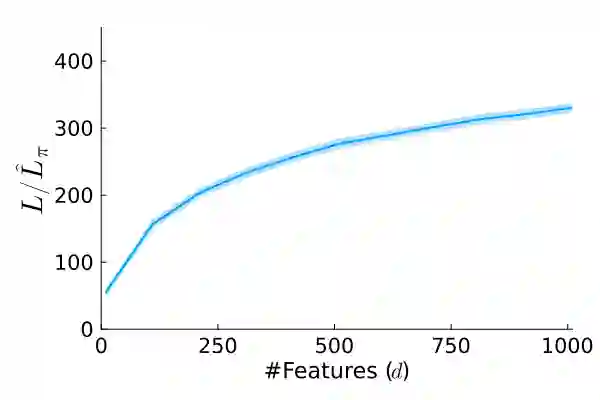
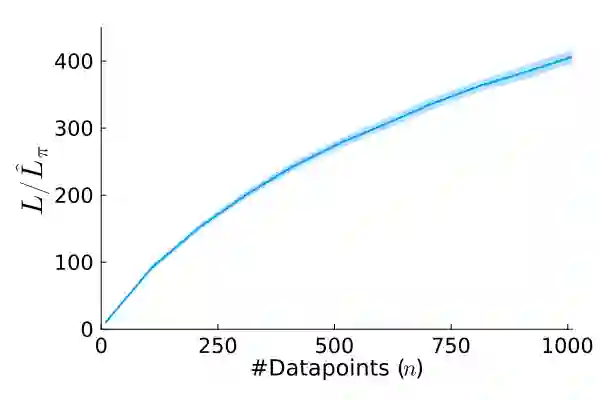
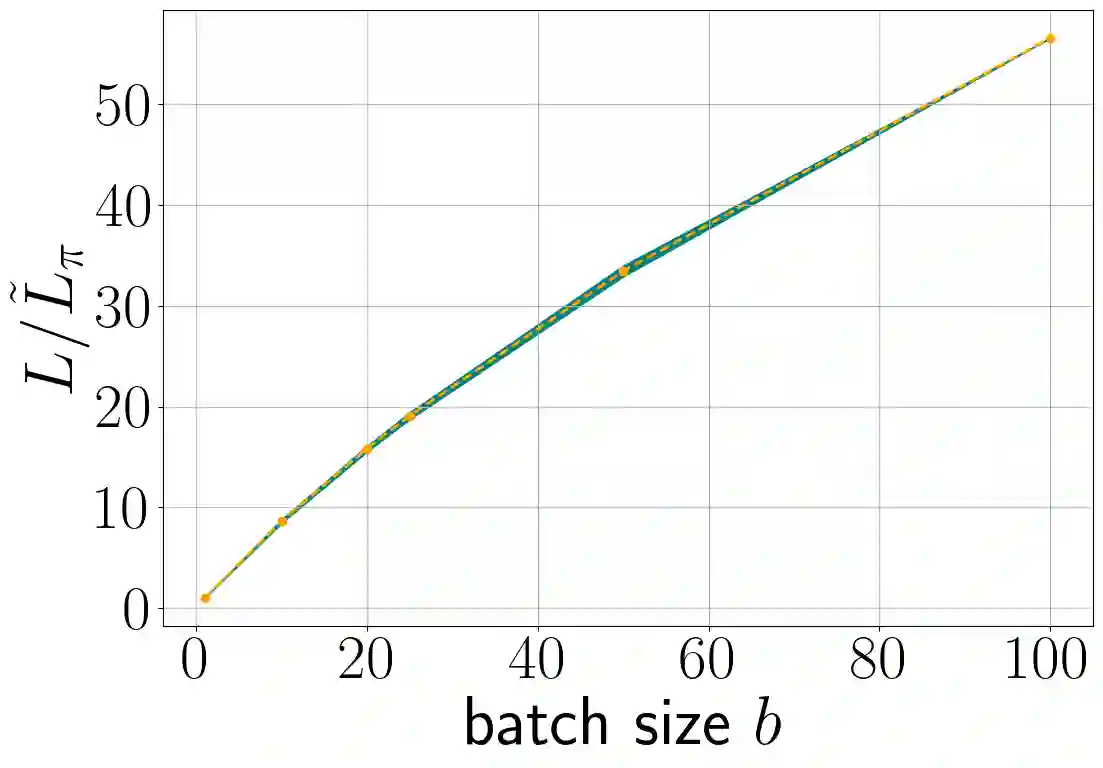
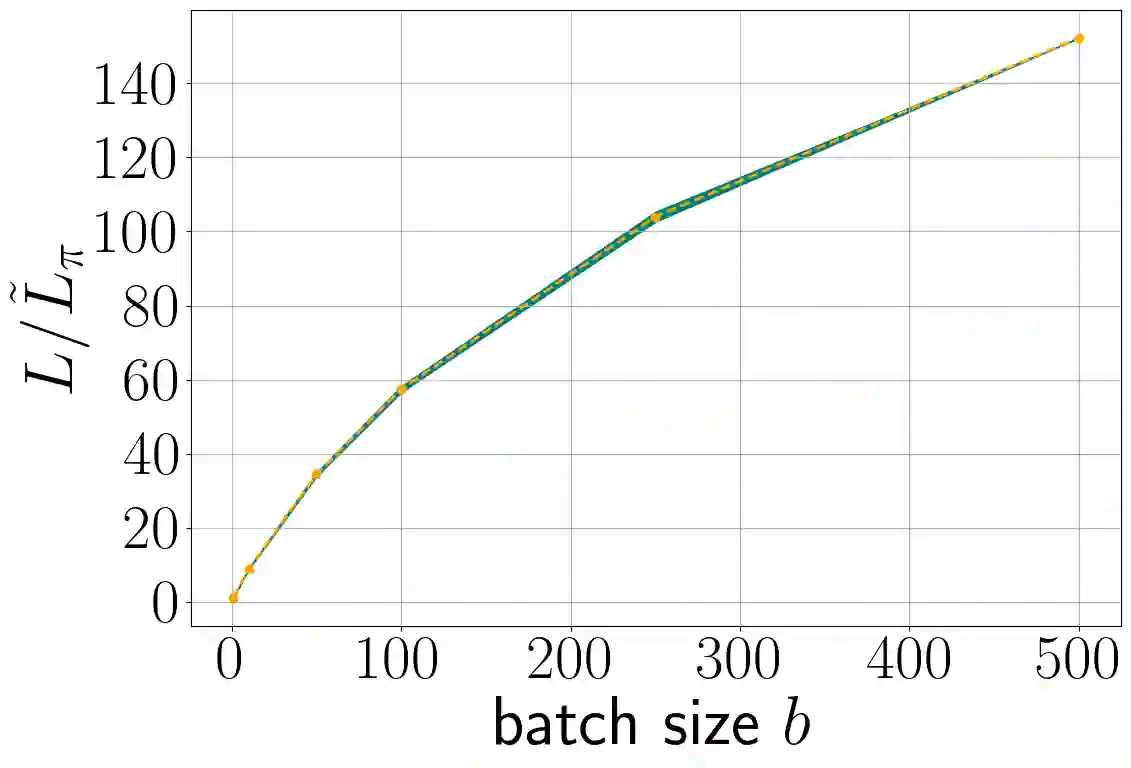
Stochastic gradient descent (SGD) is perhaps the most prevalent optimization method in modern machine learning. Contrary to the empirical practice of sampling from the datasets without replacement and with (possible) reshuffling at each epoch, the theoretical counterpart of SGD usually relies on the assumption of sampling with replacement. It is only very recently that SGD with sampling without replacement -- shuffled SGD -- has been analyzed. For convex finite sum problems with $n$ components and under the $L$-smoothness assumption for each component function, there are matching upper and lower bounds, under sufficiently small -- $\mathcal{O}(\frac{1}{nL})$ -- step sizes. Yet those bounds appear too pessimistic -- in fact, the predicted performance is generally no better than for full gradient descent -- and do not agree with the empirical observations. In this work, to narrow the gap between the theory and practice of shuffled SGD, we sharpen the focus from general finite sum problems to empirical risk