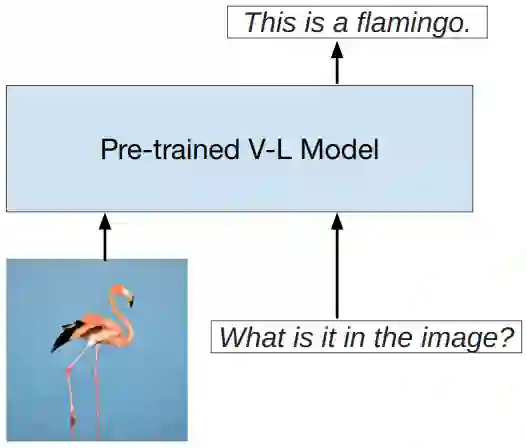
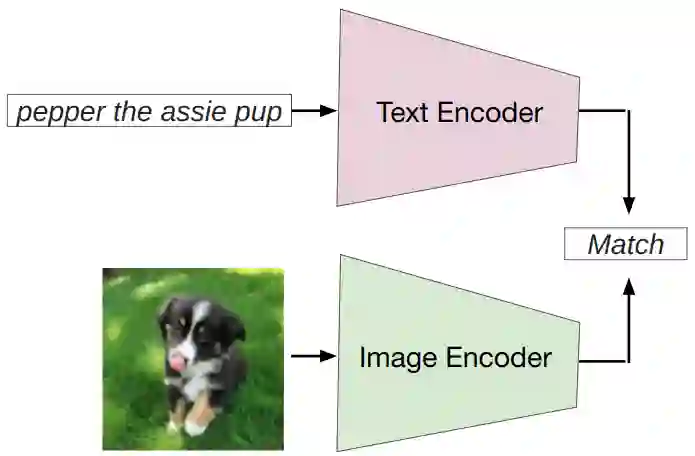
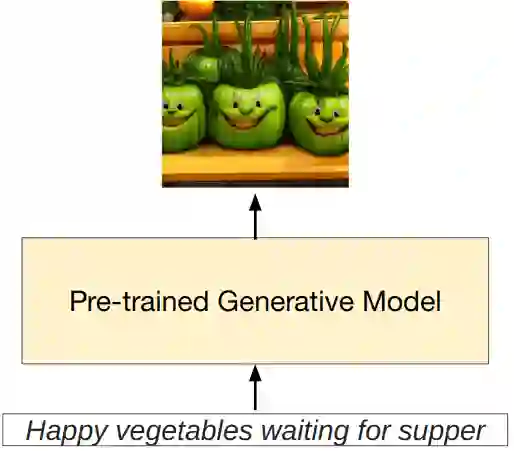
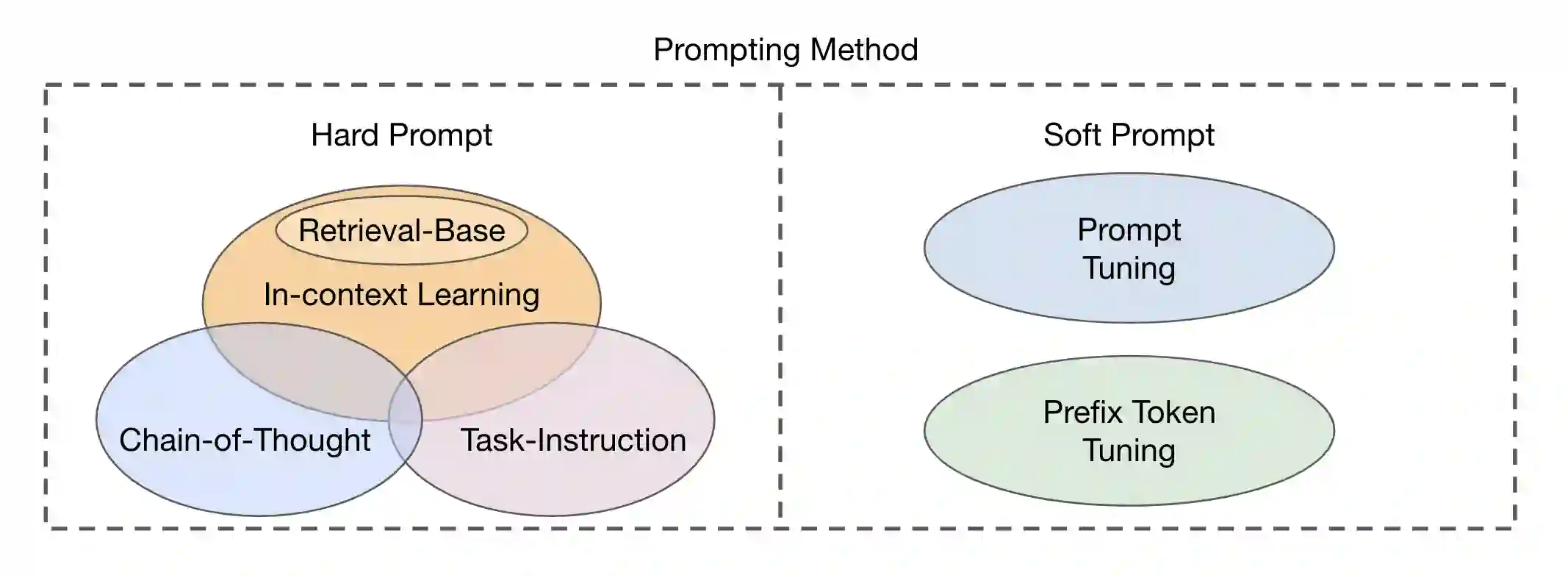
Prompt engineering is a technique that involves augmenting a large pre-trained model with task-specific hints, known as prompts, to adapt the model to new tasks. Prompts can be created manually as natural language instructions or generated automatically as either natural language instructions or vector representations. Prompt engineering enables the ability to perform predictions based solely on prompts without updating model parameters, and the easier application of large pre-trained models in real-world tasks. In past years, Prompt engineering has been well-studied in natural language processing. Recently, it has also been intensively studied in vision-language modeling. However, there is currently a lack of a systematic overview of prompt engineering on pre-trained vision-language models. This paper aims to provide a comprehensive survey of cutting-edge research in prompt engineering on three types