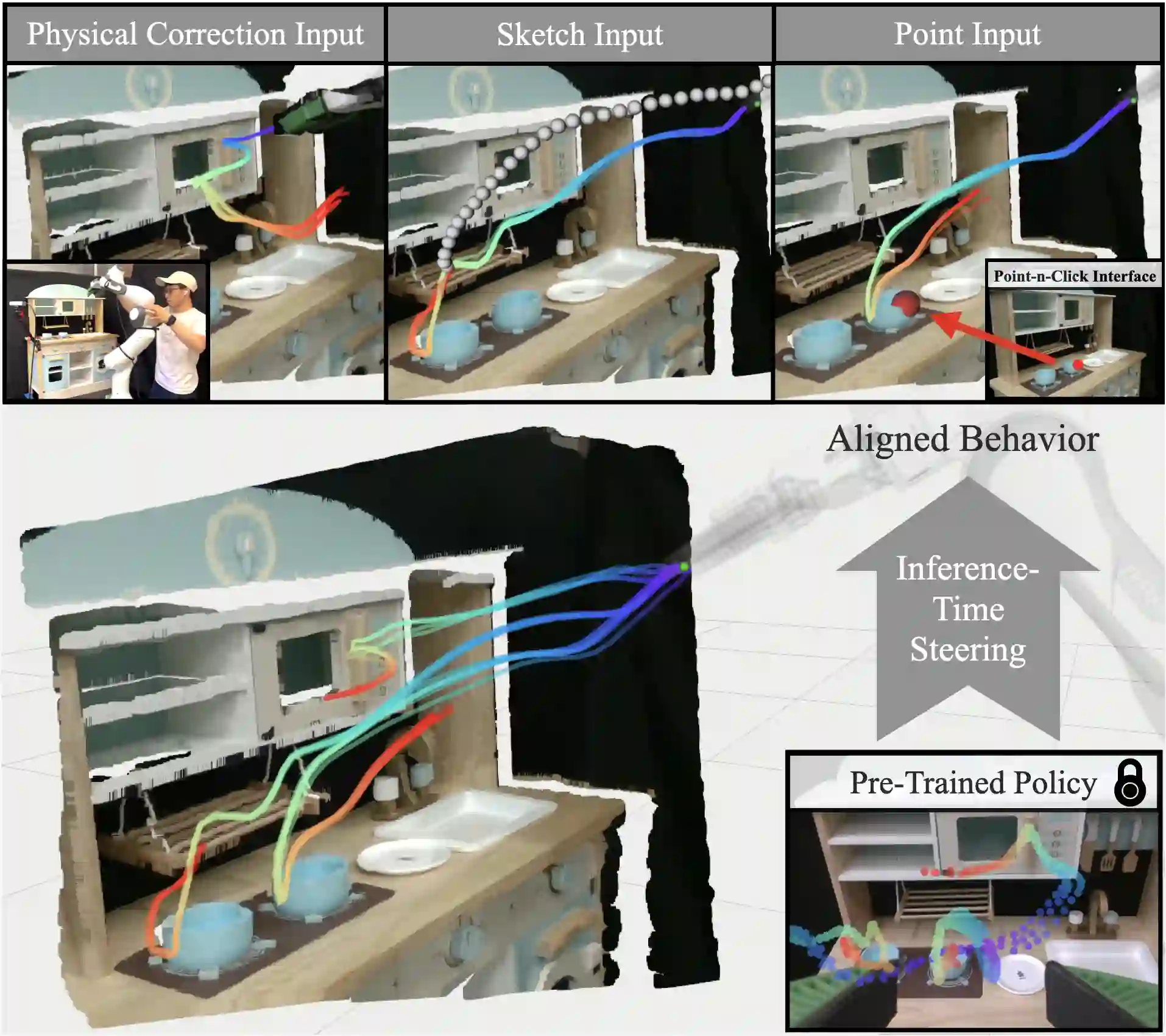
