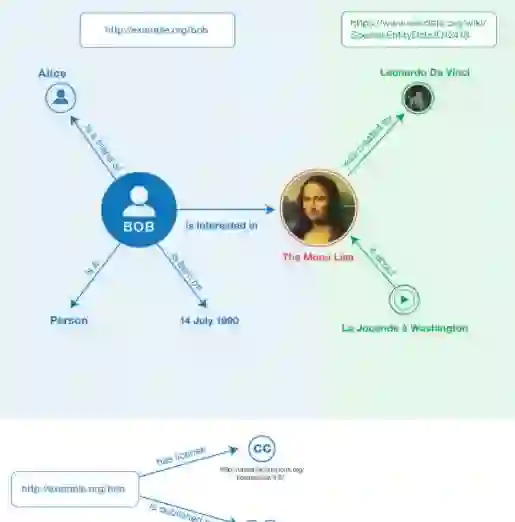
Large Language Models (LLMs) are advancing at a rapid pace, with significant improvements at natural language processing and coding tasks. Yet, their ability to work with formal languages representing data, specifically within the realm of knowledge graph engineering, remains under-investigated. To evaluate the proficiency of various LLMs, we created a set of five tasks that probe their ability to parse, understand, analyze, and create knowledge graphs serialized in Turtle syntax. These tasks, each embodying distinct degrees of complexity and being able to scale with the size of the problem, have been integrated into our automated evaluation system, the LLM-KG-Bench. The evaluation encompassed four commercially available LLMs - GPT-3.5, GPT-4, Claude 1.3, and Claude 2.0, as well as two freely accessible offline models, GPT4All Vicuna and GPT4All Falcon 13B. This analysis offers an in-depth understanding of the strengths and shortcomings of LLMs in relation to their application within RDF knowledge graph engineering workflows utilizing Turtle representation. While our findings show that the latest commercial models outperform their forerunners in terms of proficiency with the Turtle language, they also reveal an apparent weakness. These models fall short when it comes to adhering strictly to the output formatting constraints, a crucial requirement in this context.
翻译:大型语言模型(LLM)正以迅猛速度发展,在自然语言处理和编程任务上取得显著进步。然而,它们在处理表示数据的正式语言(特别是在知识图谱工程领域)方面的能力仍未得到充分研究。为评估各类LLM的熟练程度,我们设计了一组五项任务,用于测试它们解析、理解、分析及创建以Turtle语法序列化的知识图谱的能力。这些任务各自具有不同的复杂度,并能随问题规模扩展,已集成到我们的自动评估系统LLM-KG-Bench中。评估涵盖了四种商用LLM——GPT-3.5、GPT-4、Claude 1.3和Claude 2.0,以及两种可免费访问的离线模型GPT4All Vicuna和GPT4All Falcon 13B。该分析深入揭示了LLM在利用Turtle表示的RDF知识图谱工程工作流程中的优势与不足。尽管我们的研究结果表明,最新商用模型在Turtle语言熟练度上优于前代,但也暴露出一个明显弱点:这些模型在严格遵循输出格式约束方面表现欠佳,而这一要求在此背景下至关重要。