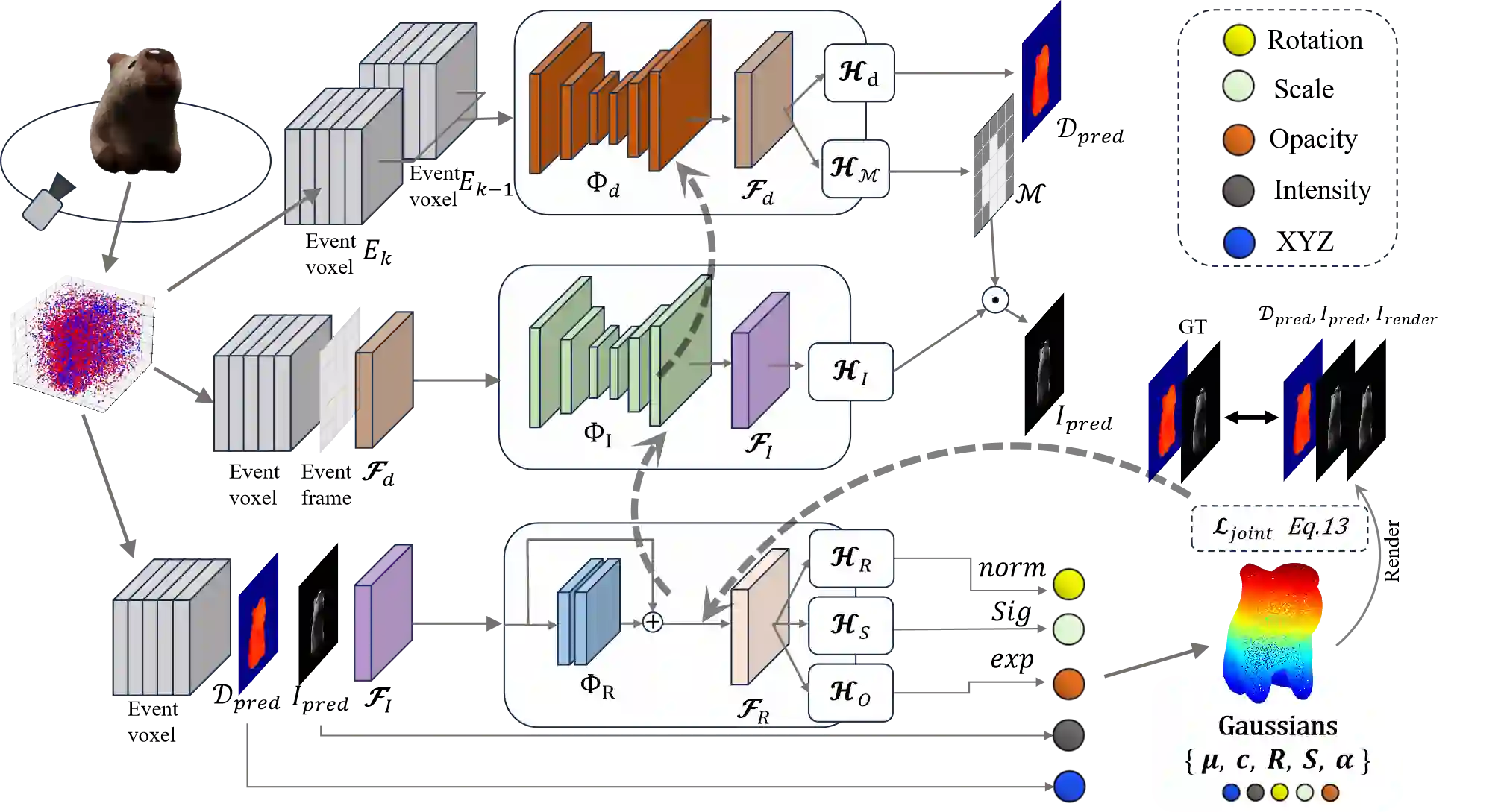
Event cameras offer promising advantages such as high dynamic range and low latency, making them well-suited for challenging lighting conditions and fast-moving scenarios. However, reconstructing 3D scenes from raw event streams is difficult because event data is sparse and does not carry absolute color information. To release its potential in 3D reconstruction, we propose the first event-based generalizable 3D reconstruction framework, called EvGGS, which reconstructs scenes as 3D Gaussians from only event input in a feedforward manner and can generalize to unseen cases without any retraining. This framework includes a depth estimation module, an intensity reconstruction module, and a Gaussian regression module. These submodules connect in a cascading manner, and we collaboratively train them with a designed joint loss to make them mutually promote. To facilitate related studies, we build a novel event-based 3D dataset with various material objects and calibrated labels of grayscale images, depth maps, camera poses, and silhouettes. Experiments show models that have jointly trained significantly outperform those trained individually. Our approach performs better than all baselines in reconstruction quality, and depth/intensity predictions with satisfactory rendering speed.
翻译:事件相机具有高动态范围和低延迟等优势,使其非常适合具有挑战性的光照条件和快速移动场景。然而,从原始事件流重建三维场景是困难的,因为事件数据稀疏且不携带绝对颜色信息。为了释放其在三维重建中的潜力,我们提出了首个基于事件的可泛化三维重建框架EvGGS,该框架以前馈方式仅从事件输入将场景重建为三维高斯表示,并且无需任何重新训练即可泛化到未见过的场景。该框架包含深度估计模块、强度重建模块和高斯回归模块。这些子模块以级联方式连接,我们通过设计的联合损失协同训练它们,使其相互促进。为了促进相关研究,我们构建了一个新颖的基于事件的三维数据集,包含多种材质物体以及经过校准的灰度图像、深度图、相机位姿和轮廓标签。实验表明,经过联合训练的模型性能显著优于单独训练的模型。我们的方法在重建质量、深度/强度预测以及令人满意的渲染速度方面均优于所有基线。