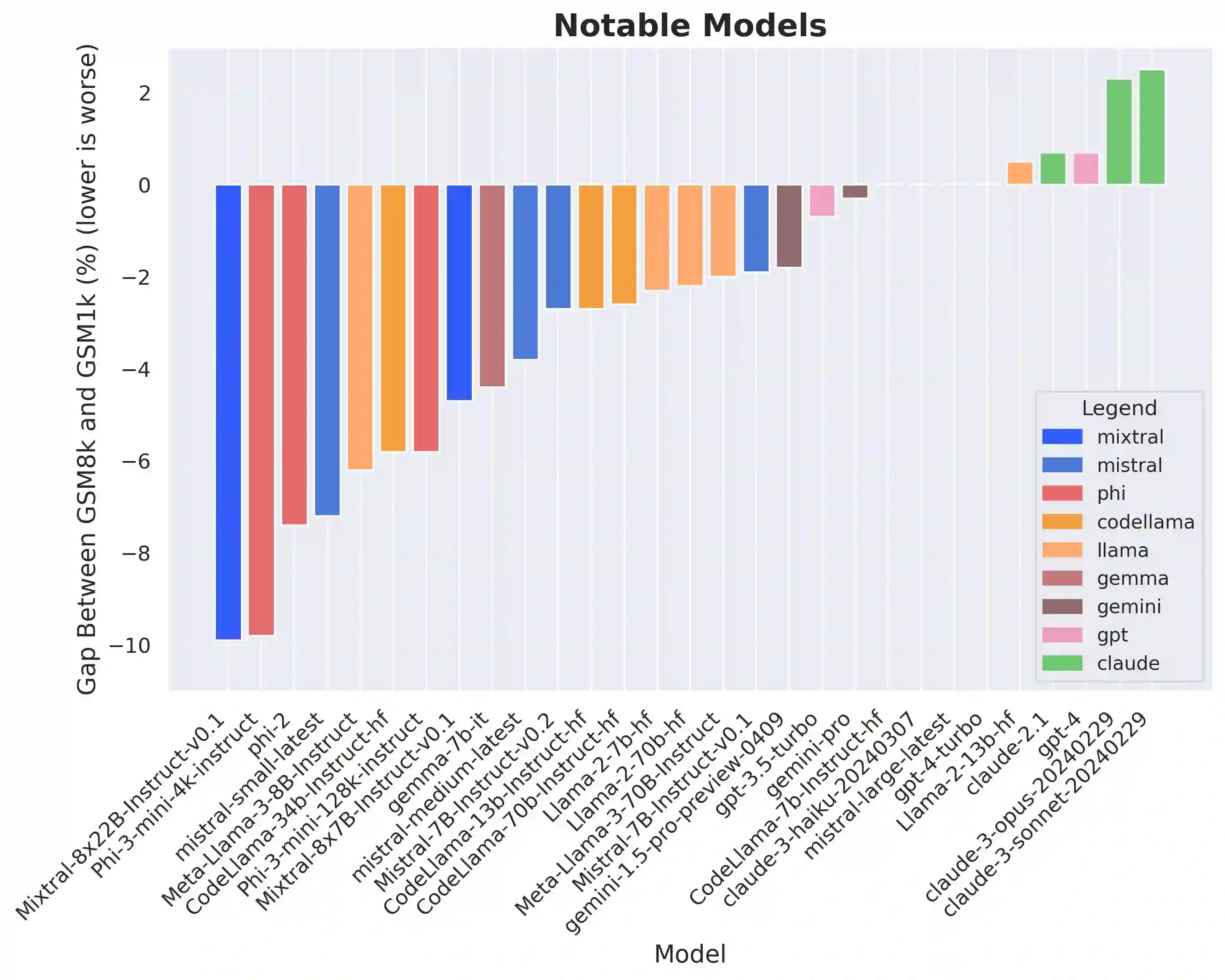
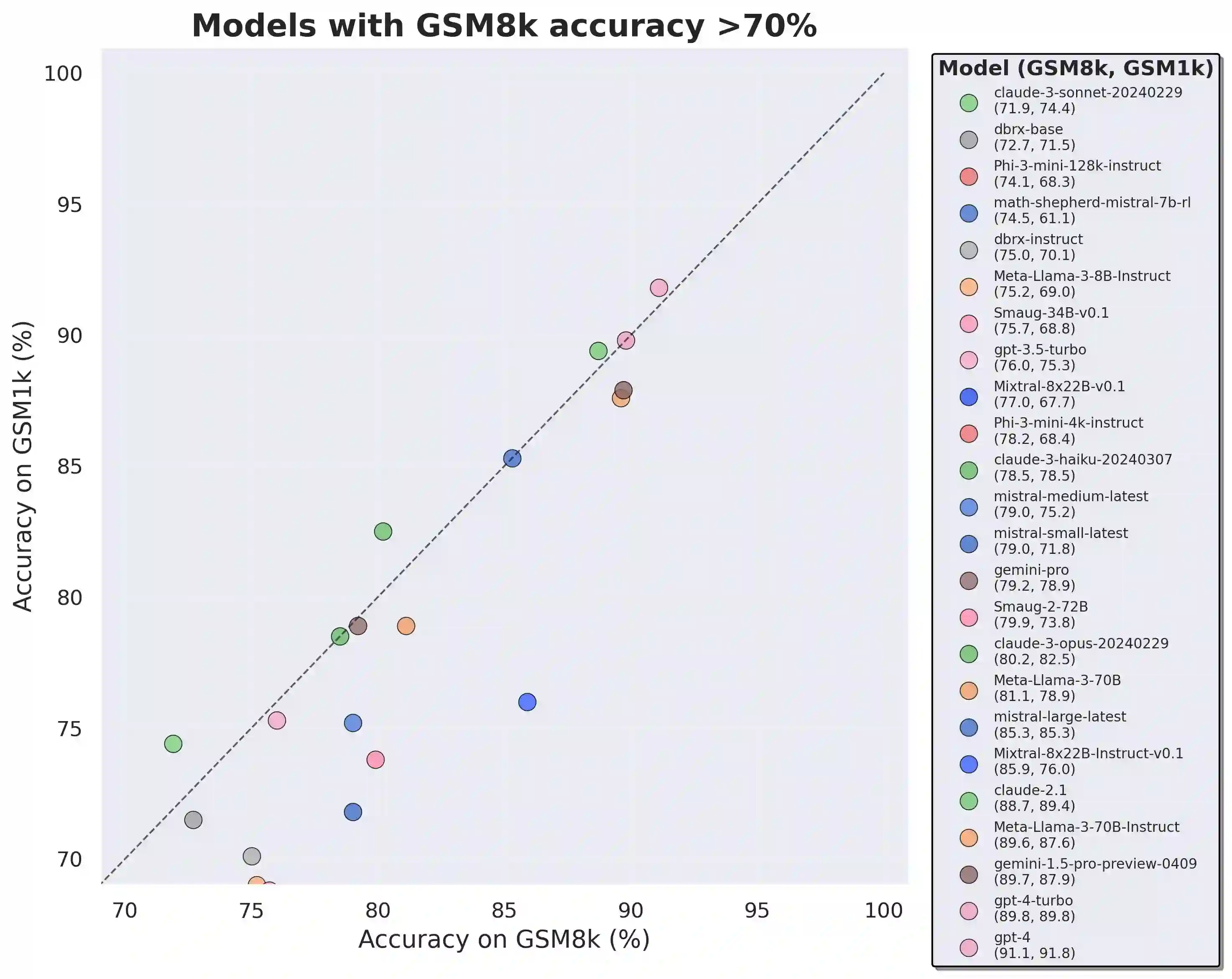
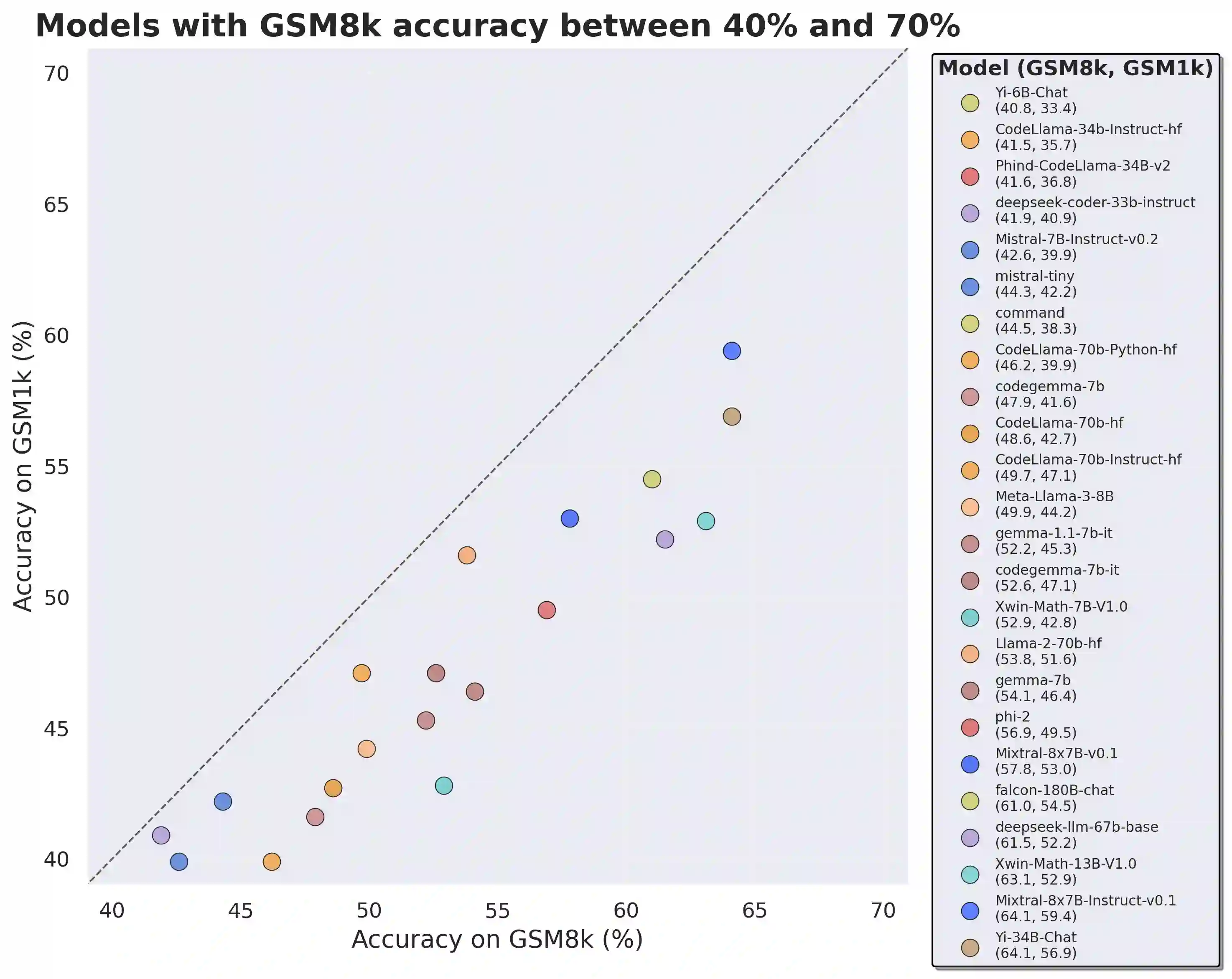
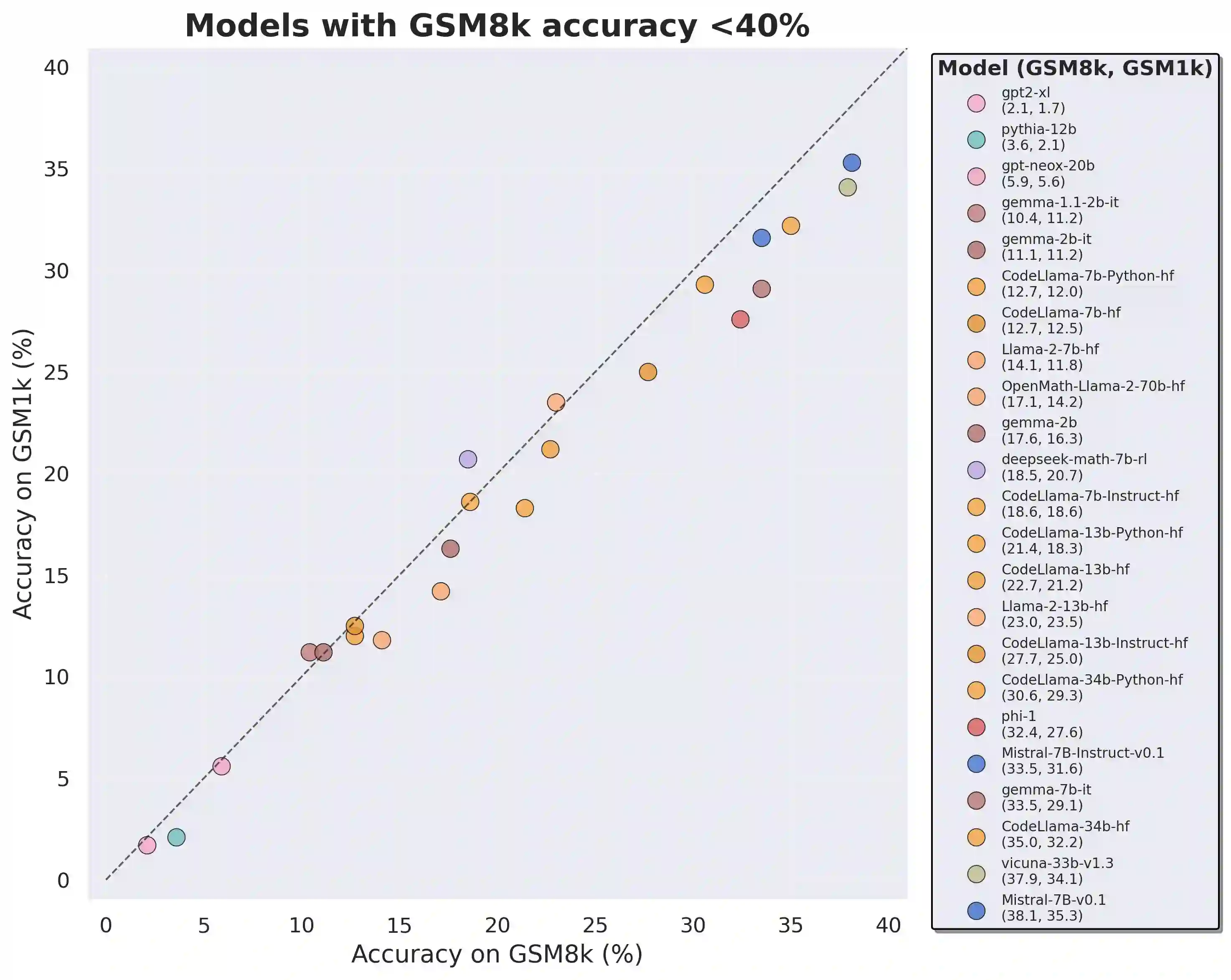
Large language models (LLMs) have achieved impressive success on many benchmarks for mathematical reasoning. However, there is growing concern that some of this performance actually reflects dataset contamination, where data closely resembling benchmark questions leaks into the training data, instead of true reasoning