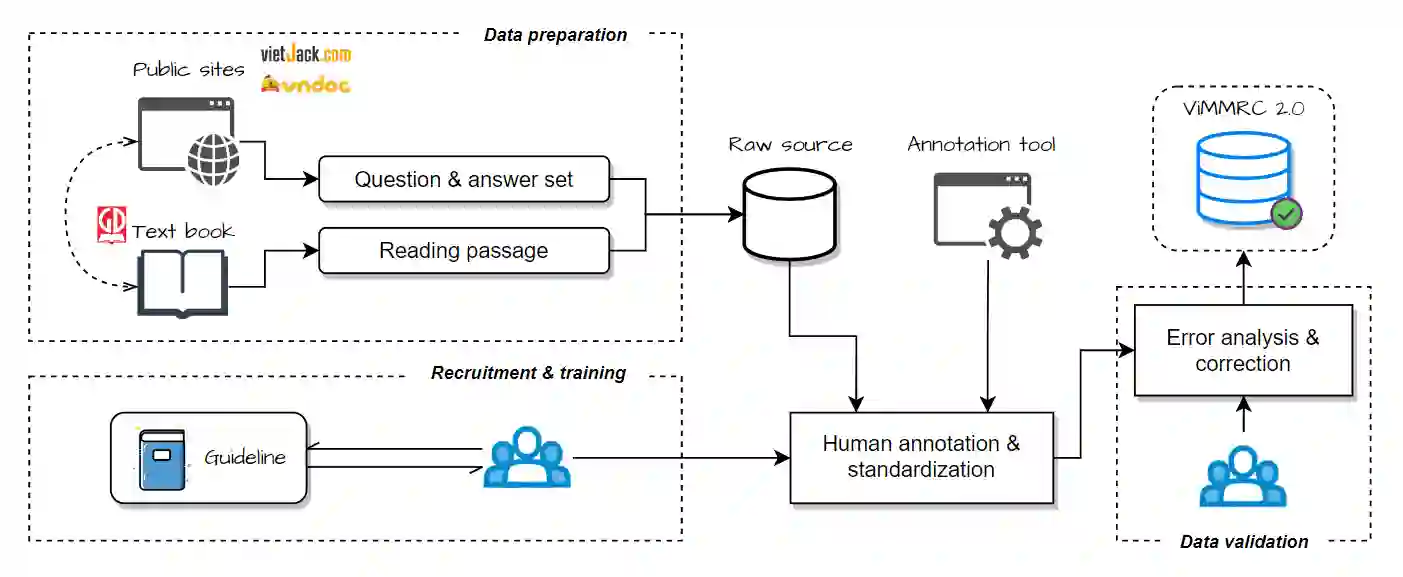
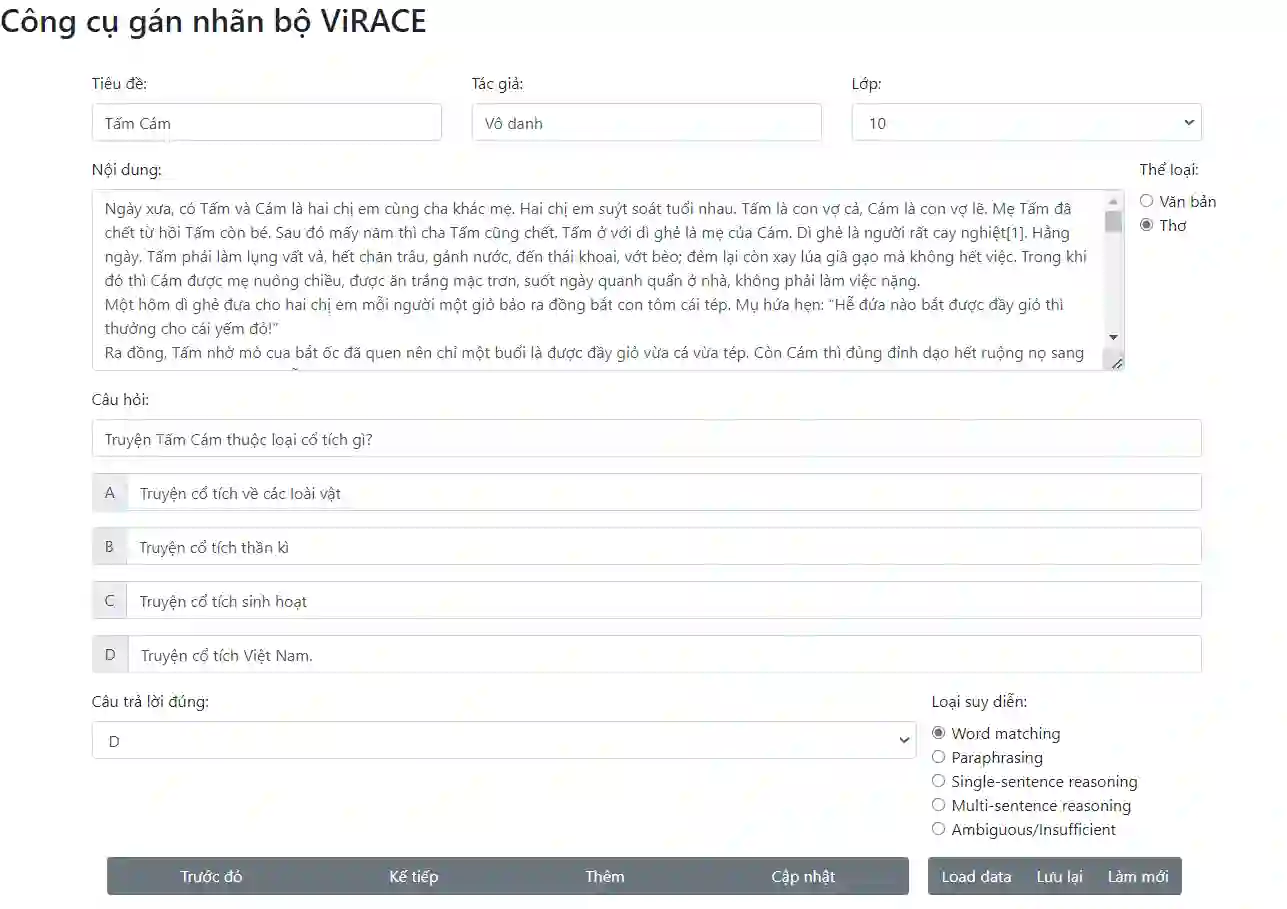
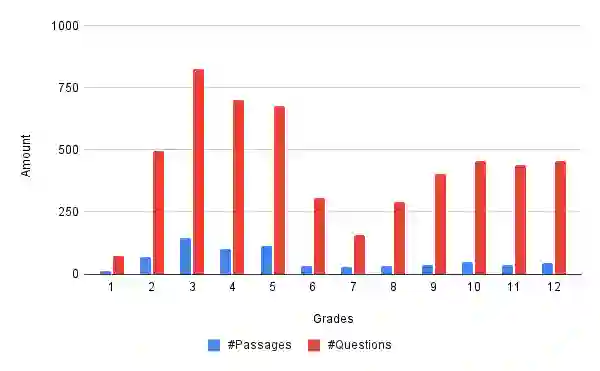
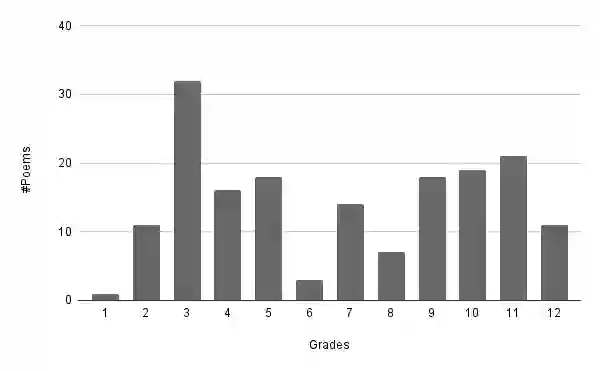
Machine reading comprehension has been an interesting and challenging task in recent years, with the purpose of extracting useful information from texts. To attain the computer ability to understand the reading text and answer relevant information, we introduce ViMMRC 2.0 - an extension of the previous ViMMRC for the task of multiple-choice reading comprehension in Vietnamese Textbooks which contain the reading articles for students from Grade 1 to Grade 12. This dataset has 699 reading passages which are prose and poems, and 5,273 questions. The questions in the new dataset are not fixed with four options as in the previous version. Moreover, the difficulty of questions is increased, which challenges the models to find the correct choice. The computer must understand the whole context of the reading passage, the question, and the content of each choice to extract the right answers. Hence, we propose the multi-stage approach that combines the multi-step attention network (MAN) with the natural language inference (NLI) task to enhance the performance of the reading comprehension model. Then, we compare the proposed methodology with the baseline BERTology models on the new dataset and the ViMMRC 1.0. Our multi-stage models achieved 58.81% by Accuracy on the test set, which is 5.34% better than the highest BERTology models. From the results of the error analysis, we found the challenge of the reading comprehension models is understanding the implicit context in texts and linking them together in order to find the correct answers. Finally, we hope our new dataset will motivate further research in enhancing the language understanding ability of computers in the Vietnamese language.
翻译:机器阅读理解近年来一直是一个有趣且富有挑战性的任务,其目的是从文本中提取有用信息。为使计算机具备理解阅读文本并回答相关信息的能力,我们引入了ViMMRC 2.0——这是先前ViMMRC数据集的一个扩展,用于越南教科书中的多项选择阅读任务,这些教科书包含从一年级到十二年级学生的阅读文章。该数据集包含699篇阅读篇章(包括散文和诗歌)和5273个问题。新数据集中的问题不再像旧版本那样固定为四个选项。此外,问题的难度有所增加,这对模型寻找正确答案构成了挑战。计算机必须理解阅读篇章的全文、问题以及每个选项的内容,才能提取出正确答案。因此,我们提出了一种多阶段方法,将多步注意力网络(MAN)与自然语言推理(NLI)任务相结合,以提升阅读理解模型的性能。然后,我们在新数据集和ViMMRC 1.0上,将所提出的方法与基线BERTology模型进行了比较。我们的多阶段模型在测试集上的准确率达到58.81%,比最高的BERTology模型高出5.34%。从错误分析的结果中,我们发现阅读理解模型的挑战在于理解文本中的隐含语境,并将其联系起来以找到正确答案。最后,我们希望我们的新数据集能激励更多关于增强计算机在越南语中语言理解能力的研究。