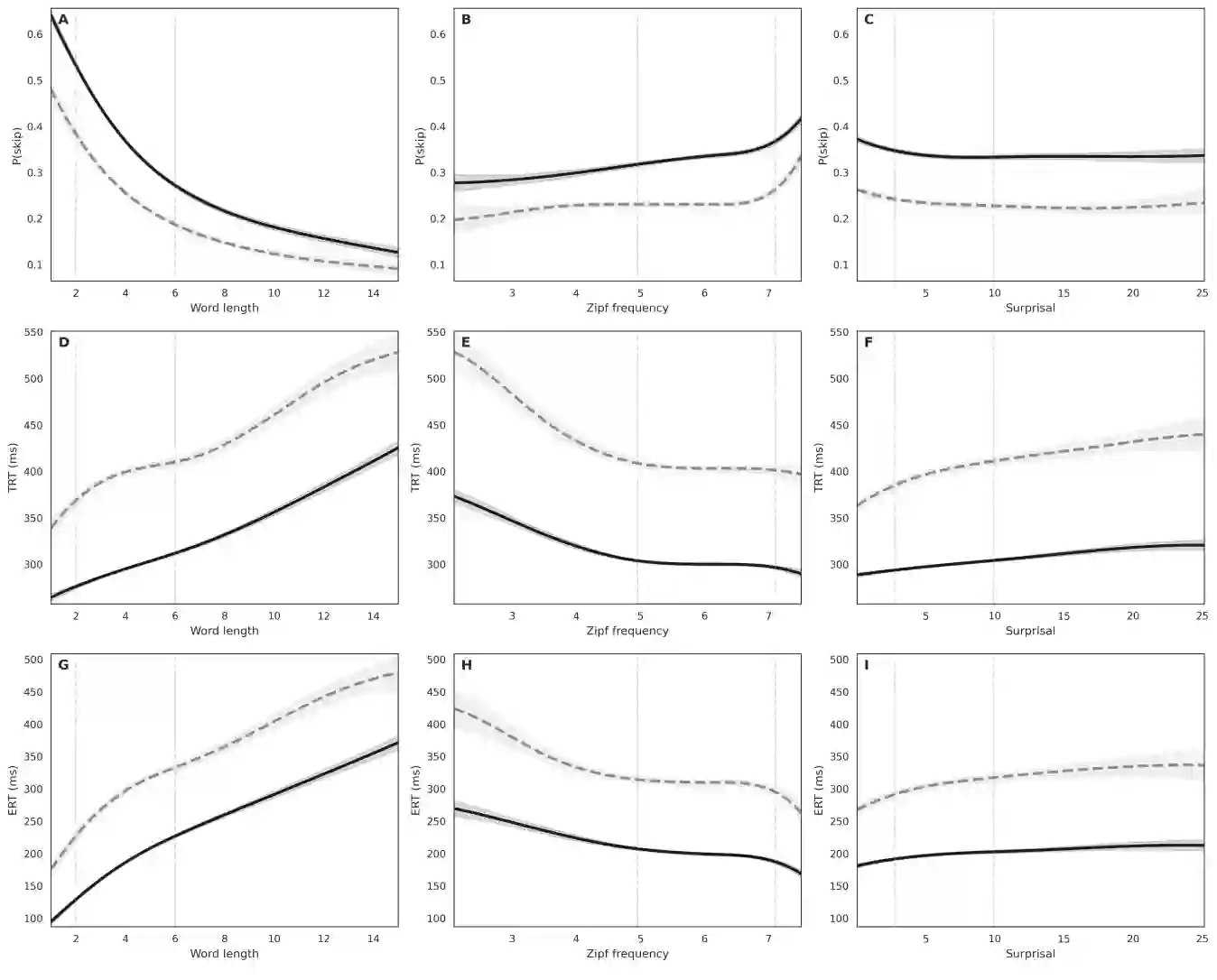
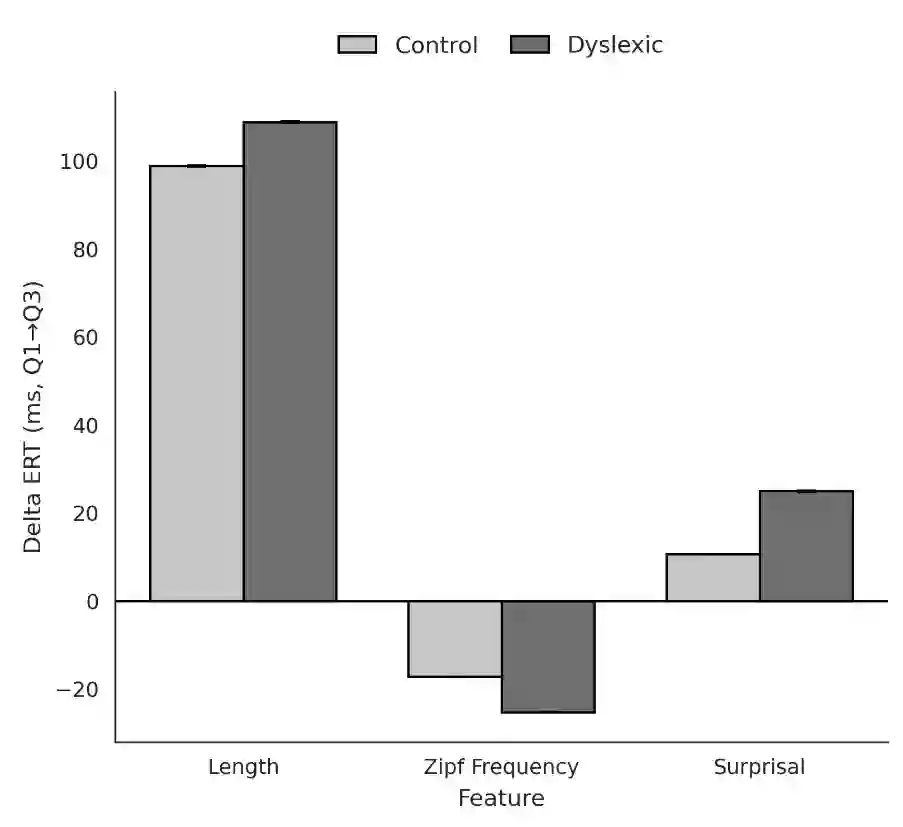
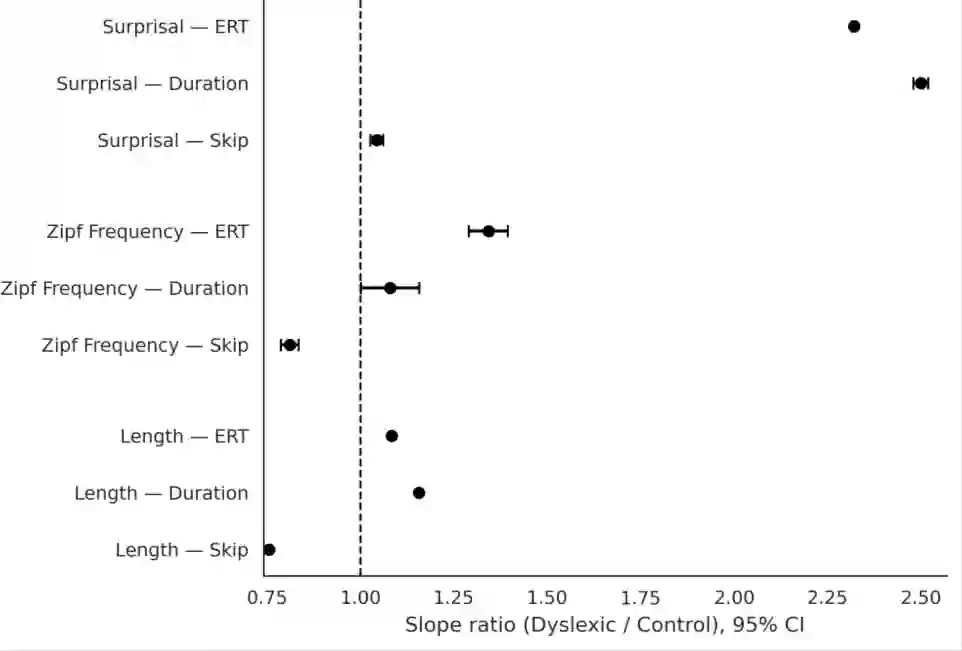
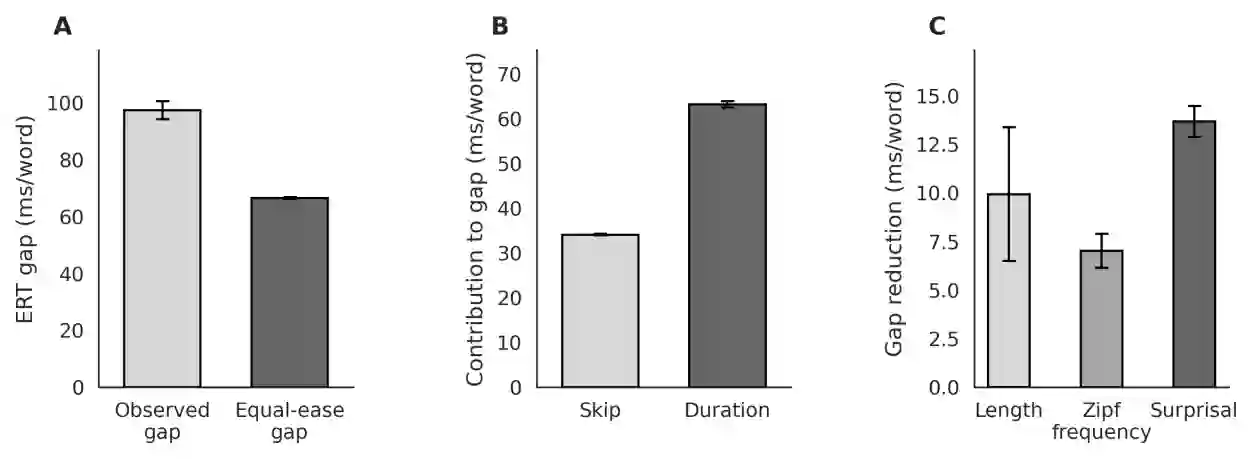
We ask where, and under what conditions, dyslexic reading costs arise in a large-scale naturalistic reading dataset. Using eye-tracking aligned to word-level features (word length, frequency, and predictability), we model how each feature influences dyslexic time costs. We find that all three features robustly change reading times in both typical and dyslexic