ability. To investigate this claim rigorously, we commission Grade School Math 1000 (GSM1k). GSM1k is designed to mirror the style and complexity of the established GSM8k benchmark, the gold standard for measuring elementary mathematical reasoning. We ensure that the two benchmarks are comparable across important metrics such as human solve rates, number of steps in solution, answer magnitude, and more. When evaluating leading open- and closed-source LLMs on GSM1k, we observe accuracy drops of up to 13%, with several families of models (e.g., Phi and Mistral) showing evidence of systematic overfitting across almost all model sizes. At the same time, many models, especially those on the frontier, (e.g., Gemini/GPT/Claude) show minimal signs of overfitting. Further analysis suggests a positive relationship (Spearman's r^2=0.32) between a model's probability of generating an example from GSM8k and its performance gap between GSM8k and GSM1k, suggesting that many models may have partially memorized GSM8k.
翻译:大型语言模型(LLMs)在众多数学推理基准测试中取得了令人瞩目的成功。然而,日益增长的担忧表明,部分性能实际上反映的是数据集污染——即与基准测试问题极为相似的数据泄露到训练数据中,而非真实的推理能力。为严谨探究这一论断,我们专门设计了小学数学千题集(GSM1k)。GSM1k旨在模仿权威基准测试GSM8k的风格与复杂度,该基准是衡量基础数学推理能力的黄金标准。我们确保这两个基准在人类解题率、解法步骤数、答案量级等关键指标上具有可比性。在评估领先的开源与闭源LLMs在GSM1k上的表现时,我们观察到准确率下降高达13%,其中多个模型系列(如Phi和Mistral)在几乎所有模型规模上均表现出系统性过拟合迹象。与此同时,许多模型,尤其是前沿模型(如Gemini/GPT/Claude),过拟合迹象微乎其微。进一步分析表明,模型生成GSM8k示例的概率与其在GSM8k与GSM1k之间的性能差距呈正相关(斯皮尔曼系数r²=0.32),暗示许多模型可能部分记忆了GSM8k。