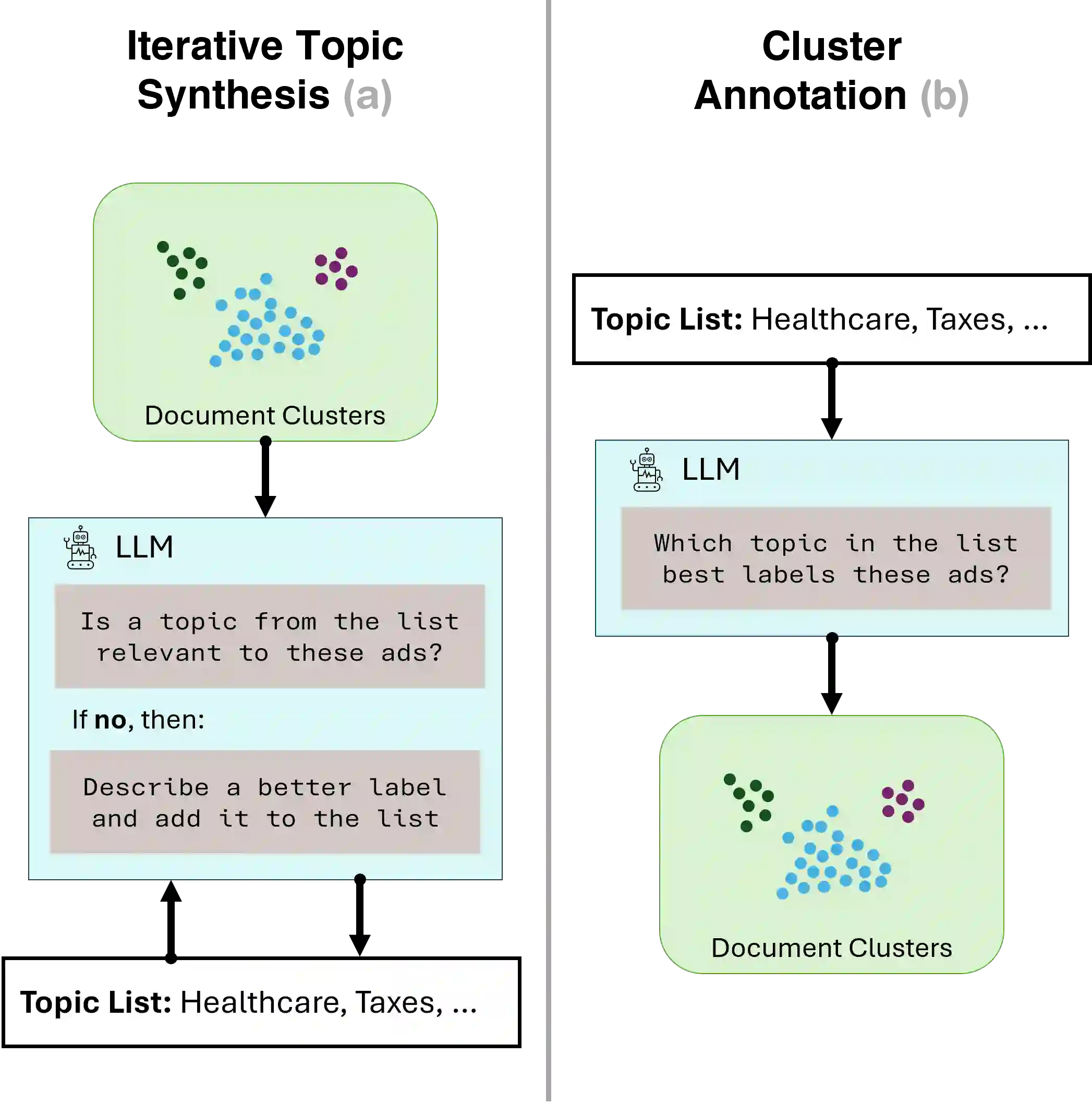
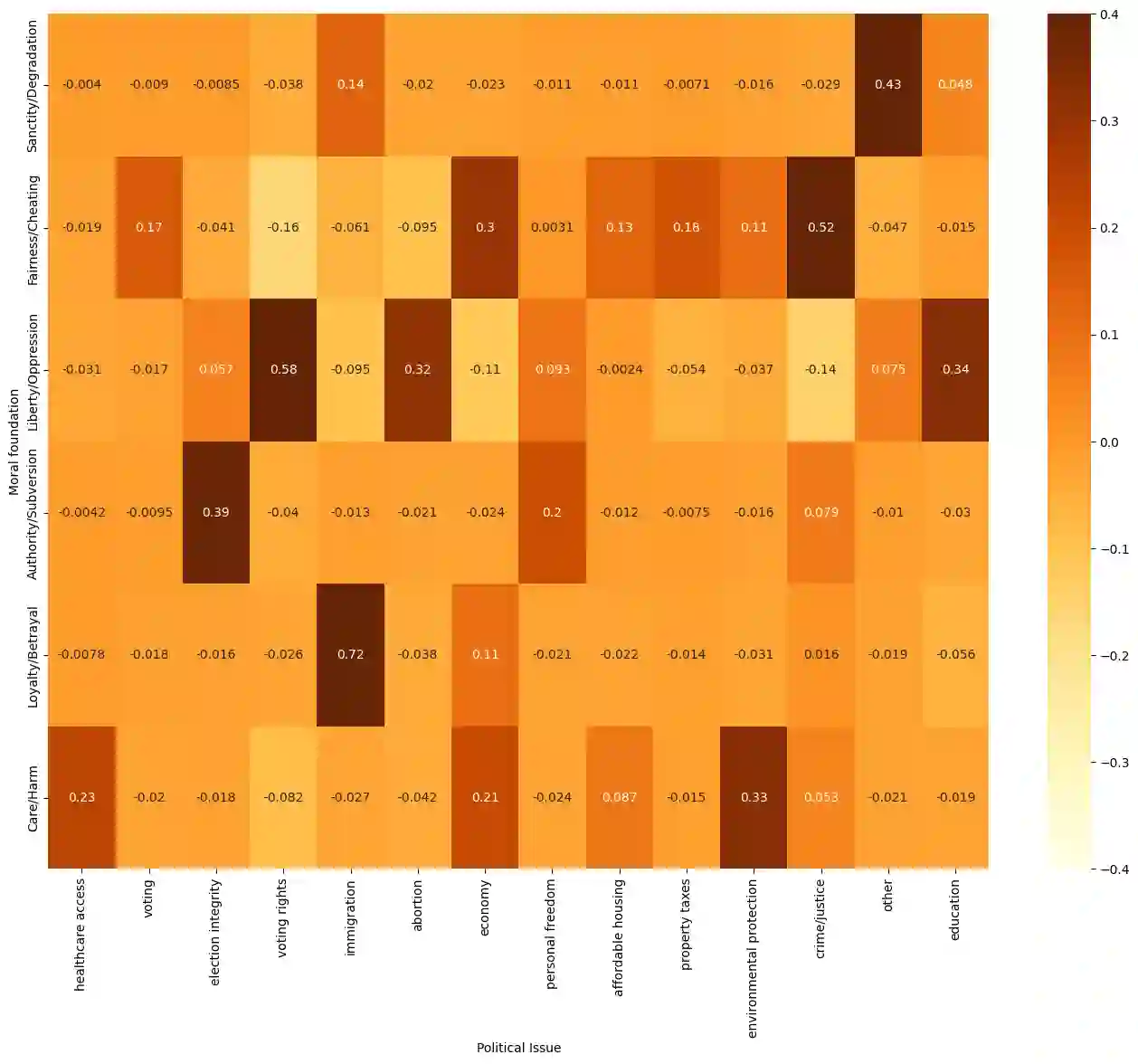
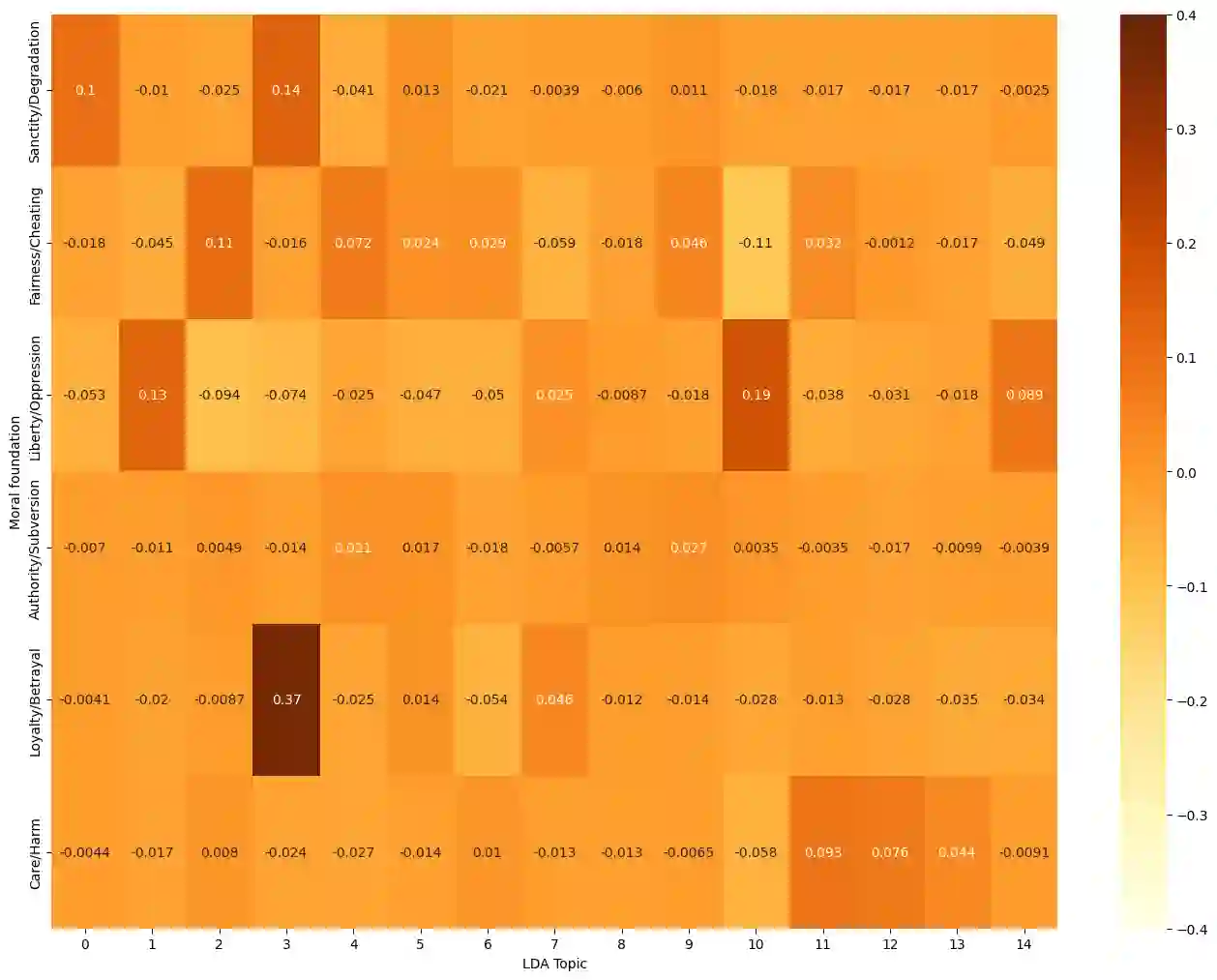
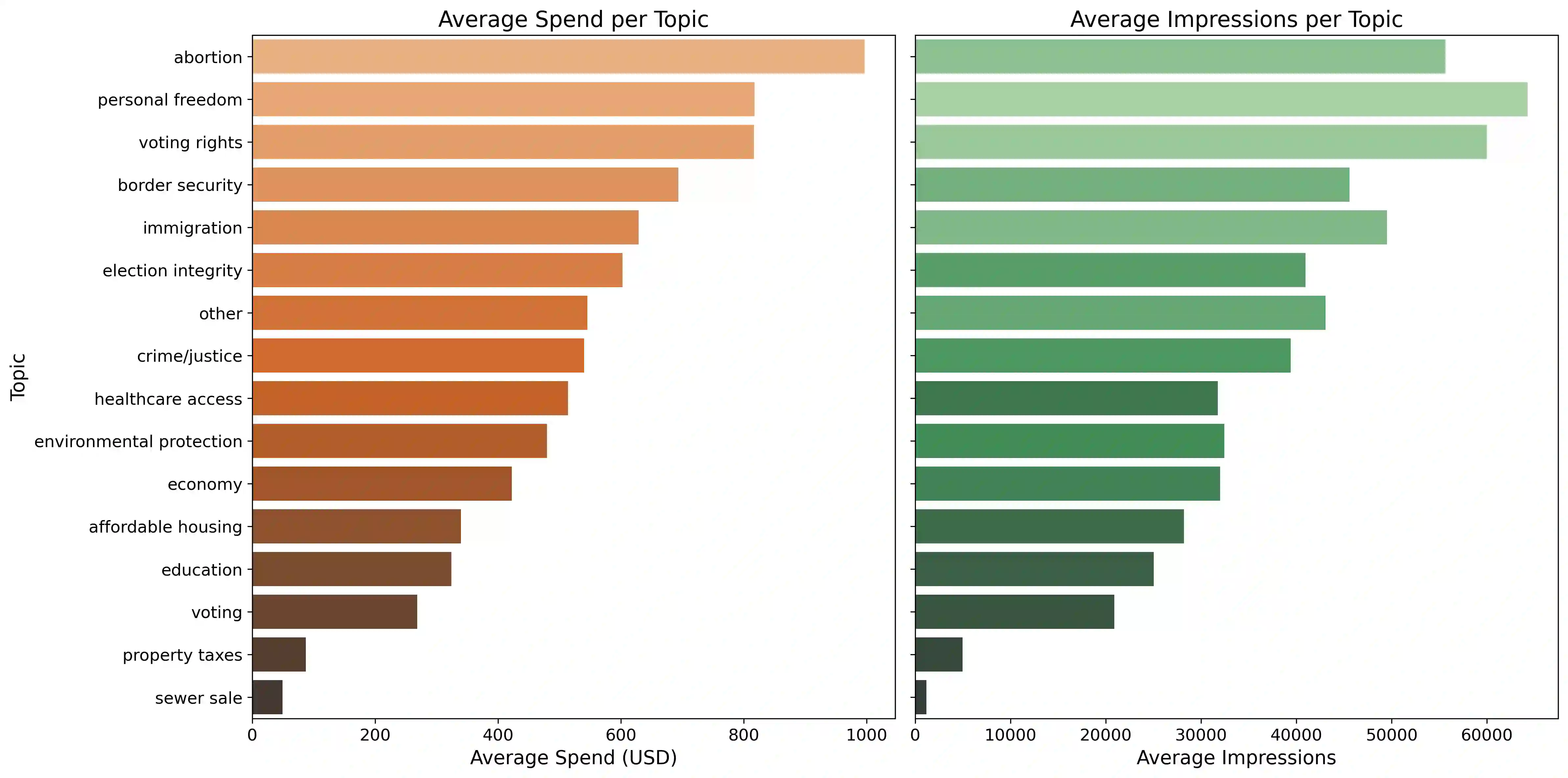
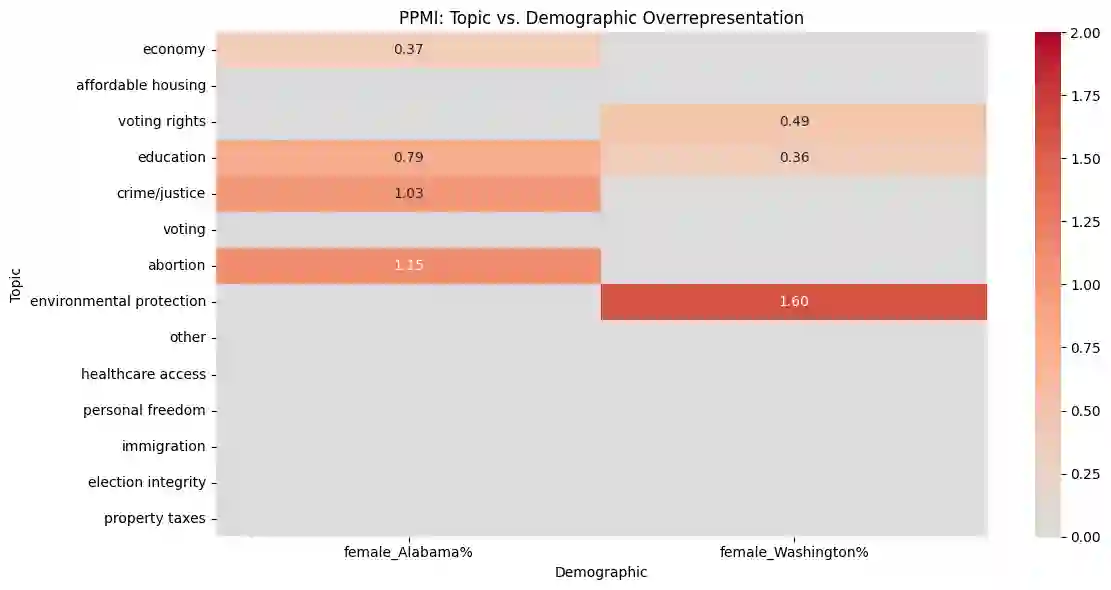
Social media platforms play a pivotal role in shaping political discourse, but analyzing