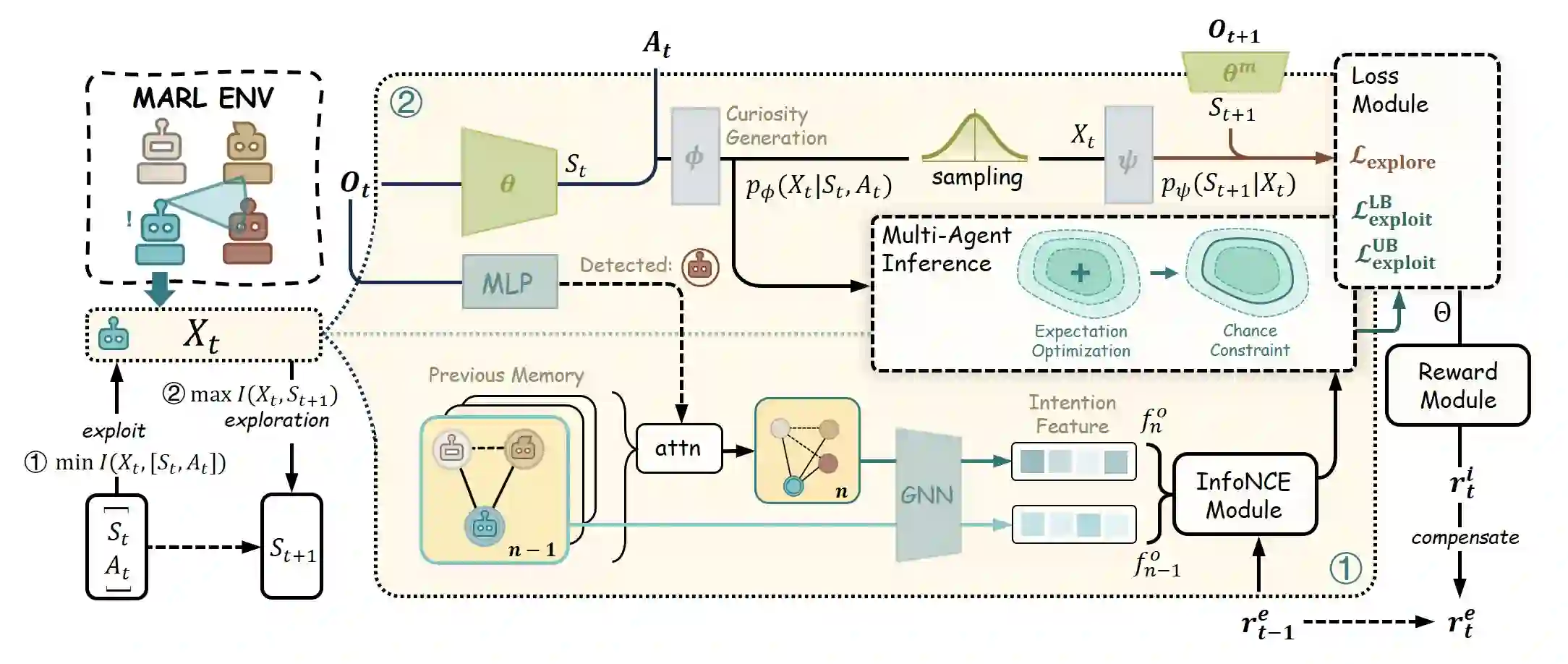
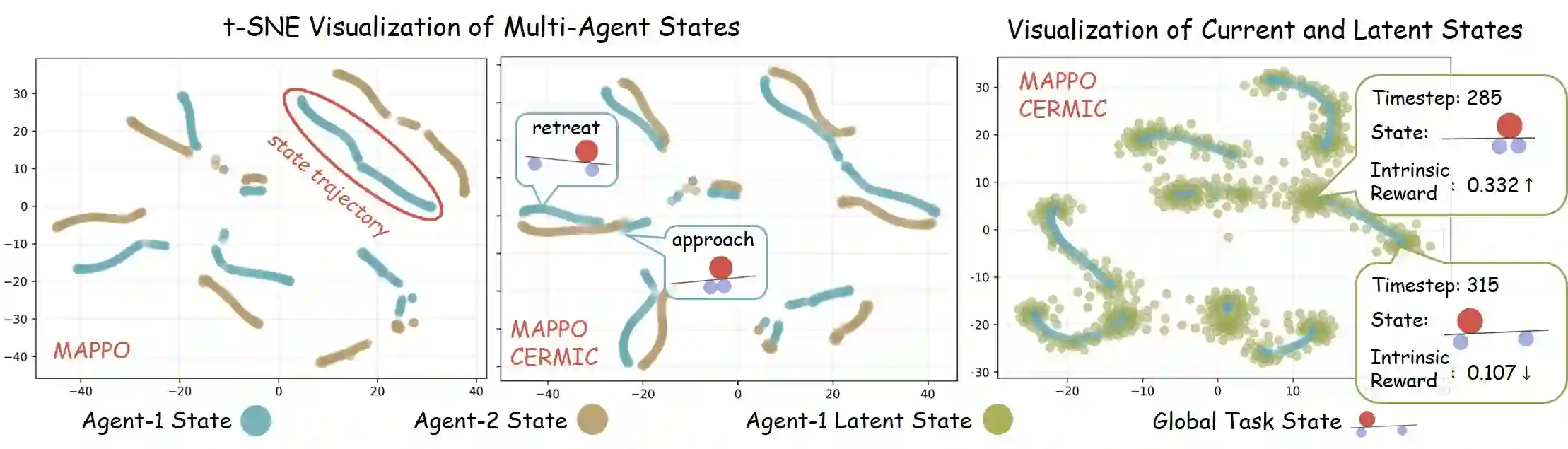
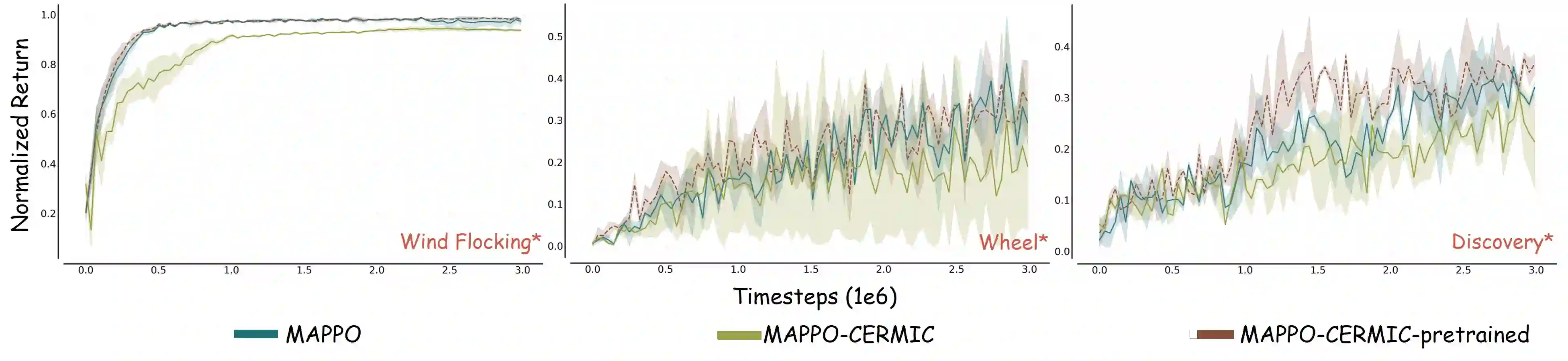
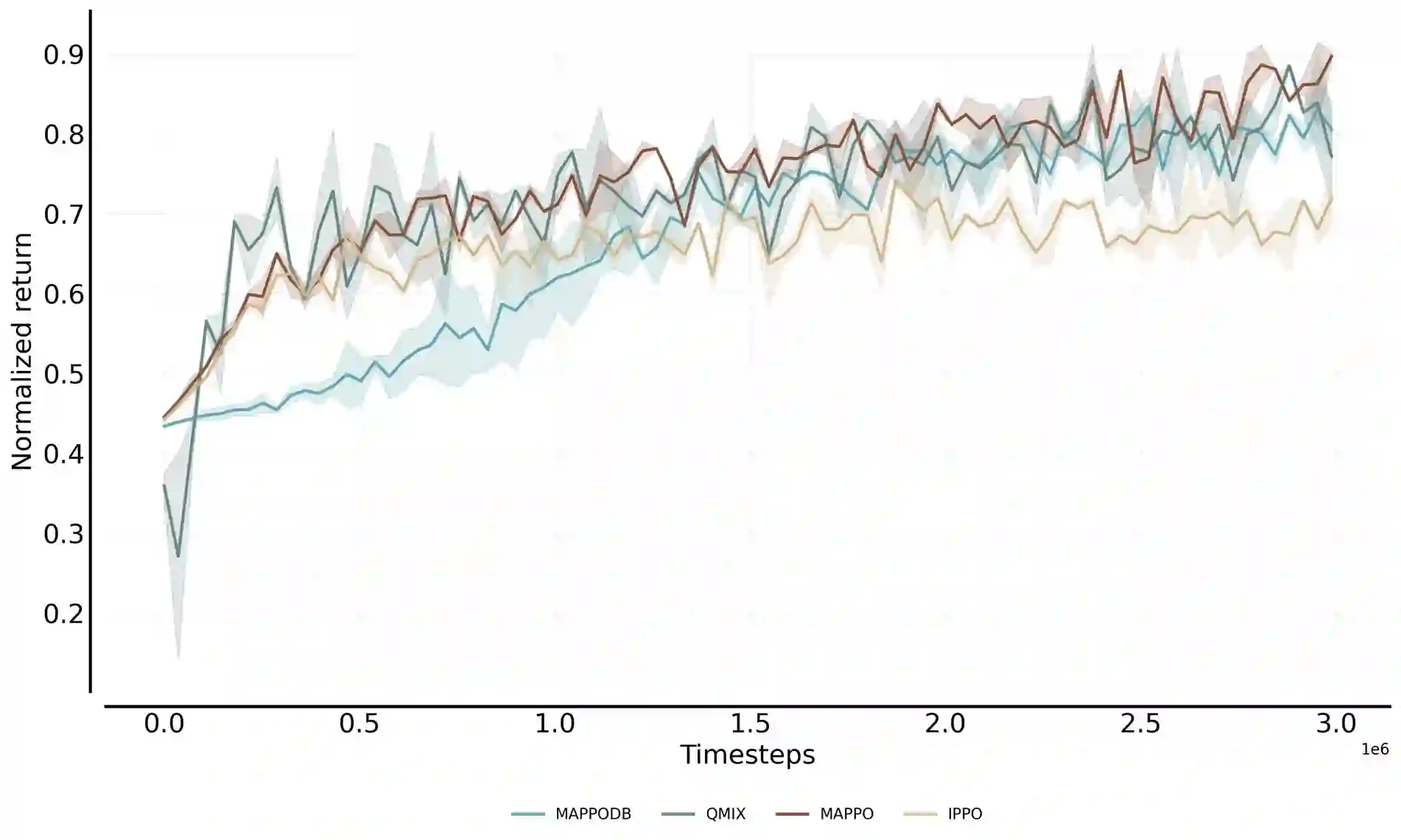
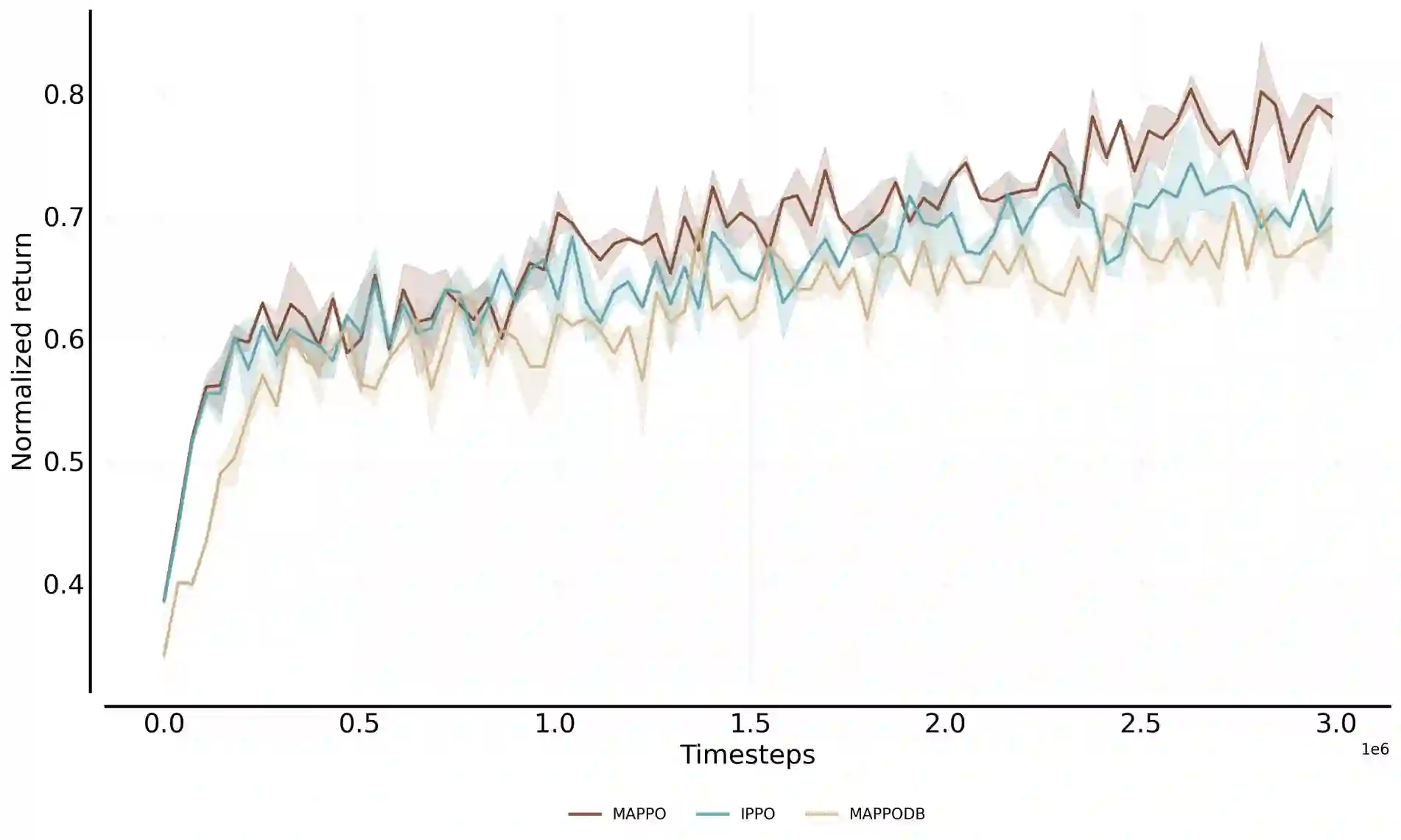
Autonomous exploration in complex multi-agent reinforcement learning (MARL) with sparse rewards critically depends on providing agents with effective intrinsic motivation. While artificial curiosity offers a powerful self-supervised signal, it often confuses environmental stochasticity with meaningful