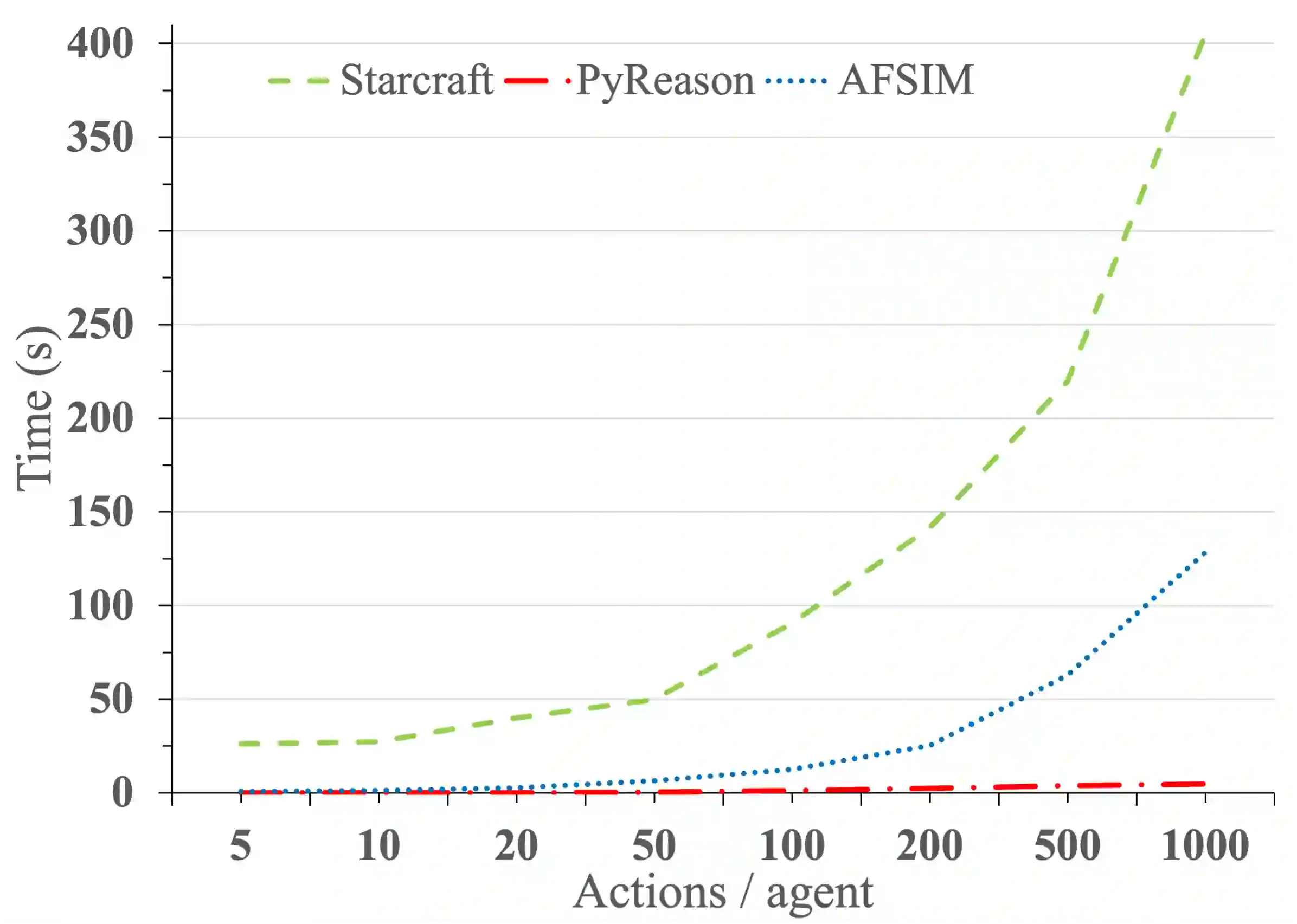
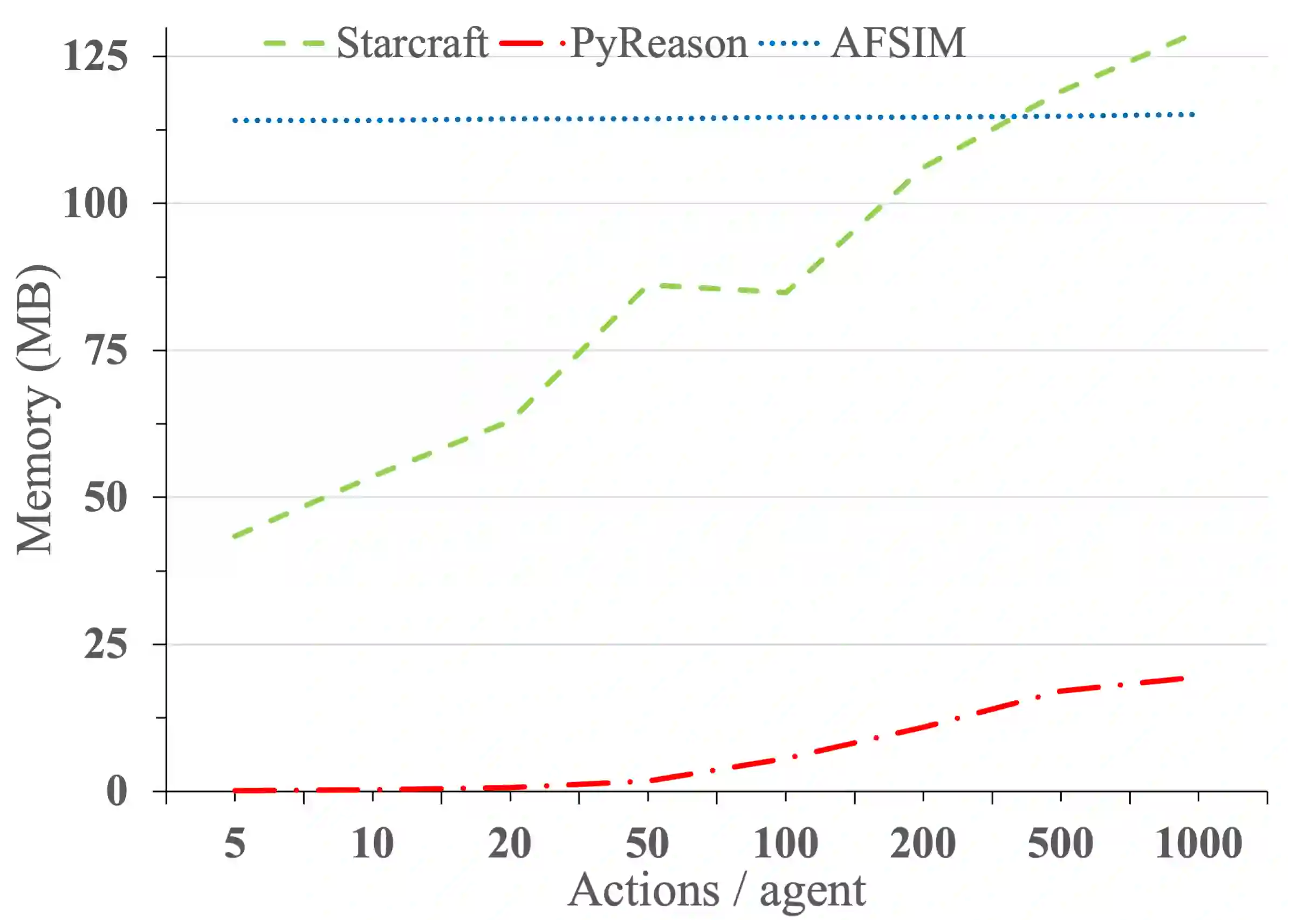
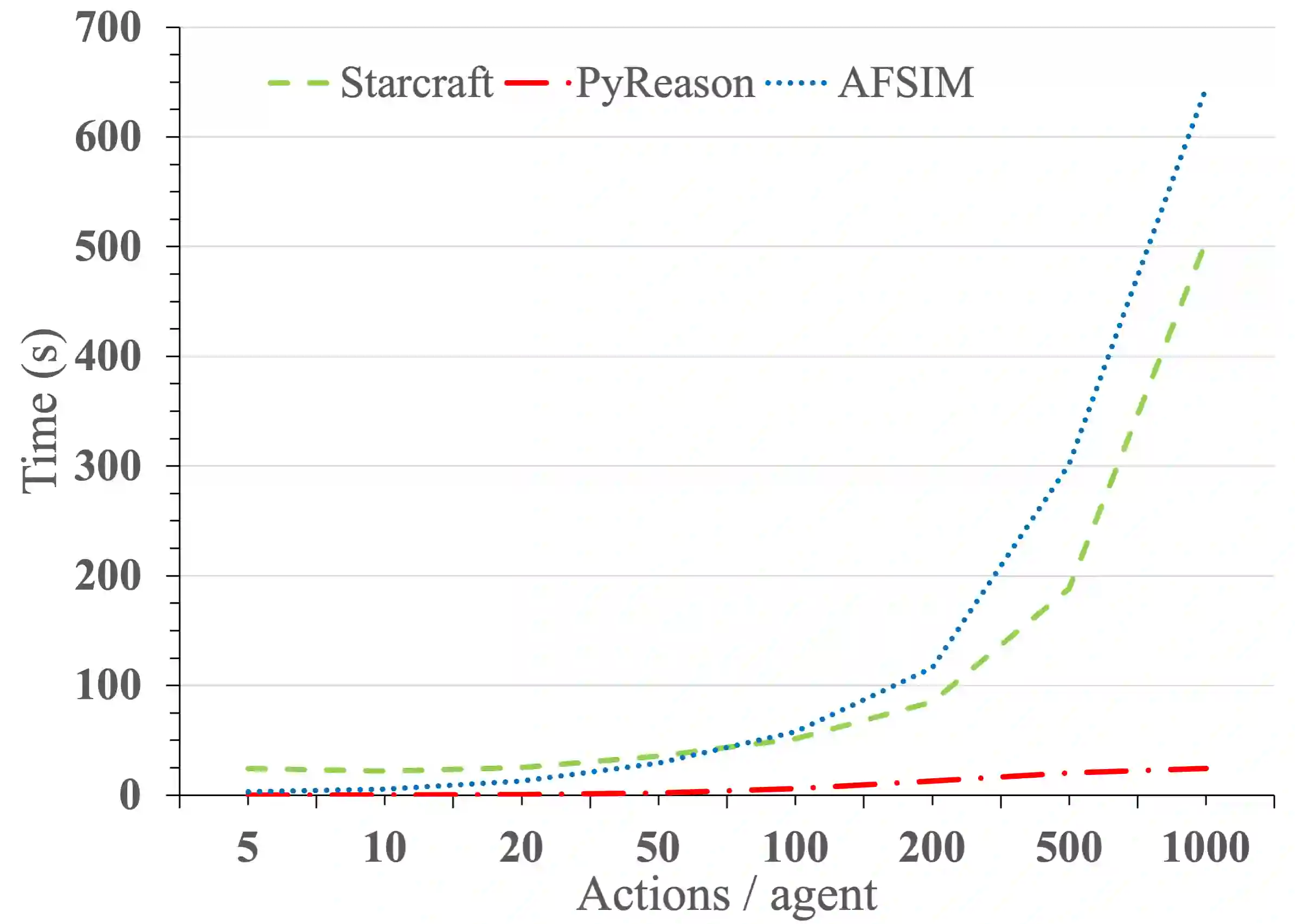
Recent advances in reinforcement learning (RL) have shown much promise across a variety of applications. However, issues such as scalability, explainability, and Markovian assumptions limit its applicability in certain domains. We observe that many of these shortcomings emanate from the simulator as opposed to the RL training algorithms themselves. As such, we propose a semantic proxy for simulation based on a temporal extension to annotated logic. In comparison with two high-fidelity simulators, we show up to three orders of magnitude speed-up while preserving the quality of policy learned in addition to showing the ability to model and leverage non-Markovian dynamics and instantaneous actions while providing an explainable trace describing the outcomes of the agent actions.
翻译:近期强化学习在各领域展现出显著潜力,但可扩展性、可解释性及马尔可夫假设等问题限制了其在某些场景的适用性。我们观察到,这些缺陷主要源于仿真器而非强化学习训练算法本身。为此,我们提出了一种基于带注释逻辑时态扩展的语义仿真代理。与两个高保真仿真器相比,本方法在保持所学策略质量的同时实现了高达三个数量级的加速,并能建模和利用非马尔可夫动态与瞬时动作,同时提供解释性轨迹来描述智能体动作的结果。