their vast and rapidly evolving content remains a major challenge. We introduce an end-to-end framework for automatically inducing an interpretable topic taxonomy from unlabeled text corpora. By combining unsupervised clustering with prompt-based inference, our method leverages large language models (LLMs) to iteratively construct a taxonomy without requiring seed sets (predefined labels) or domain expertise. We validate the framework through a study of political advertising ahead of the 2024 U.S. presidential election. The induced taxonomy yields semantically rich topic labels and supports downstream analyses, including moral framing, in this setting. Results suggest that structured, iterative labeling yields more consistent and interpretable topic labels than existing approaches under human evaluation, and is practical for analyzing large-scale political advertising data.
翻译:社交媒体平台在塑造政治话语方面发挥着关键作用,但分析其海量且快速演变的内容仍是一项重大挑战。我们提出一种端到端框架,用于从未标注的文本语料库中自动归纳可解释的主题分类体系。通过将无监督聚类与基于提示的推理相结合,我们的方法利用大型语言模型(LLMs)迭代构建分类体系,无需种子集(预定义标签)或领域专业知识。我们通过对2024年美国总统选举前的政治广告研究验证了该框架。在此场景中,归纳出的分类体系产生了语义丰富的主题标签,并支持包括道德框架分析在内的下游任务。结果表明,在人工评估下,结构化、迭代式的标注方法比现有方法能产生更一致且可解释的主题标签,并且适用于大规模政治广告数据的分析。