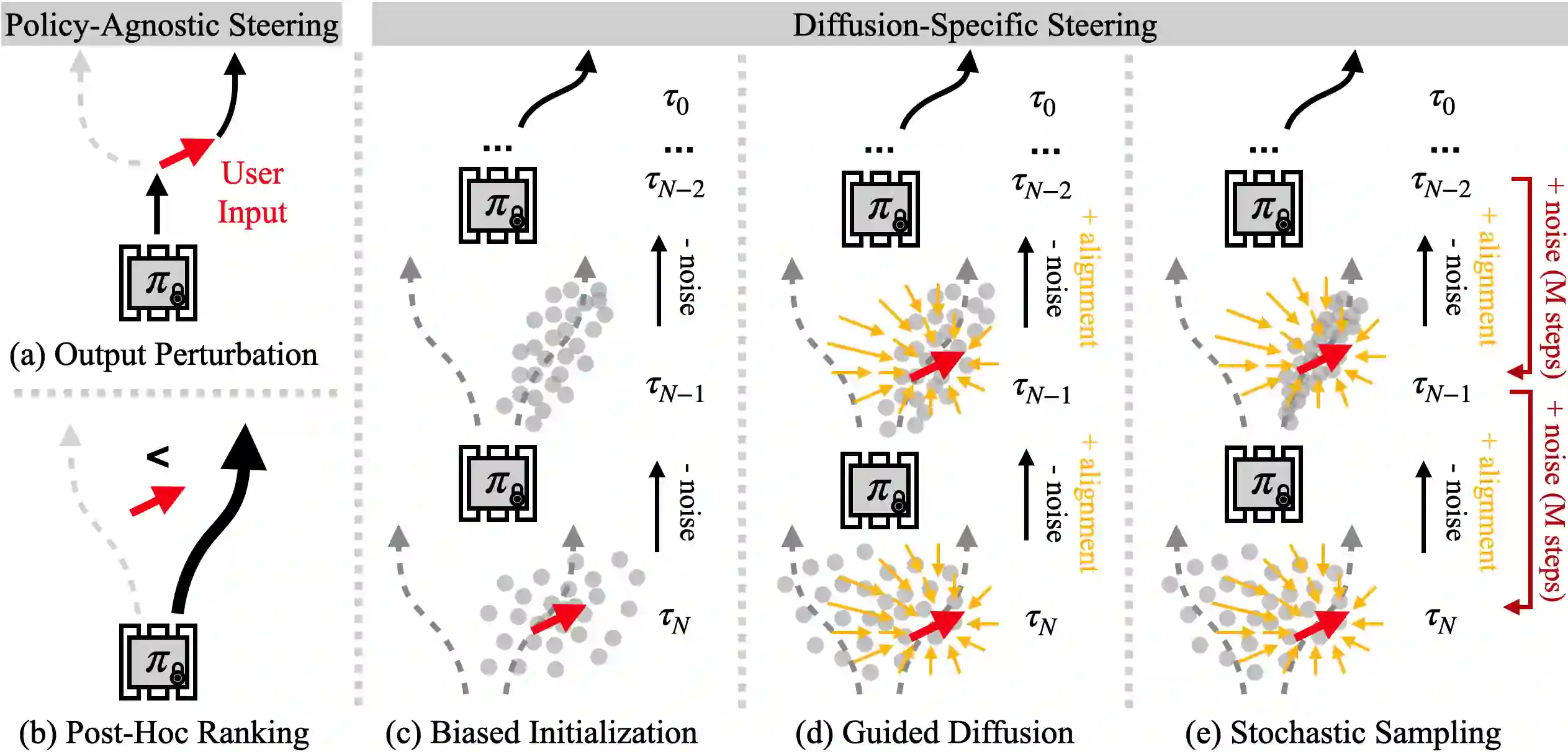
