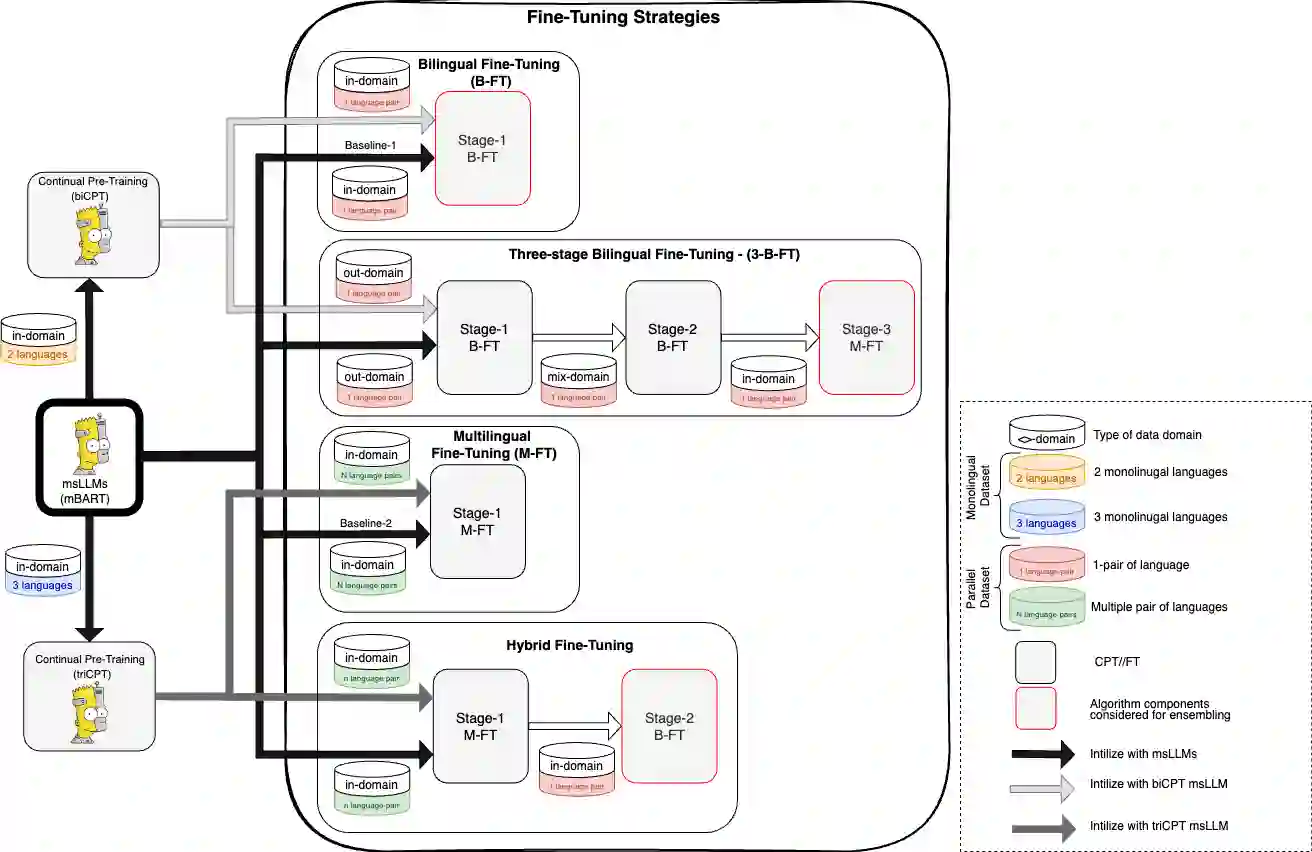
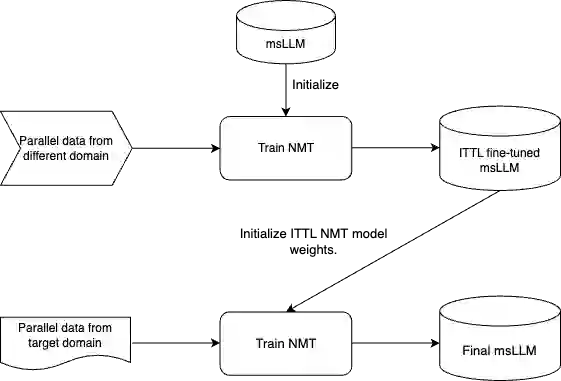
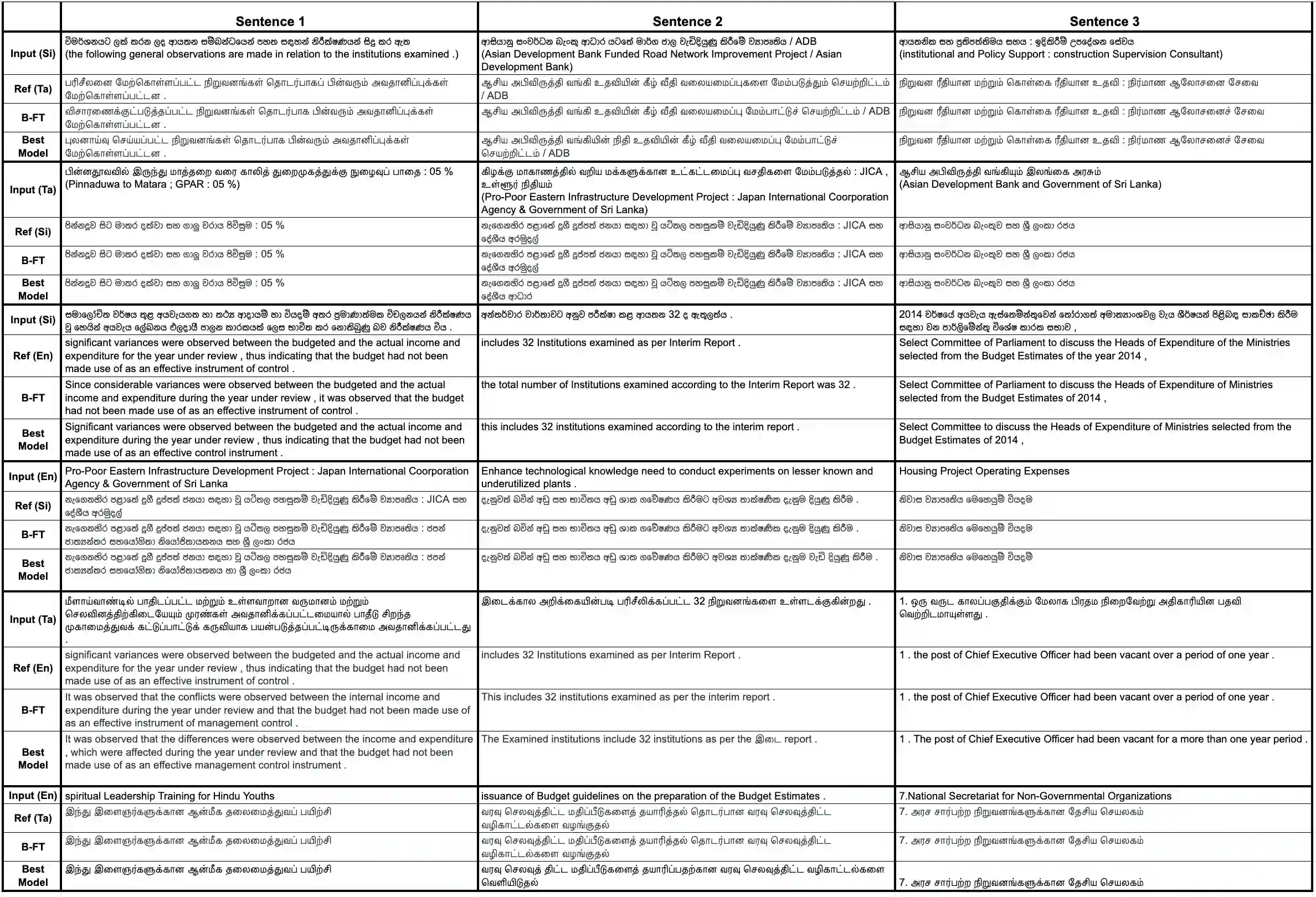
Fine-tuning multilingual sequence-to-sequence large language models (msLLMs) has shown promise in developing neural machine translation (NMT) systems for low-resource languages (LRLs). However, conventional single-stage fine-tuning methods struggle in extremely low-resource NMT settings, where training data is very limited. This paper contributes to artificial intelligence by proposing two approaches for adapting msLLMs in these challenging scenarios: (1) continual pre-training (CPT), where the msLLM is further trained with domain-specific monolingual data to compensate for the under-representation of LRLs, and (2) intermediate task transfer learning (ITTL), a method that fine-tunes the msLLM with both in-domain and out-of-domain parallel data to enhance its translation capabilities across various domains and tasks. As