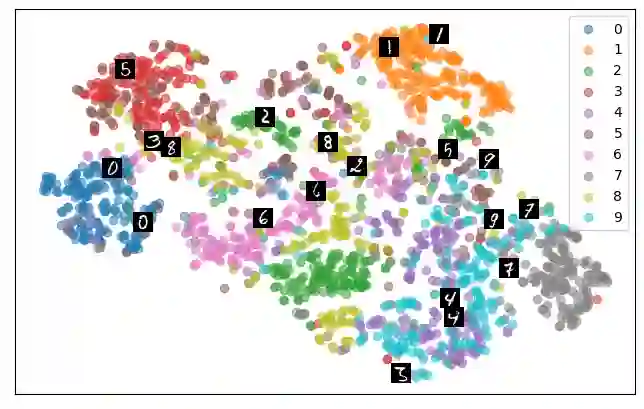
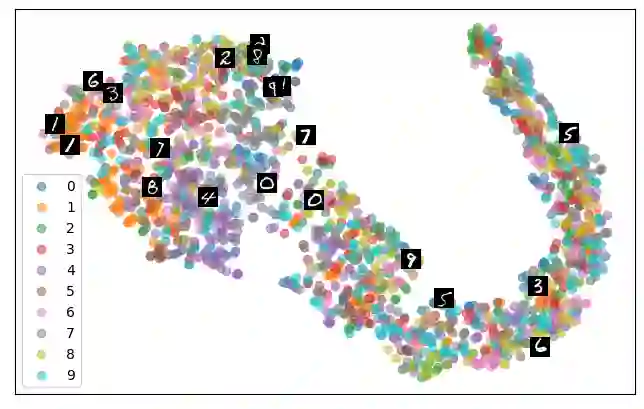
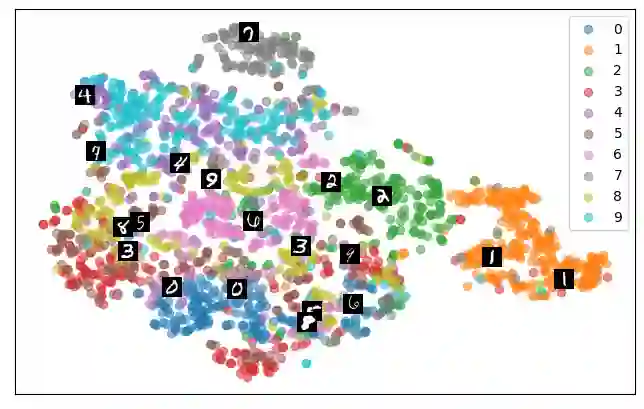
Self-supervised representation learning has seen remarkable progress in the last few years, with some of the recent methods being able to learn useful image representations without labels. These methods are trained using backpropagation, the de facto standard. Recently, Geoffrey Hinton proposed the forward-forward algorithm as an alternative training method. It utilizes two forward passes and a separate loss function for each layer to train the network without backpropagation. In this study, for the first time, we study the performance of forward-forward vs. backpropagation for self-supervised representation learning and provide insights into the learned representation spaces. Our benchmark employs four standard datasets, namely MNIST, F-MNIST, SVHN and CIFAR-10, and three commonly used self-supervised representation learning techniques, namely rotation, flip and jigsaw. Our main finding is that while the forward-forward algorithm performs comparably to backpropagation during (self-)supervised training, the transfer performance is significantly lagging behind in all the studied settings. This may be caused by a combination of factors, including having a loss function for each layer and the way the supervised training is realized in the forward-forward paradigm. In comparison to backpropagation, the forward-forward algorithm focuses more on the boundaries and drops part of the information unnecessary for making decisions which harms the representation learning goal. Further investigation and research are necessary to stabilize the forward-forward strategy for self-supervised learning, to work beyond the datasets and configurations demonstrated by Geoffrey Hinton.
翻译:自监督表示学习在过去几年取得了显著进展,其中一些最新方法无需标签即可学习有用的图像表示。这些方法均通过反向传播算法(事实上的标准方法)进行训练。近期,Geoffrey Hinton提出了前向-前向算法作为替代训练方法。该算法通过两次前向传播和各层独立的损失函数,实现在不依赖反向传播的情况下训练网络。本研究首次系统比较了前向-前向算法与反向传播算法在自监督表示学习中的性能,并深入解析了学习到的表示空间。我们基于MNIST、F-MNIST、SVHN和CIFAR-10四个标准数据集,以及旋转、翻转和拼图三种常用自监督表示学习技术进行基准测试。主要发现为:尽管前向-前向算法在(自)监督训练中表现与反向传播相当,但在所有实验设定下其迁移性能显著落后。这一现象可能由多因素共同导致,包括逐层损失函数的设置,以及前向-前向范式中监督训练的实现方式。相较于反向传播,前向-前向算法更聚焦于决策边界,丢弃了部分对决策非必要但不利于表示学习目标的信息。为将前向-前向策略稳定应用于自监督学习,使其超越Geoffrey Hinton演示的数据集和配置范围,仍需开展进一步研究与探索。