novelty. Moreover, existing curiosity mechanisms exhibit a uniform novelty bias, treating all unexpected observations equally. However, peer behavior novelty, which encode latent task dynamics, are often overlooked, resulting in suboptimal exploration in decentralized, communication-free MARL settings. To this end, inspired by how human children adaptively calibrate their own exploratory behaviors via observing peers, we propose a novel approach to enhance multi-agent exploration. We introduce CERMIC, a principled framework that empowers agents to robustly filter noisy surprise signals and guide exploration by dynamically calibrating their intrinsic curiosity with inferred multi-agent context. Additionally, CERMIC generates theoretically-grounded intrinsic rewards, encouraging agents to explore state transitions with high information gain. We evaluate CERMIC on benchmark suites including VMAS, Meltingpot, and SMACv2. Empirical results demonstrate that exploration with CERMIC significantly outperforms SoTA algorithms in sparse-reward environments.
翻译:在具有稀疏奖励的复杂多智能体强化学习(MARL)中,自主探索的关键在于为智能体提供有效的内在动机。虽然人工好奇心提供了强大的自监督信号,但它常常将环境随机性与有意义的新颖性相混淆。此外,现有的好奇心机制表现出统一的新颖性偏好,对所有意外观测一视同仁。然而,编码潜在任务动态的同伴行为新颖性往往被忽视,导致在去中心化、无需通信的MARL设置中出现次优探索。为此,受人类儿童通过观察同伴自适应地校准自身探索行为的启发,我们提出了一种增强多智能体探索的新方法。我们引入了CERMIC,这是一个原则性框架,使智能体能够鲁棒地过滤噪声惊喜信号,并通过将内在好奇心与推断的多智能体上下文进行动态校准来引导探索。此外,CERMIC生成具有理论依据的内在奖励,鼓励智能体探索具有高信息增益的状态转移。我们在包括VMAS、Meltingpot和SMACv2在内的基准测试套件上评估了CERMIC。实证结果表明,在稀疏奖励环境中,使用CERMIC进行探索的性能显著优于最先进的(SoTA)算法。