an application in engineering, these methods are implemented in NMT systems for Sinhala, Tamil, and English (six language pairs) in domain-specific, extremely low-resource settings (datasets containing fewer than 100,000 samples). Our experiments reveal that these approaches enhance translation performance by an average of +1.47 bilingual evaluation understudy (BLEU) score compared to the standard single-stage fine-tuning baseline across all translation directions. Additionally, a multi-model ensemble further improves performance by an additional BLEU score.
翻译:对多语言序列到序列大语言模型进行微调,在开发面向低资源语言的神经机器翻译系统方面已展现出潜力。然而,在训练数据极为有限的极端低资源神经机器翻译场景中,传统的单阶段微调方法面临困难。本文为人工智能领域做出贡献,提出了两种在此类挑战性场景中适配多语言序列到序列大语言模型的方法:(1) 持续预训练,该方法利用领域特定的单语数据对模型进行进一步训练,以弥补低资源语言在模型中的表征不足;(2) 中间任务迁移学习,该方法结合领域内与领域外的平行数据对模型进行微调,以增强其跨不同领域与任务的翻译能力。作为工程应用,这些方法在领域特定、极端低资源的设定下,被应用于僧伽罗语、泰米尔语与英语之间的神经机器翻译系统。实验结果表明,与标准的单阶段微调基线相比,这些方法在所有翻译方向上平均提升了+1.47个BLEU分数。此外,多模型集成策略进一步带来了额外的BLEU分数提升。