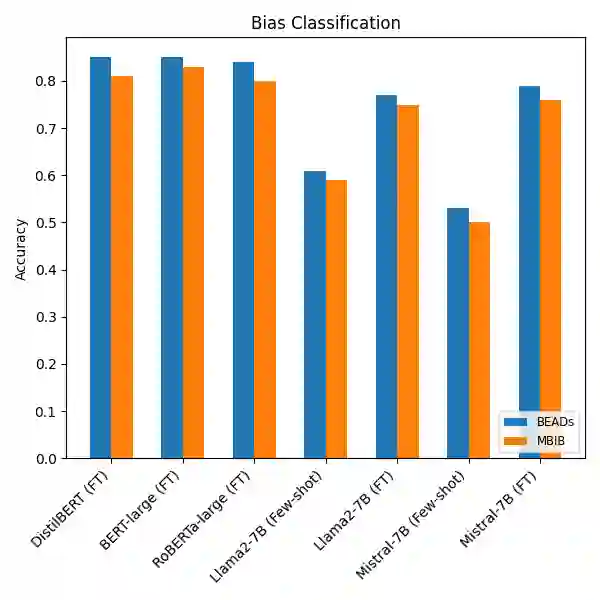
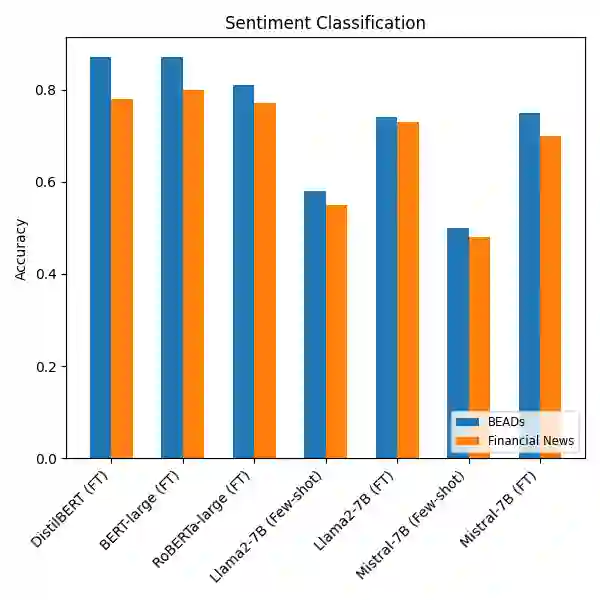
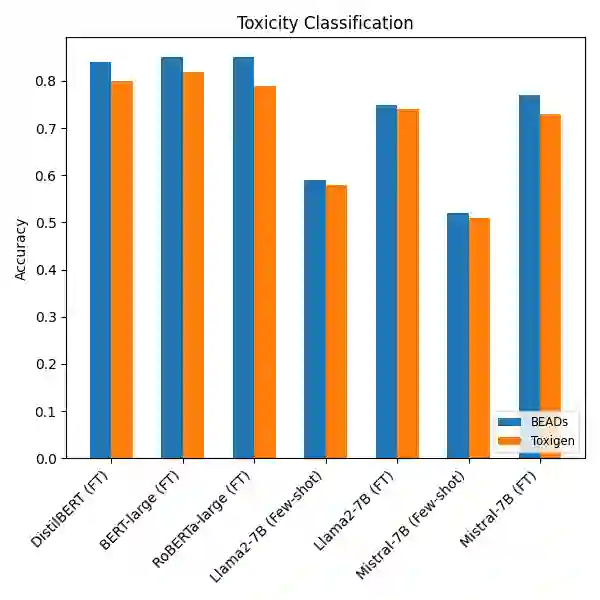
Recent advances in large language models (LLMs) have substantially improved natural language processing (NLP) applications. However, these models often inherit and amplify biases present in their training data. Although several datasets exist for bias detection, most are limited to one or two NLP tasks, typically classification or evaluation and do not provide broad coverage across diverse task settings. To address this gap, we introduce the \textbf{Bias Evaluations Across Domains} (\textbf{B}\texttt{EADs}) dataset, designed to support a wide range of NLP tasks, including text classification, token classification, bias quantification, and benign language generation. A key contribution of this work is a gold-standard annotation scheme that supports both evaluation and supervised training of language models. Experiments on state-of-the-art models reveal some gaps: some models exhibit systematic bias toward specific demographics, while others apply safety guardrails more strictly or inconsistently across groups. Overall, these results highlight persistent shortcomings in current models and underscore the need for comprehensive bias evaluation. Project: https://vectorinstitute.github.io/BEAD/ Data: https://huggingface.co/datasets/shainar/BEAD
翻译:近年来,大型语言模型(LLMs)的显著进展极大地推动了自然语言处理(NLP)应用的发展。然而,这些模型常常继承并放大了其训练数据中存在的偏见。尽管已有多个用于偏见检测的数据集,但大多数仅限于一两种NLP任务(通常是分类或评估任务),未能提供跨多样化任务场景的广泛覆盖。为弥补这一不足,我们引入了**跨领域偏见评估**(**B**EADs)数据集,该数据集旨在支持广泛的NLP任务,包括文本分类、词元分类、偏见量化以及良性语言生成。本研究的一个关键贡献是提出了一套支持语言模型评估与监督式训练的金标准标注方案。在先进模型上的实验揭示了一些不足:部分模型对特定人口统计群体表现出系统性偏见,而另一些模型则在跨群体应用安全防护措施时更为严格或不一致。总体而言,这些结果突显了当前模型存在的持续缺陷,并强调了进行全面偏见评估的必要性。项目地址:https://vectorinstitute.github.io/BEAD/ 数据地址:https://huggingface.co/datasets/shainar/BEAD