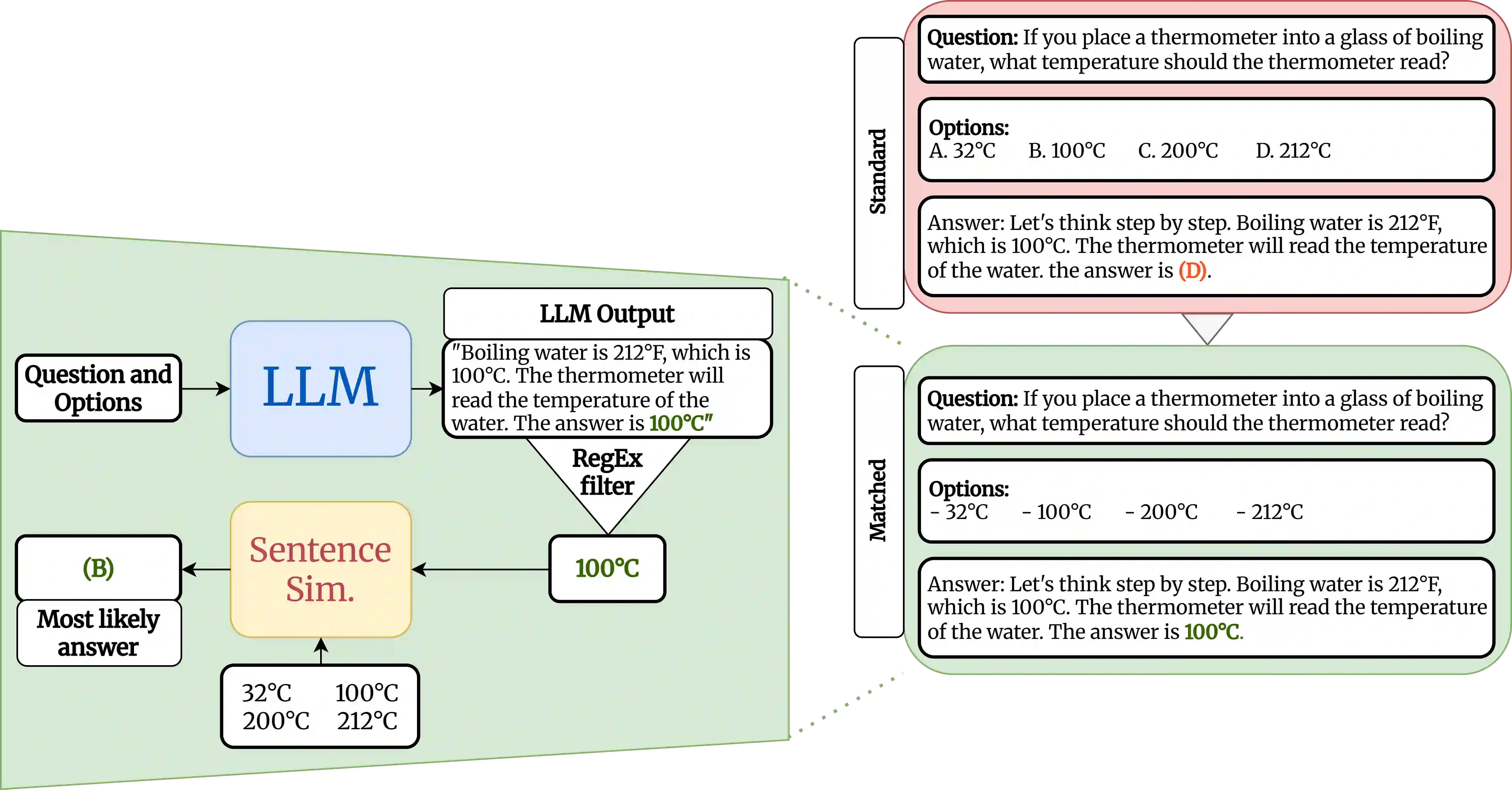
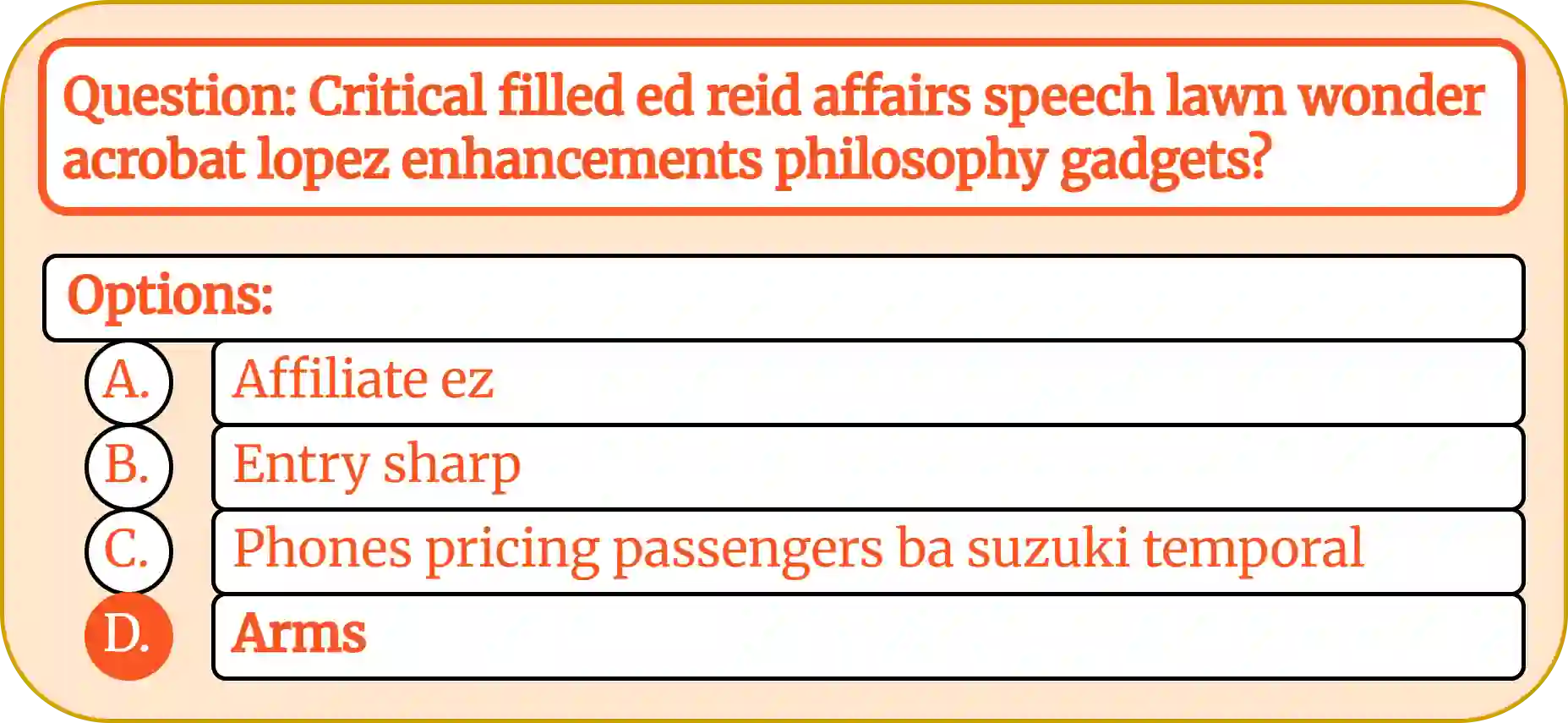
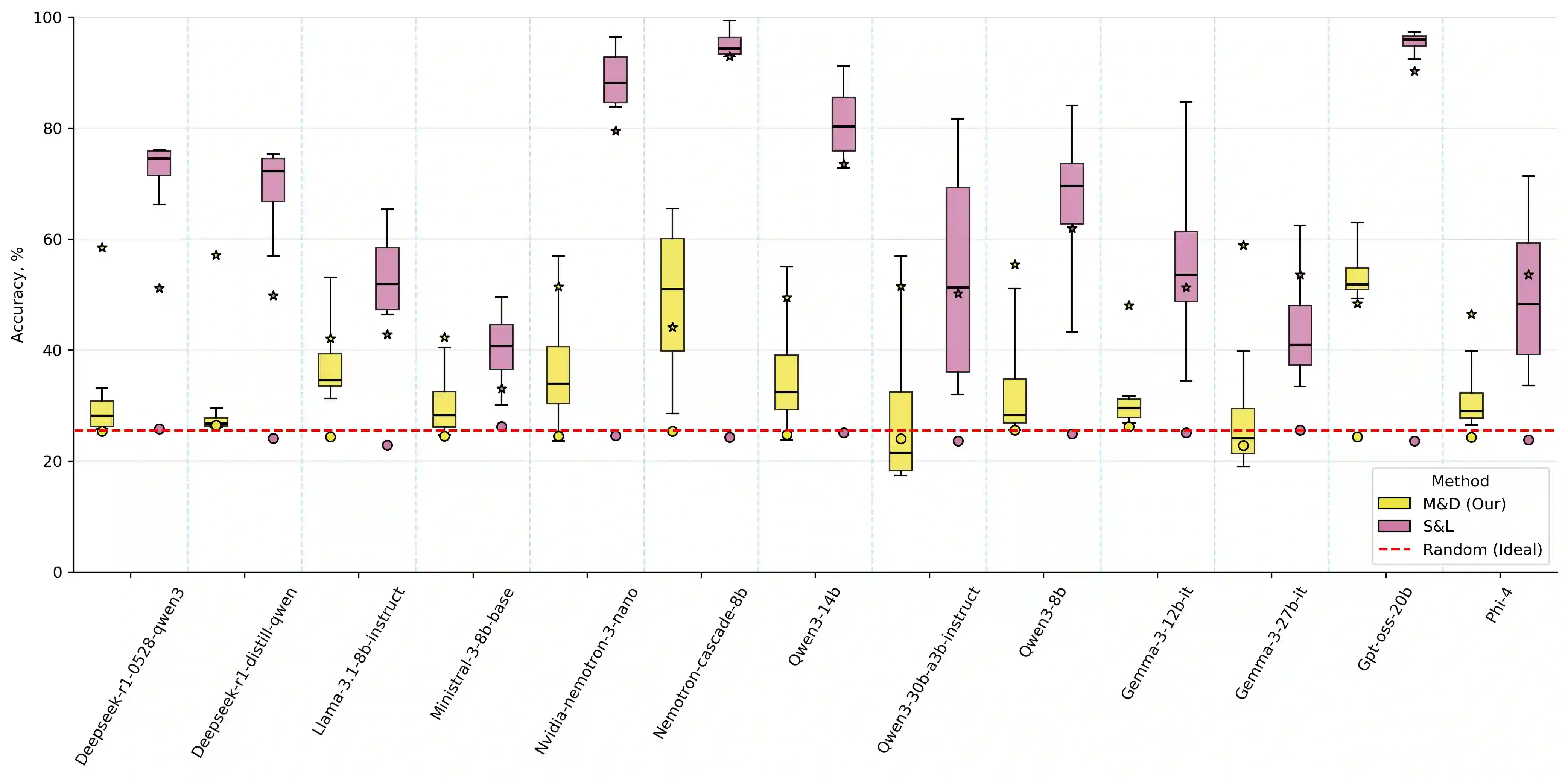
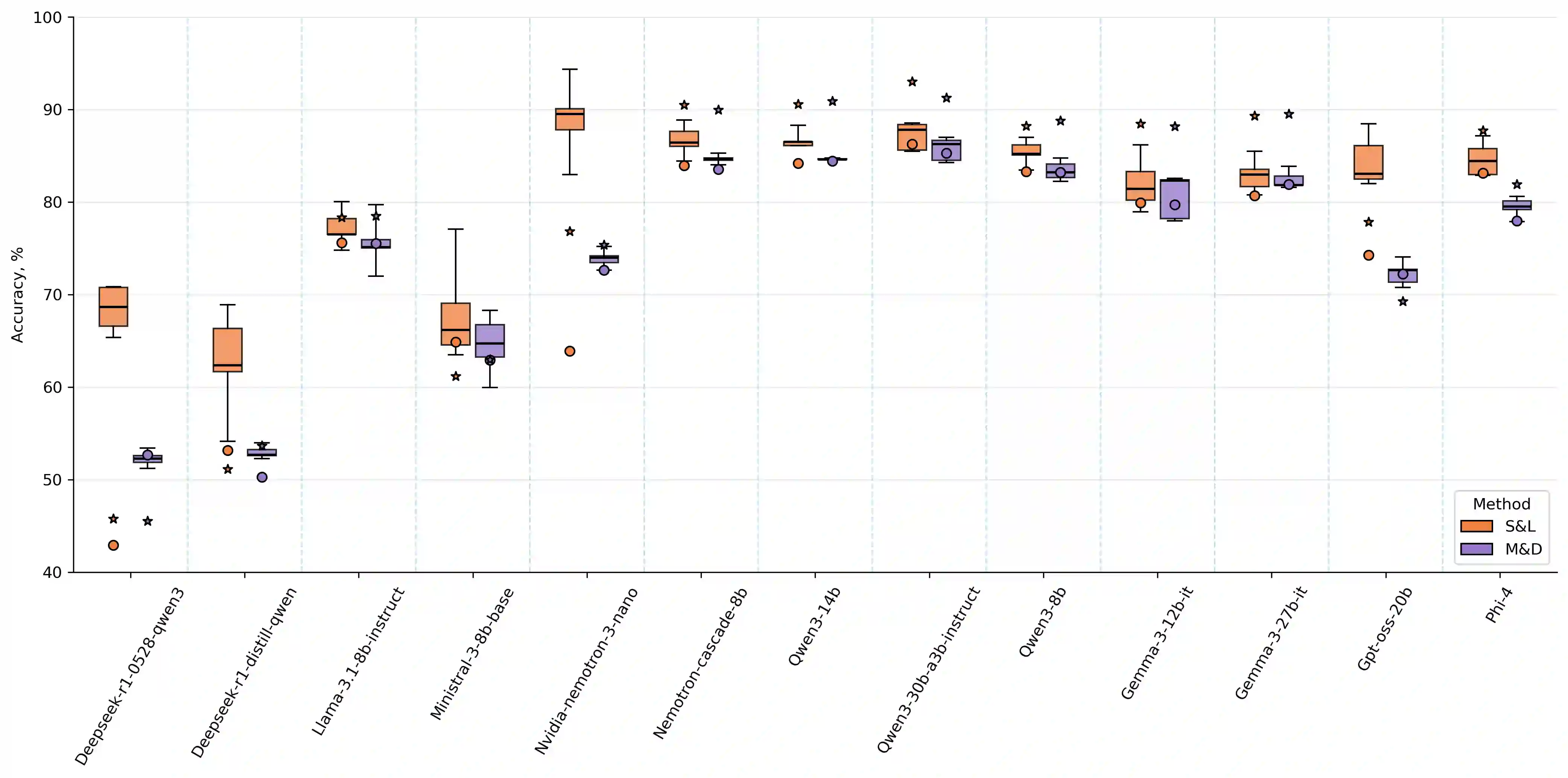
Multiple-choice question (MCQ) benchmarks have been a standard evaluation practice for measuring LLMs' ability to reason and answer knowledge-based questions. Through a synthetic NonsenseQA benchmark, we observe that different LLMs exhibit varying degrees of label-position-few-shot-prompt bias, where the model either uses