minimization with linear predictors. This allows us to take a primal-dual perspective and interpret shuffled SGD as a primal-dual method with cyclic coordinate updates on the dual side. Leveraging this perspective, we prove fine-grained complexity bounds that depend on the data matrix and are never worse than what is predicted by the existing bounds. Notably, our bounds predict much faster convergence than the existing analyses -- by a factor of the order of $\sqrt{n}$ in some cases. We empirically demonstrate that on common machine learning datasets our bounds are indeed much tighter. We further extend our analysis to nonsmooth convex problems and more general finite-sum problems, with similar improvements.
翻译:随机梯度下降(SGD)或许是现代机器学习中最主流的优化方法。与实践中无放回采样且每轮可能重新打乱数据集的惯常做法不同,SGD的理论分析通常依赖于有放回采样的假设。直到最近,无放回采样的SGD(即混洗SGD)才开始被系统分析。对于包含n个分量且每个分量函数满足L-光滑性的凸有限和问题,在充分小(𝒪(1/(nL)))的步长下,已有匹配的上界和下界。然而这些界限过于悲观——事实上,其预测性能通常不优于全梯度下降——且与实验观察不符。为弥合混洗SGD理论与实践的差距,本文将关注点从一般有限和问题聚焦到线性预测器的经验风险最小化。通过采用原始-对偶视角,我们将混洗SGD重新解释为一种对偶侧采用循环坐标更新的原始-对偶方法。基于该视角,我们证明了依赖数据矩阵的细粒度复杂度界限,其保守性始终不劣于现有理论预测。值得注意的是,我们的界限预测的收敛速度远快于现有分析——某些情况下加速因子可达√n量级。实验表明,在常见机器学习数据集上我们的界限确实更加严格。我们进一步将该分析推广到非光滑凸问题及更一般的有限和问题,并获得了类似的改进效果。