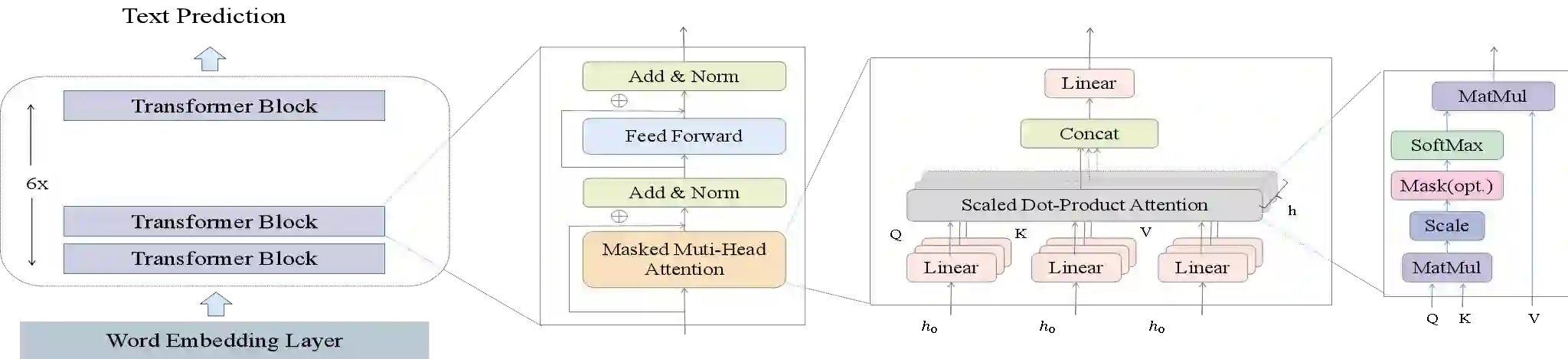
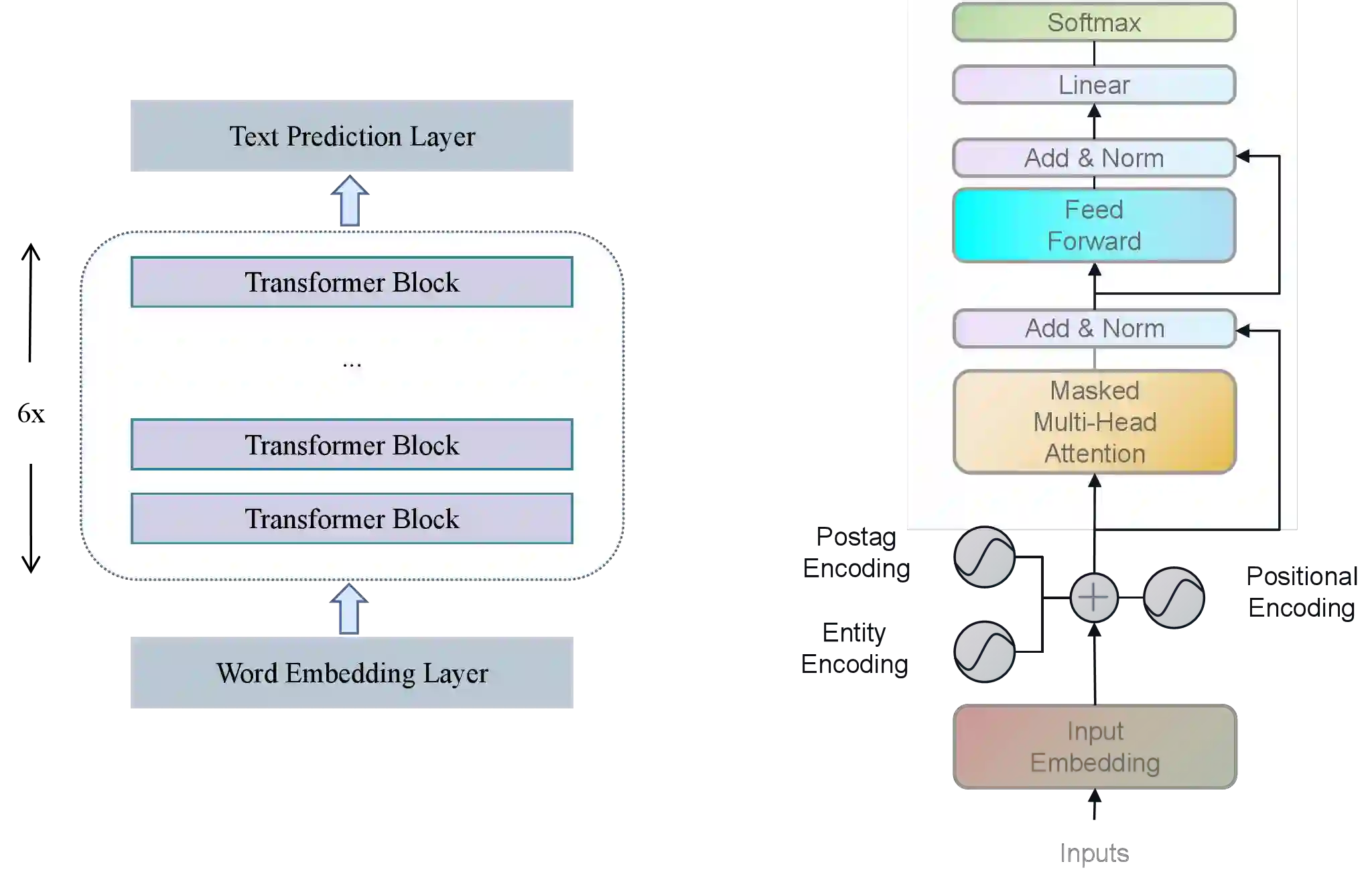
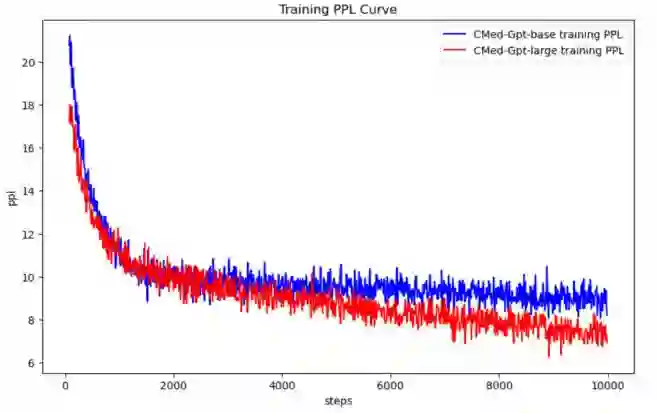
Medical dialogue generation relies on natural language generation techniques to enable online medical consultations. Recently, the widespread adoption of large-scale models in the field of natural language processing has facilitated rapid advancements in this technology. Existing medical dialogue models are mostly based on BERT and pre-trained on English corpora, but there is a lack of high-performing models on the task of Chinese medical dialogue generation. To solve the above problem, this paper proposes CMed-GPT, which is the GPT pre-training language model based on Chinese medical domain text. The model is available in two versions, namely, base and large, with corresponding perplexity values of 8.64 and 8.01. Additionally, we incorporate lexical and entity embeddings into the dialogue text in a uniform