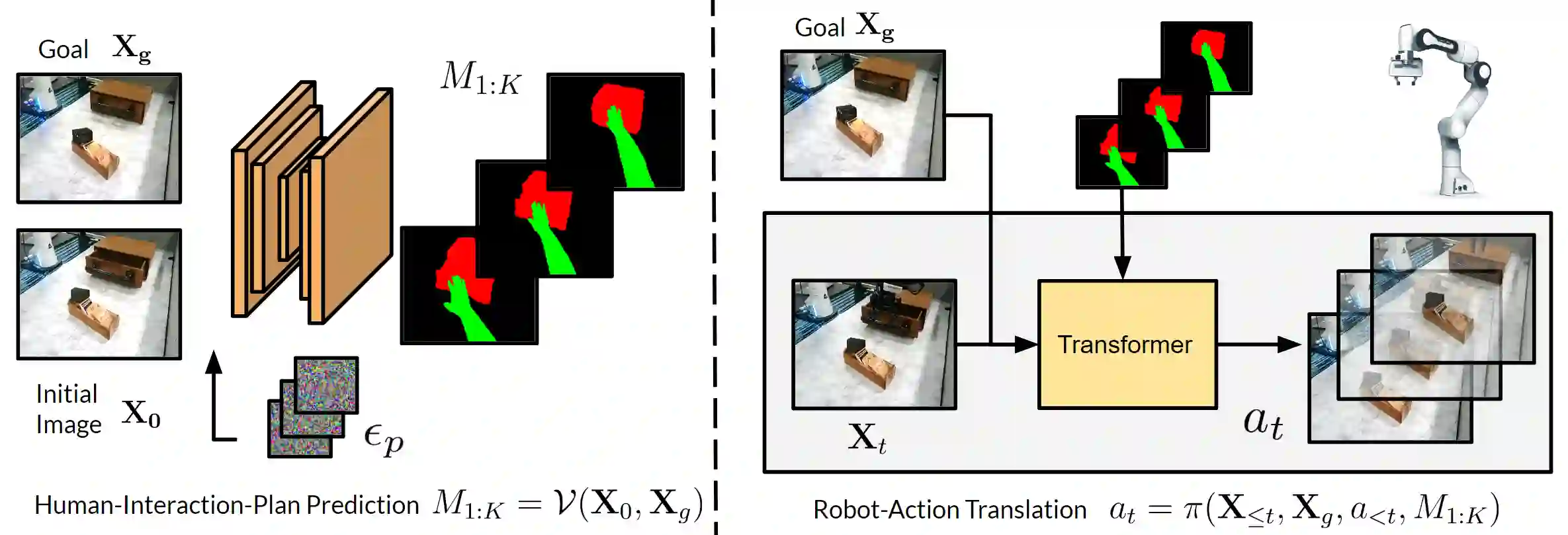
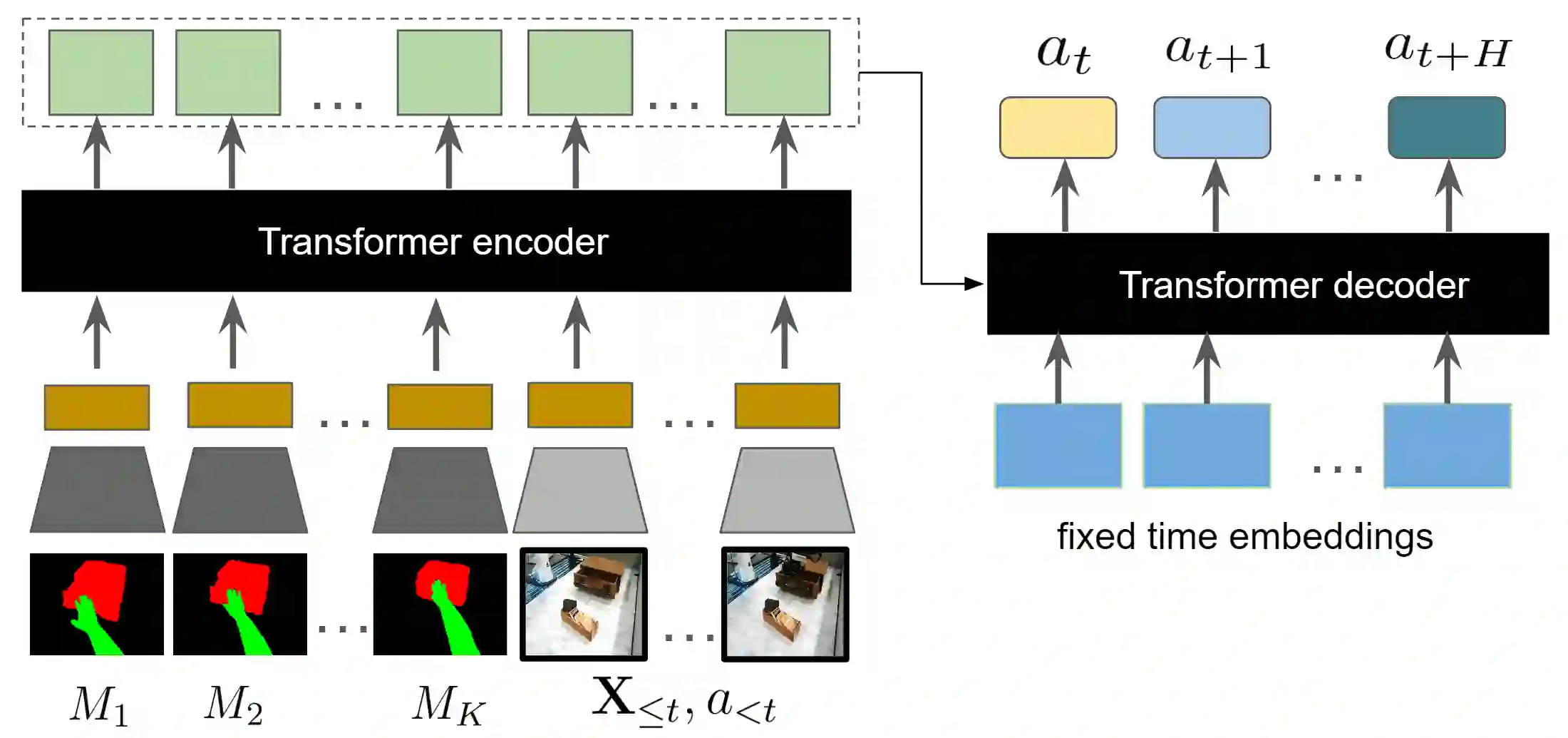
We pursue the goal of developing robots that can interact zero-shot with generic unseen objects via a diverse repertoire of manipulation skills and show how passive human videos can serve as a rich source of data for learning such generalist robots. Unlike typical robot learning approaches which directly learn how a robot should act from interaction data, we adopt a factorized approach that can leverage large-scale human videos to learn how a human would accomplish a desired task (a human plan), followed by translating this plan to the robots embodiment. Specifically, we learn a human plan predictor that, given a current image of a scene and a goal image, predicts the future hand and object configurations. We combine this with a translation module that learns a plan-conditioned robot manipulation policy, and allows following humans plans for generic