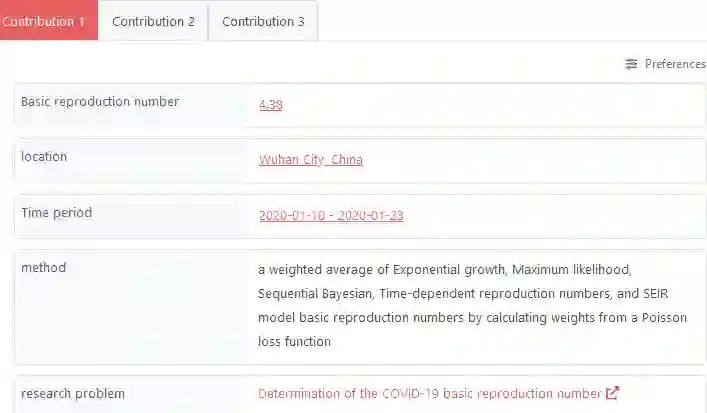
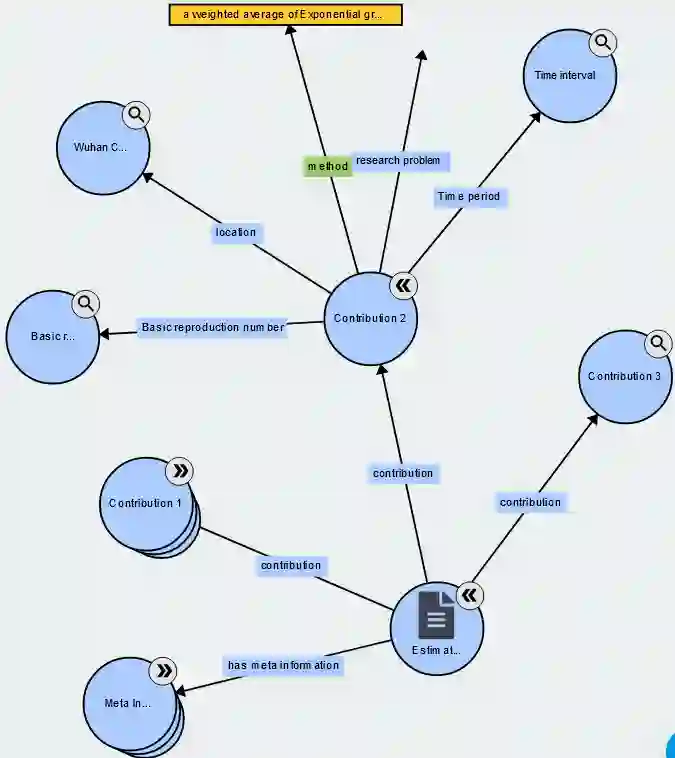
There have been many recent investigations into prompt-based training of transformer language models for new text genres in low-resource settings. The prompt-based training approach has been found to be effective in generalizing pre-trained or fine-tuned models for transfer to resource-scarce settings. This work, for the first time, reports results on adopting prompt-based training of transformers for \textit{scholarly knowledge graph object prediction}. The work is unique in the following two main aspects. 1) It deviates from the other works proposing entity and relation extraction pipelines for predicting objects of a scholarly knowledge graph. 2) While other works have tested the method on text genera relatively close to the general knowledge domain, we test the method for a significantly different domain, i.e. scholarly knowledge, in turn testing the linguistic, probabilistic, and factual generalizability of these large-scale transformer models. We find that (i) per expectations, transformer models when tested out-of-the-box underperform on a new domain of data, (ii) prompt-based training of the models achieve performance boosts of up to 40\% in a relaxed evaluation setting, and (iii) testing the models on a starkly different domain even with a clever training objective in a low resource setting makes evident the domain knowledge capture gap offering an empirically-verified incentive for investing more attention and resources to the scholarly domain in the context of transformer models.
翻译:近年来,针对低资源环境下新文本类型的Transformer语言模型基于提示的训练进行了大量研究。研究发现,基于提示的训练方法能有效泛化预训练或微调模型,使其迁移至资源稀缺场景。本研究首次报告了将基于提示的Transformer训练应用于《学术知识图谱对象预测》的结果。该研究的独特性体现在以下两方面:1)它偏离了其他通过实体与关系提取流水线预测学术知识图谱对象的研究;2)虽然其他研究在接近通用知识领域的文本类型上测试了该方法,我们则在显著不同的领域(即学术知识)上进行测试,从而检验这些大规模Transformer模型在语言、概率和事实层面的泛化能力。我们发现:(i)与预期一致,Transformer模型在开箱即用情况下对新数据域表现不佳;(ii)基于提示的模型训练在宽松评估设置下性能提升高达40%;(iii)即使在低资源环境下采用巧妙训练目标,在截然不同的领域上测试模型仍暴露出领域知识捕获差距,这为在Transformer模型背景下加大对学术领域的关注与资源投入提供了经验验证的动力。