the answer position, the label in front of the answer, the distributions of correct answers present in the few-shot prompt, or a combination of all to answer each MCQ question. We propose a simple bias-reduced evaluation protocol that replaces the labels of each question with uniform, unordered labels and prompts the LLM to use the whole answer presented. With a simple sentence similarity model, we demonstrate improved robustness and lower standard deviation between different permutations of answers with a minimal drop in LLM's performance, exposing the LLM's capabilities under reduced evaluation artifacts, without any help from the prompt examples or the option labels. Across multiple benchmarks and models, this protocol substantially improves the robustness to answer permutations, reducing mean accuracy variance $3\times$ with only a minimal decrease in the mean model's performance. Through ablation studies on various embedding models and similarity functions, we show that the method is more robust than the standard ones.
翻译:多项选择题(MCQ)基准测试一直是评估大型语言模型(LLM)推理与回答知识性问题能力的标准实践。通过构建合成的NonsenseQA基准,我们观察到不同LLM表现出不同程度的标签-位置-少样本-提示偏见:模型可能利用答案位置、答案前的标签、少样本提示中正确答案的分布,或综合运用所有这些因素来回答每道多选题。我们提出一种简单的偏见削减评估方案,将每道题的标签替换为统一的无序标签,并提示LLM使用完整的答案表述。借助简单的句子相似度模型,我们在LLM性能仅轻微下降的情况下,证明了该方法能提升鲁棒性并降低不同答案排列间的标准差,从而在减少评估人为因素影响的前提下揭示LLM的真实能力,且无需借助提示示例或选项标签。在多个基准测试和模型上的实验表明,该方案显著提升了对答案排列的鲁棒性,将平均准确率方差降低至原来的1/3,同时仅使模型平均性能出现微小下降。通过对不同嵌入模型与相似度函数的消融研究,我们证明该方法比传统方案更具鲁棒性。