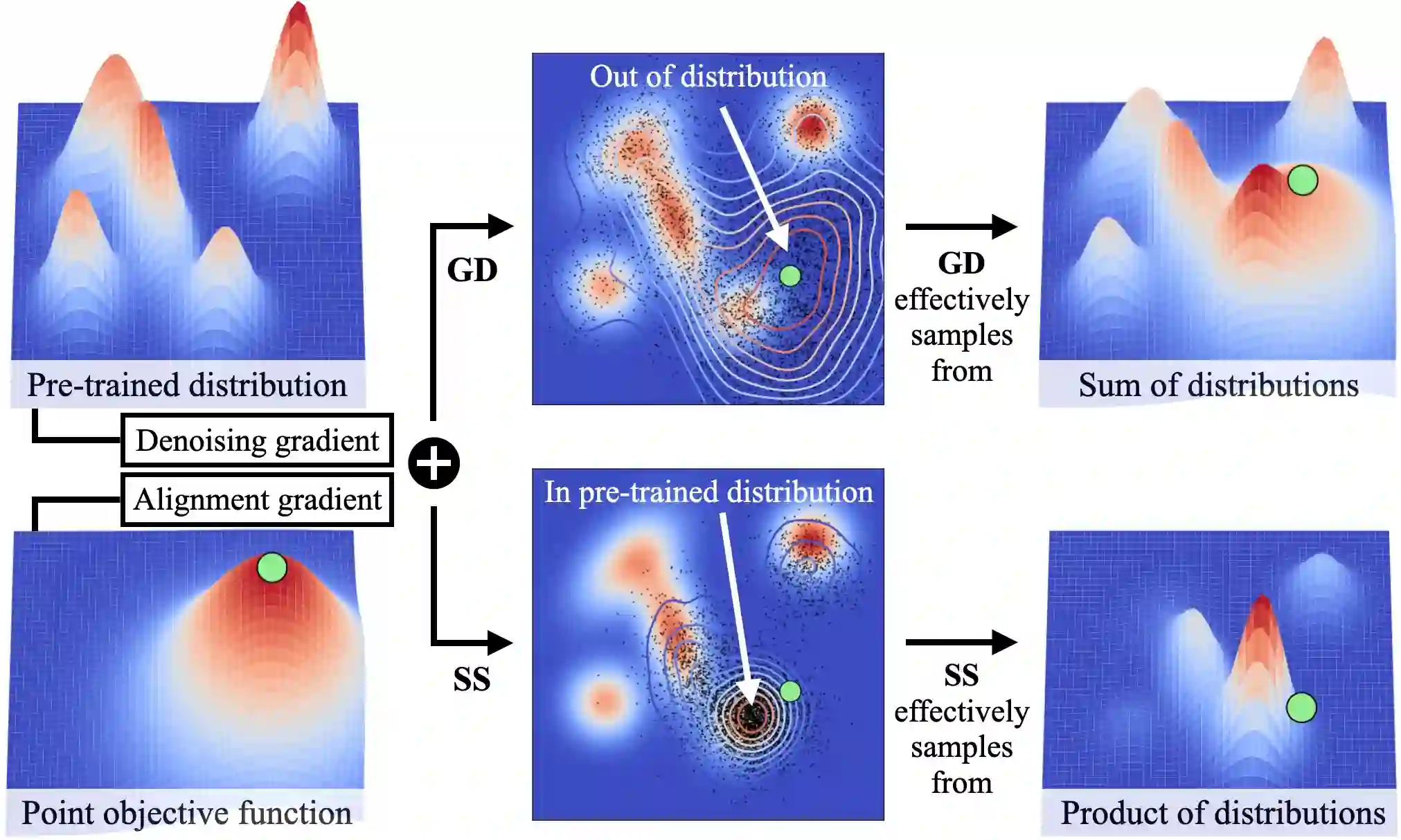