manner to meet the requirements of downstream dialogue generation tasks. By applying both fine-tuning and p-tuning to CMed-GPT, we lowered the PPL from 8.44 to 7.35. This study not only confirms the exceptional performance of the CMed-GPT model in generating Chinese biomedical text but also highlights the advantages of p-tuning over traditional fine-tuning with prefix prompts. Furthermore, we validate the significance of incorporating external information in medical dialogue generation, which enhances the quality of dialogue generation.
翻译:医疗对话生成依赖自然语言生成技术,旨在实现在线医疗咨询。近年来,大规模模型在自然语言处理领域的广泛应用推动了该技术的快速发展。现有医疗对话模型大多基于BERT并在英文语料上预训练,但在中文医疗对话生成任务上缺乏高性能模型。为解决上述问题,本文提出CMed-GPT——一种基于中文医学领域文本的GPT预训练语言模型。该模型提供base和large两个版本,其对应困惑度值分别为8.64和8.01。此外,我们将词汇嵌入和实体嵌入以统一方式融入对话文本,以满足下游对话生成任务的需求。通过对CMed-GPT应用微调和p-tuning(提示调优),我们将PPL从8.44降低至7.35。本研究不仅证实了CMed-GPT模型在生成中文生物医学文本方面的卓越性能,还凸显了p-tuning相较于传统前缀提示微调的优势。同时,我们验证了在医疗对话生成中融入外部信息的重要性,这有助于提升对话生成质量。