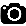Humans excel at transferring manipulation skills across diverse object shapes, poses, and appearances due to their understanding of semantic correspondences between different instances. To endow robots with a similar high-level understanding, we develop a Distilled Feature Field (DFF) for 3D scenes, leveraging large 2D vision models to distill semantic features from multiview images. While current research demonstrates advanced performance in reconstructing DFFs from dense views, the development of learning a DFF from sparse views is relatively nascent, despite its prevalence in numerous manipulation tasks with fixed cameras. In this work, we introduce SparseDFF, a novel method for acquiring view-consistent 3D DFFs from sparse RGBD observations, enabling one-shot learning of dexterous manipulations that are transferable to novel scenes. Specifically, we map the image features to the 3D point cloud, allowing for propagation across the 3D space to establish a dense feature field. At the core of SparseDFF is a lightweight feature refinement network, optimized with a contrastive loss between pairwise views after back-projecting the image features onto the 3D point cloud. Additionally, we implement a point-pruning mechanism to augment feature continuity within each local neighborhood. By establishing coherent feature fields on both source and target scenes, we devise an energy function that facilitates the minimization of feature discrepancies w.r.t. the end-effector parameters between the demonstration and the target manipulation. We evaluate our approach using a dexterous hand, mastering real-world manipulations on both rigid and deformable objects, and showcase robust generalization in the face of object and scene-context variations.
翻译:人类通过理解不同实例间的语义对应关系,擅长在多样的物体形状、姿态和外观间迁移操作技能。为使机器人具备类似的高级理解能力,我们开发了一种面向三维场景的蒸馏特征场(DFF),利用大规模二维视觉模型从多视角图像中蒸馏语义特征。尽管现有研究在从密集视角重建DFF方面展现出先进性能,但从稀疏视角学习DFF的研究仍处于起步阶段——尽管这在众多使用固定摄像头的操作任务中普遍存在。本文提出SparseDFF——一种从稀疏RGBD观测中获取视图一致性三维DFF的新方法,能够实现可迁移至新场景的灵巧操作一次性学习。具体而言,我们将图像特征映射至三维点云,实现特征在三维空间中的传播以构建密集特征场。SparseDFF的核心是一个轻量级特征精炼网络,通过将图像特征反投影至三维点云后,利用视图对间的对比损失进行优化。此外,我们引入点剪枝机制以增强各局部邻域内的特征连续性。通过在源场景与目标场景上建立一致的特征场,我们设计了一个能量函数,可最小化演示操作与目标操作间端效应器参数的特征差异。我们使用灵巧手对该方法进行验证,掌握了刚性物体与可变形物体的真实世界操作能力,并在物体与场景上下文变化中展现出鲁棒的泛化性能。