
本教程全面介绍了大型语言模型(LLMs)的基本概念、构建过程和应用实例,涵盖了以下几个方面:
- LLMs的基本概念:
- 定义及区别:介绍了LLMs、语言模型(LM)和预训练语言模型(PLM)之间的区别,强调了LLMs的多用途和涌现能力。
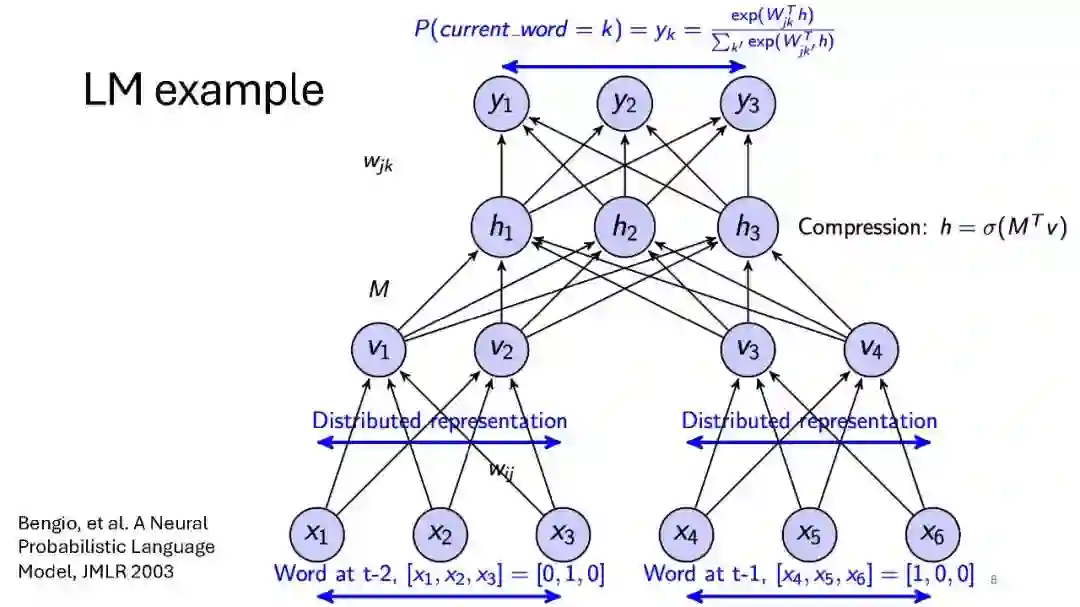
- 语言模型的目标:包括困惑度(perplexity)等指标的定义和计算方法。
- LLMs的构建过程:
- 数据准备:强调了数据源的选择、数据清洗和分词的重要性。
- 预训练:讨论了大规模数据预训练的过程和成本。
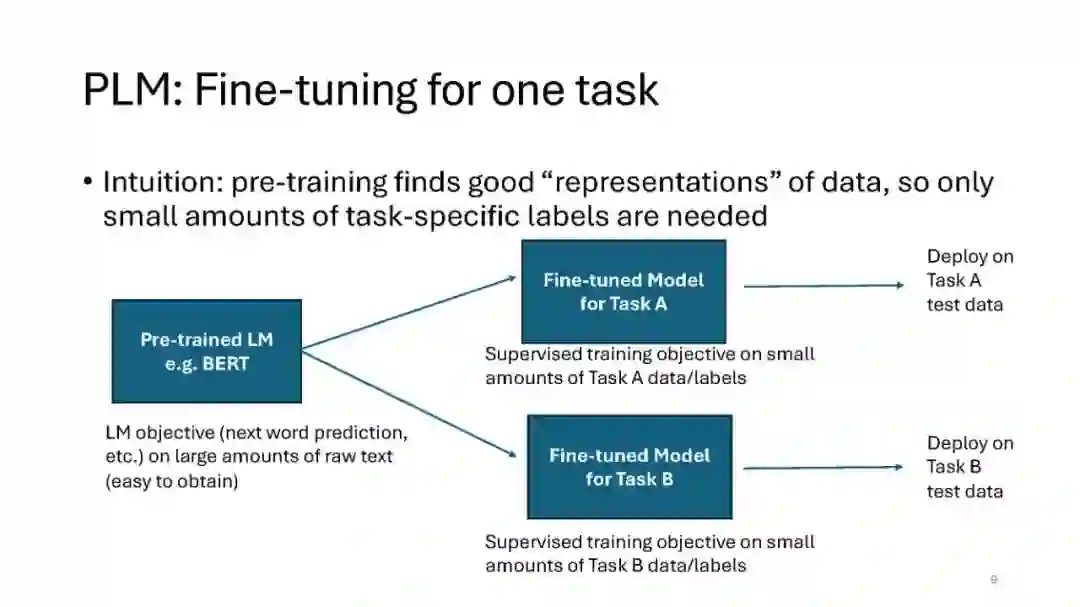
- 微调与对齐:介绍了指令微调、强化学习人类反馈(RLHF)等技术,讨论了模型对齐与人类价值的关系。
- 流行的LLM实现概述:
- 对多个著名的LLM模型(如GPT-4、Llama等)进行比较,分析它们的架构、参数规模和训练成本。
- 介绍了开源模型和封闭模型在研究和部署中的选择和考虑因素。
- 高级话题的快速采样:
- 高效推理与服务:探讨了内存管理和推理效率的改进方法。
- 外部知识的使用:包括检索增强生成(RAG)和工具使用等技术。
- 多LLM代理:讨论了多个LLM协作解决复杂任务的未来方向。
- 负责任的AI:涵盖了可靠性、公平性、问责性、隐私和安全等广泛话题。 本教程通过详细的理论讲解和实践案例,帮助参与者理解LLMs的基本原理和前沿进展,并为未来的研究和应用提供了明确的指导和资源支持。











成为VIP会员查看完整内容
相关内容
Arxiv
12+阅读 · 2021年5月7日

最新内容
相关VIP内容
相关资讯
相关论文
Arxiv
12+阅读 · 2021年5月7日