of vision-language models: multimodal-to-text generation models (e.g. Flamingo), image-text matching models (e.g. CLIP), and text-to-image generation models (e.g. Stable Diffusion). For each type of model, a brief model summary, prompting methods, prompting-based applications, and the corresponding responsibility and integrity issues are summarized and discussed. Furthermore, the commonalities and differences between prompting on vision-language models, language models, and vision models are also discussed. The challenges, future directions, and research opportunities are summarized to foster future research on this topic.
翻译:提示工程是一种通过向大规模预训练模型注入任务特定提示(即提示)来使模型适应新任务的技术。提示可以以自然语言指令的形式手动创建,也可以自动生成为自然语言指令或向量表示。提示工程支持仅基于提示进行预测而无需更新模型参数,并降低了大规模预训练模型在实际任务中的应用门槛。近年来,提示工程在自然语言处理领域已得到充分研究。最近,该技术也被广泛应用于视觉-语言建模领域。然而,当前尚缺乏对预训练视觉-语言模型提示工程的系统性综述。本文旨在对三类视觉-语言模型(多模态到文本生成模型,例如Flamingo;图像-文本匹配模型,例如CLIP;以及文本到图像生成模型,例如Stable Diffusion)中提示工程的前沿研究进行全面调研。针对每类模型,本文分别总结并讨论了其简要模型概述、提示方法、基于提示的应用以及相应的责任与完整性议题。此外,本文还探讨了视觉-语言模型、语言模型与视觉模型在提示方法上的共性与差异。最后,本文总结了当前面临的挑战、未来发展方向及研究机遇,以推动该领域的后续研究。