readers, and that dyslexic readers show stronger sensitivities to each, especially predictability. Counterfactual manipulations of these features substantially narrow the dyslexic-control gap by about one third, with predictability showing the strongest effect, followed by length and frequency. These patterns align with dyslexia theories that posit heightened demands on linguistic working memory and phonological encoding, and they motivate further work on lexical complexity and parafoveal preview benefits to explain the remaining gap. In short, we quantify when extra dyslexic costs arise, how large they are, and offer actionable guidance for interventions and computational models for dyslexics.
翻译:本研究旨在探究大规模自然阅读数据中,阅读障碍相关的额外时间成本在何处及何种条件下产生。通过将眼动追踪数据与词汇层面特征(词长、词频及可预测性)对齐,我们建模分析了各特征对阅读障碍时间成本的影响。研究发现,所有三个特征均显著影响典型读者与阅读障碍者的阅读时间,且阅读障碍者对每个特征(尤其是可预测性)表现出更强的敏感性。对这些特征的反事实模拟操作可将阅读障碍者与对照组间的差距缩小约三分之一,其中可预测性影响最为显著,其次是词长与词频。这些模式与强调语言工作记忆及语音编码负荷增加的阅读障碍理论相符,并为进一步通过词汇复杂度与副中央凹预视效益研究解释剩余差距提供了方向。简言之,本研究量化了阅读障碍额外成本的出现时机与规模,并为针对阅读障碍者的干预措施及计算模型提供了可操作的指导。