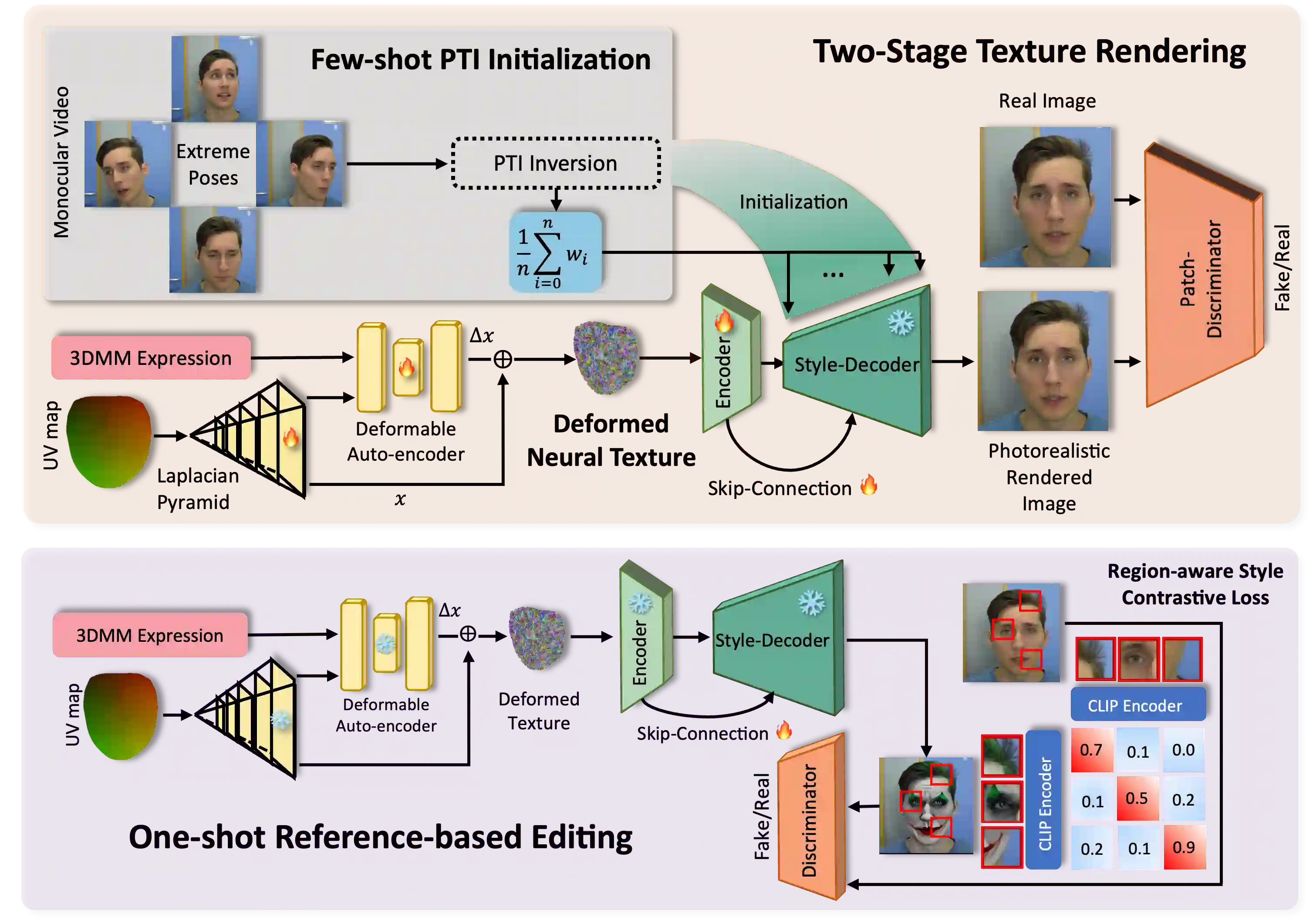
Artistic video portrait generation is a significant and sought-after task in the fields of computer graphics and vision. While various methods have been developed that integrate NeRFs or StyleGANs with instructional editing models for creating and editing drivable portraits, these approaches face several challenges. They often rely heavily on large datasets, require extensive customization processes, and frequently result in reduced image quality. To address the above problems, we propose the Efficient Monotonic Video Style Avatar (Emo-Avatar) through deferred neural rendering that enhances StyleGAN's capacity for producing dynamic, drivable portrait videos. We proposed a two-stage deferred neural rendering pipeline. In the first stage, we utilize few-shot PTI initialization to initialize the StyleGAN generator through several extreme poses sampled from the video to capture the consistent representation of aligned faces from the target portrait. In the second stage, we propose a Laplacian pyramid for high-frequency texture sampling from UV maps deformed by dynamic flow of expression for motion-aware texture prior integration to provide torso features to enhance StyleGAN's ability to generate complete and upper body for portrait video rendering. Emo-Avatar reduces style customization time from hours to merely 5 minutes compared with existing methods. In addition, Emo-Avatar requires only a single reference image for editing and employs region-aware contrastive learning with semantic invariant CLIP guidance, ensuring consistent high-resolution output and identity preservation. Through both quantitative and qualitative assessments, Emo-Avatar demonstrates superior performance over existing methods in terms of training efficiency, rendering quality and editability in self- and cross-reenactment.
翻译:艺术化视频肖像生成是计算机图形学与视觉领域一项重要且广受关注的任务。尽管现有方法通过将NeRF或StyleGAN与指令性编辑模型相结合,实现了可驱动肖像的创建与编辑,但这些方法仍面临诸多挑战:它们通常严重依赖大规模数据集、需要大量定制化处理流程,且常导致图像质量下降。针对上述问题,我们提出基于延迟神经渲染的高效单目视频风格化虚拟化身(Emo-Avatar),通过增强StyleGAN生成动态可驱动肖像视频的能力。我们设计了一个两阶段延迟神经渲染流水线:第一阶段,利用少样本PTI初始化,通过从视频中采样的多个极端姿态初始化StyleGAN生成器,以捕获目标肖像中对齐人脸的一致性表征;第二阶段,引入拉普拉斯金字塔,从经表情动态流形变后的UV贴图中进行高频纹理采样,实现运动感知纹理先验融合,为StyleGAN提供躯干特征以增强其生成完整上半身肖像视频的能力。与现有方法相比,Emo-Avatar将风格定制时间从数小时缩短至仅5分钟。此外,Emo-Avatar仅需单张参考图像即可完成编辑,并结合区域感知对比学习与语义不变CLIP引导,确保输出高分辨率结果并保持身份一致性。通过定量与定性评估,Emo-Avatar在训练效率、渲染质量及自驱动/跨驱动编辑能力上均显著优于现有方法。