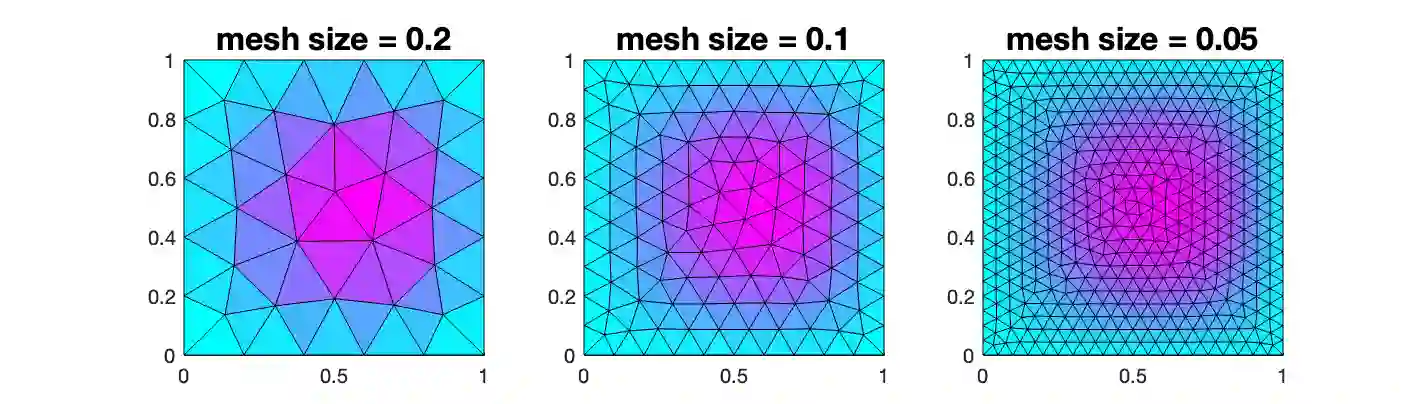
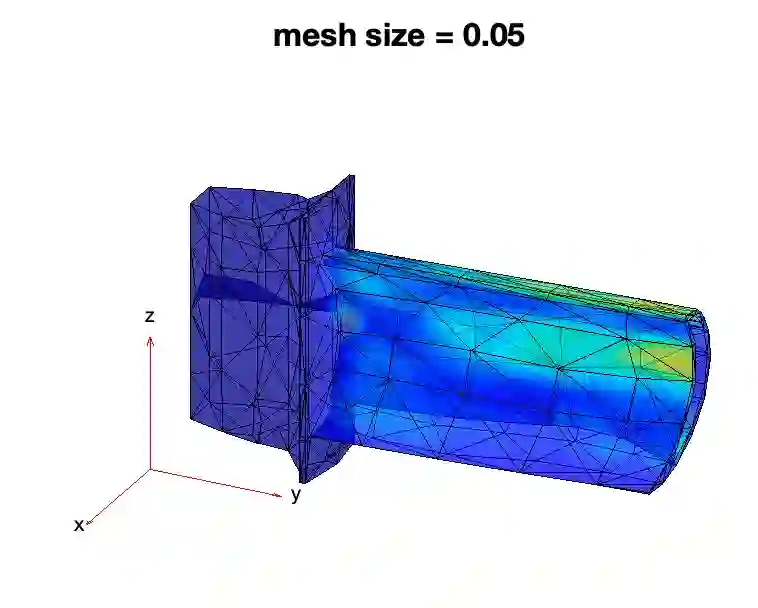
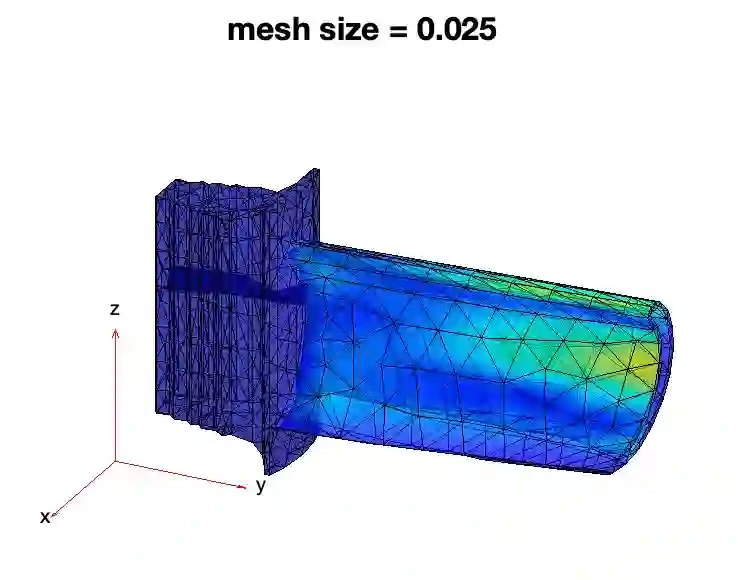
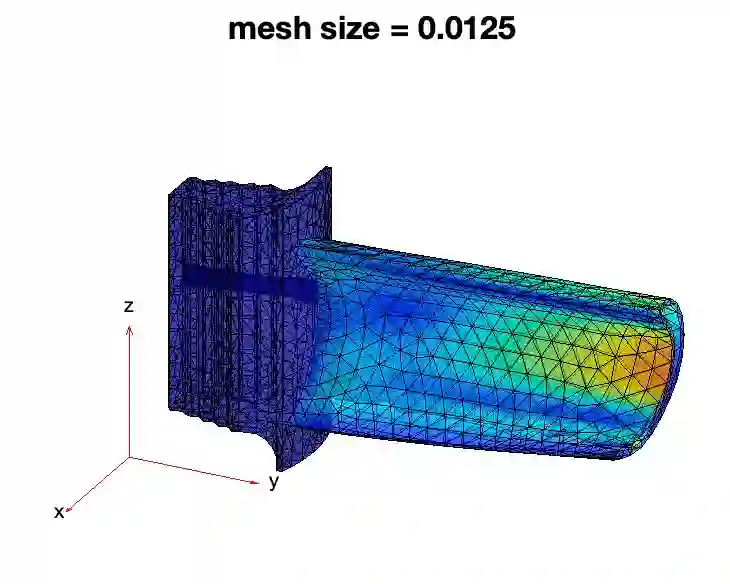
In an era where scientific experiments can be very costly, multi-fidelity emulators provide a useful tool for cost-efficient predictive scientific computing. For scientific applications, the experimenter is often limited by a tight computational budget, and thus wishes to (i) maximize predictive power of the multi-fidelity emulator via a careful design of experiments, and (ii) ensure this model achieves a desired error tolerance with some notion of confidence. Existing design methods, however, do not jointly tackle objectives (i) and (ii). We propose a novel stacking design approach that addresses both goals. A multi-level reproducing kernel Hilbert space (RKHS) interpolator is first introduced to build the emulator, under which our stacking design provides a sequential approach for designing multi-fidelity runs such that a desired prediction error of $\epsilon > 0$ is met under regularity assumptions. We then prove a novel cost complexity theorem that, under this multi-level interpolator, establishes a bound on the computation cost (for training data simulation) needed to achieve a prediction bound of $\epsilon$. This result provides novel insights on conditions under which the proposed multi-fidelity approach improves upon a conventional RKHS interpolator which relies on a single fidelity level. Finally, we demonstrate the effectiveness of stacking designs in a suite of simulation experiments and an application to finite element analysis.
翻译:在科学实验成本极为高昂的时代,多保真度仿真器为成本高效的预测性科学计算提供了实用工具。针对科学应用场景,实验者常受限于紧凑的计算预算,因此期望:(i) 通过精心设计的实验方案最大化多保真度仿真器的预测能力;(ii) 确保该模型以一定置信度达到预期的误差容限。然而现有设计方法无法同时解决目标(i)与(ii)。本文提出一种新颖的堆叠设计方法,可同时实现这两项目标。首先引入多水平再生核希尔伯特空间(RKHS)插值器构建仿真器,在此框架下,我们的堆叠设计提供了一种序贯方法,在正则性假设下通过设计多保真度运行实现预期预测误差$\epsilon > 0$。随后我们证明了一个新颖的成本复杂度定理,该定理在此多水平插值器框架下,建立了达到预测界限$\epsilon$所需的计算成本(用于训练数据模拟)的上界。该结果为多保真度方法相比传统单保真度水平RKHS插值器的改进条件提供了新见解。最后,我们通过模拟实验套件和有限元分析应用展示了堆叠设计的有效性。