manipulation tasks in a zero-shot manner with no deployment-time training. Importantly, while the plan predictor can leverage large-scale human videos for learning, the translation module only requires a small amount of in-domain data, and can generalize to tasks not seen during training. We show that our learned system can perform over 16 manipulation skills that generalize to 40 objects, encompassing 100 real-world tasks for table-top manipulation and diverse in-the-wild manipulation. https://homangab.github.io/hopman/
翻译:我们致力于开发能够以零样本方式通过多样化操控技能与未见过的通用物体进行交互的机器人,并展示被动人类视频如何作为学习此类通用机器人的丰富数据源。不同于典型的机器人学习方法(直接从交互数据中学习机器人应如何行动),我们采用分解式方法,利用大规模人类视频学习人类如何完成期望任务(人类计划),然后将该计划转化为机器人本体执行。具体而言,我们训练一个人类计划预测器,给定当前场景图像和目标图像,预测未来手部和物体的位形。我们将其与一个翻译模块结合,该模块学习基于计划的机器人操控策略,并能在零样本条件下(无需部署时训练)遵循人类计划执行通用操控任务。重要的是,计划预测器可利用大规模人类视频进行学习,而翻译模块仅需少量领域内数据即可泛化至训练中未见过的任务。实验表明,我们的学习系统能够执行超过16种操控技能,泛化至40个物体,涵盖100项真实世界任务(包括桌面操控与多样化野外操控)。https://homangab.github.io/hopman/