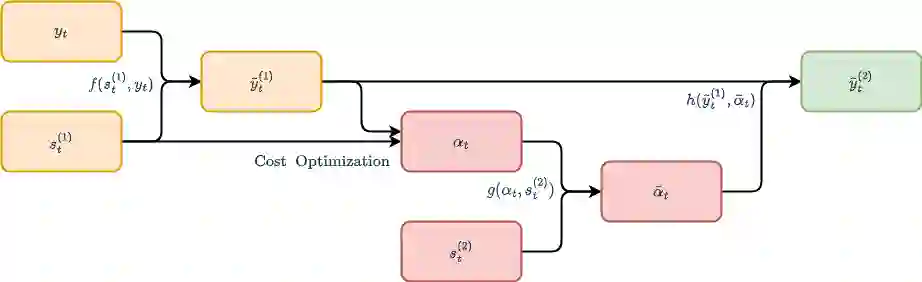
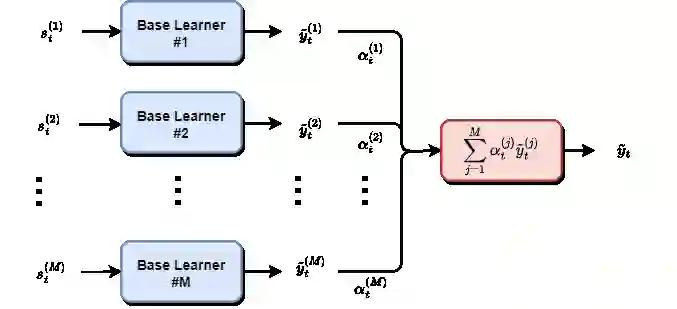
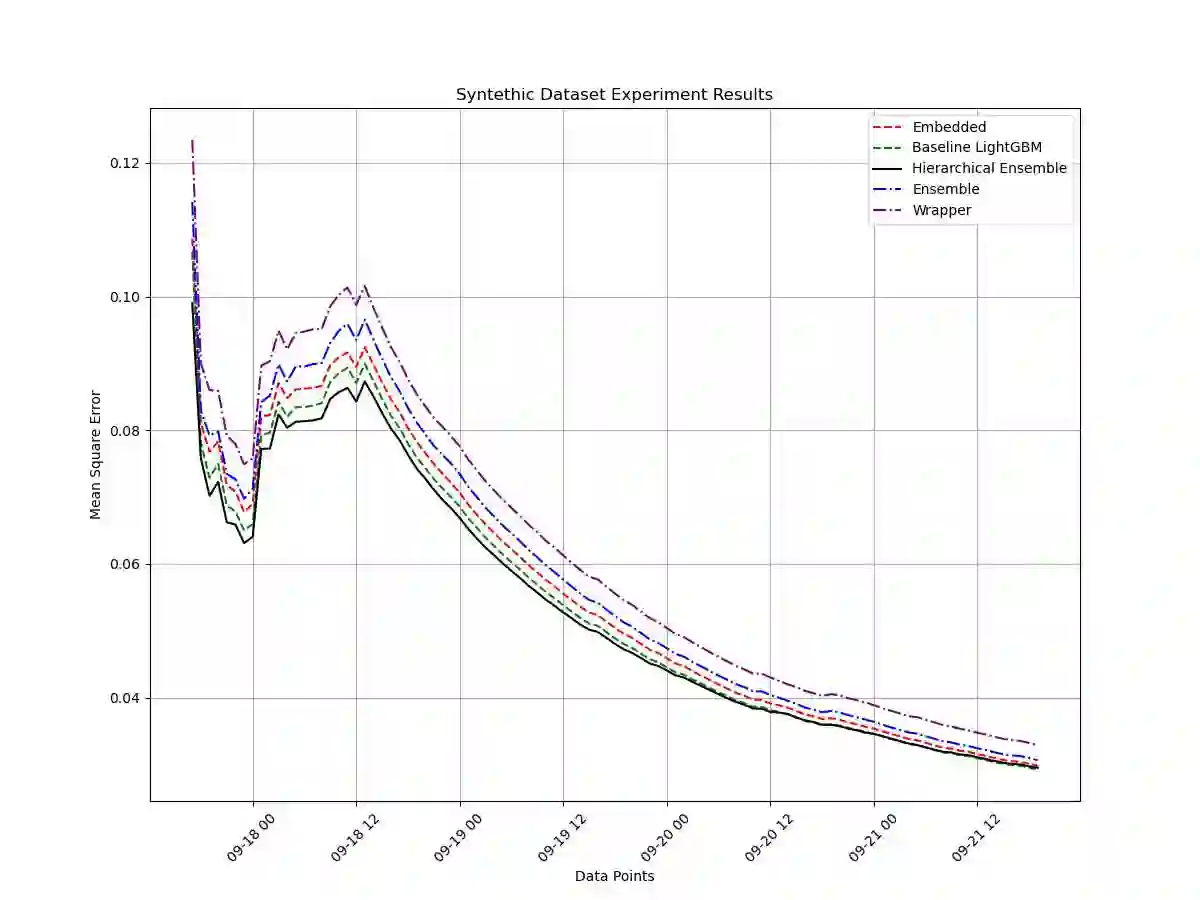
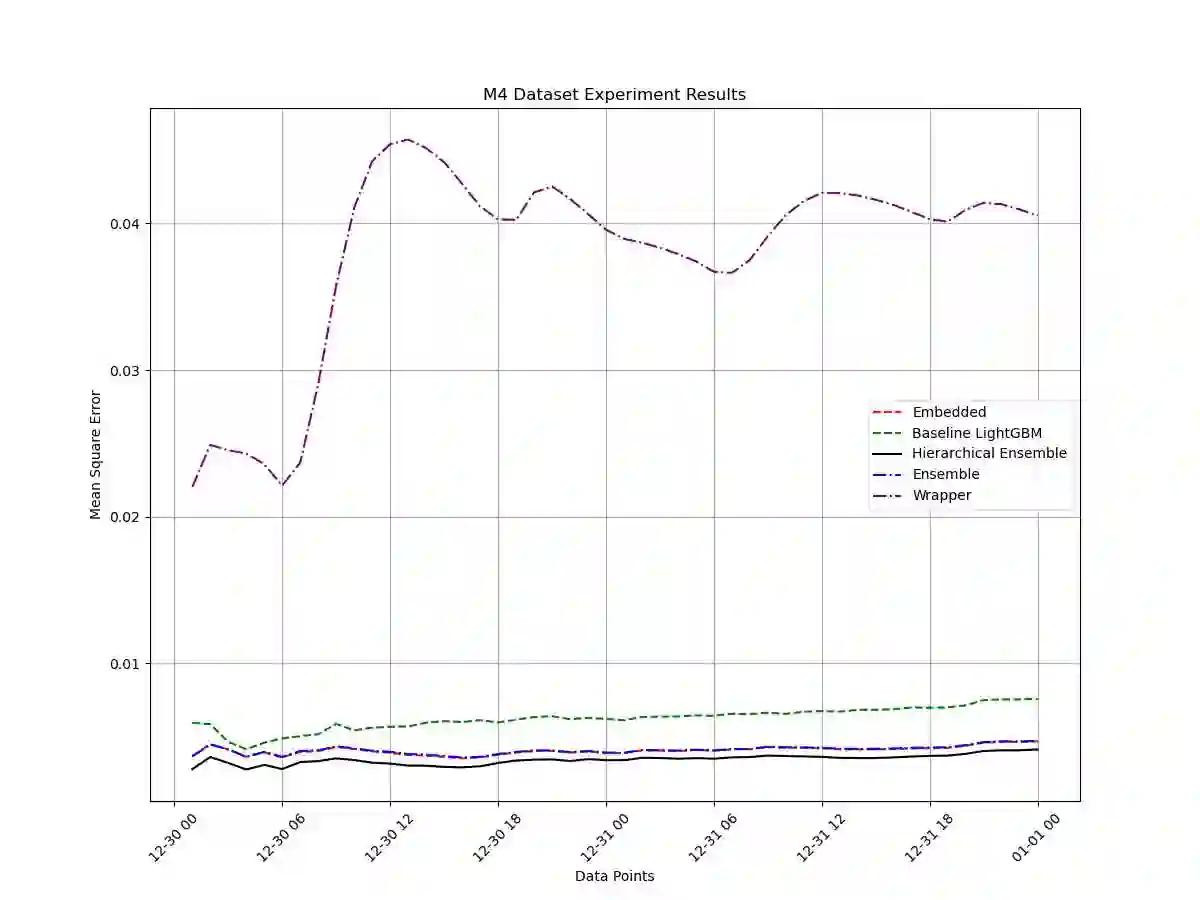
We study a novel ensemble approach for feature selection based on hierarchical stacking in cases of non-stationarity and limited number of samples with large number of features. Our approach exploits the co-dependency between features using a hierarchical structure. Initially, a machine learning model is trained using a subset of features, and then the model's output is updated using another algorithm with the remaining features to minimize the target loss. This hierarchical structure allows for flexible depth and feature selection. By exploiting feature co-dependency hierarchically, our proposed approach overcomes the limitations of traditional feature selection methods and feature importance scores. The effectiveness of the approach is demonstrated on synthetic and real-life datasets, indicating improved performance with scalability and stability compared to the traditional methods and state-of-the-art approaches.
翻译:我们研究了一种新颖的基于层次堆叠的集成特征选择方法,适用于非平稳性、样本数量有限但特征维度较高的场景。该方法通过层次结构利用特征之间的共依赖性:首先使用特征子集训练机器学习模型,然后利用另一算法结合剩余特征更新模型输出以最小化目标损失。这种层次结构允许灵活调整深度并进行特征选择。通过层次化地挖掘特征共依赖性,本文提出的方法克服了传统特征选择方法与特征重要性评分的局限性。在合成数据集与真实数据集上的实验结果表明,与传统方法及现有最优方法相比,该方法在可扩展性与稳定性方面均表现出更优的性能。