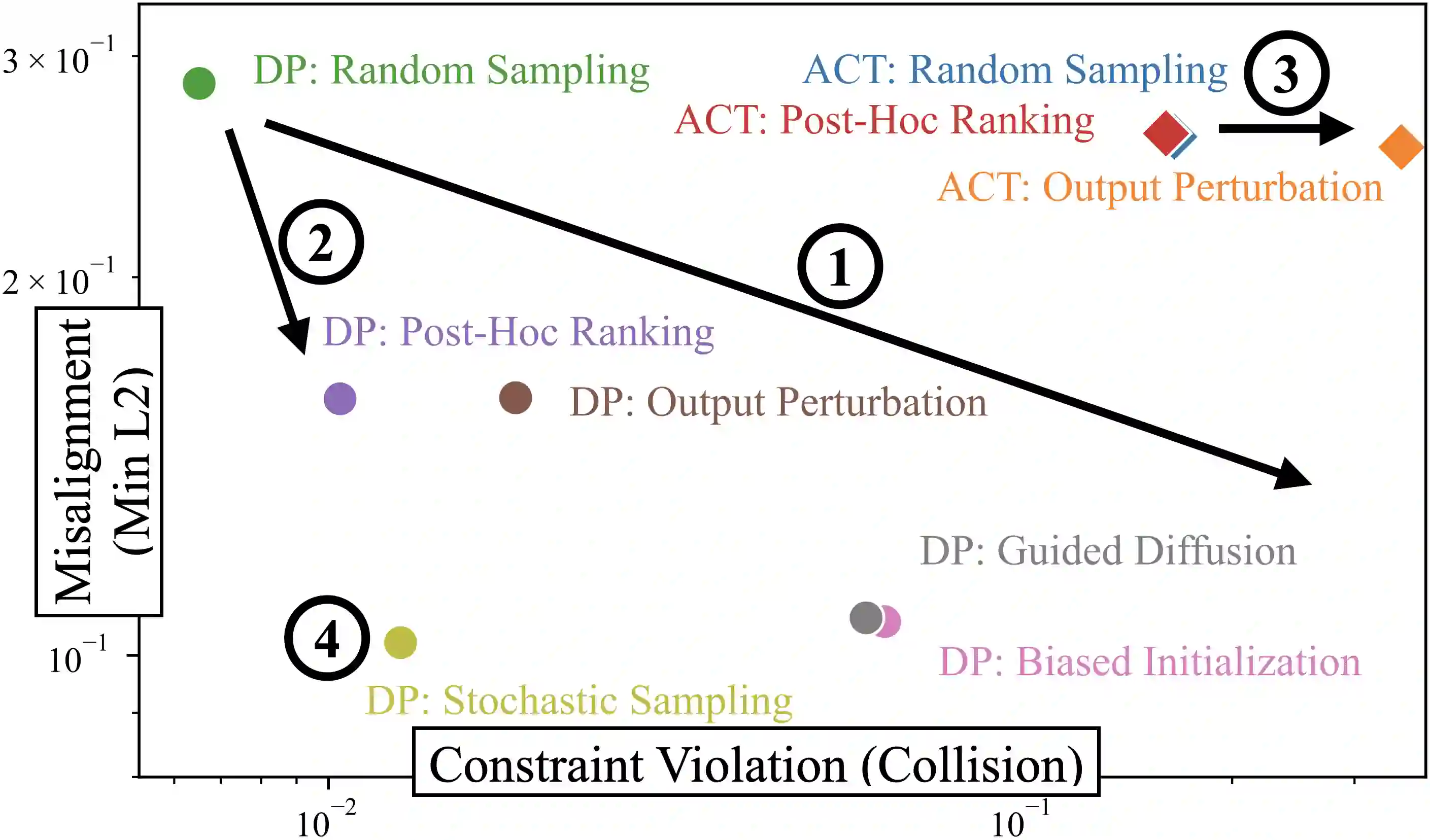
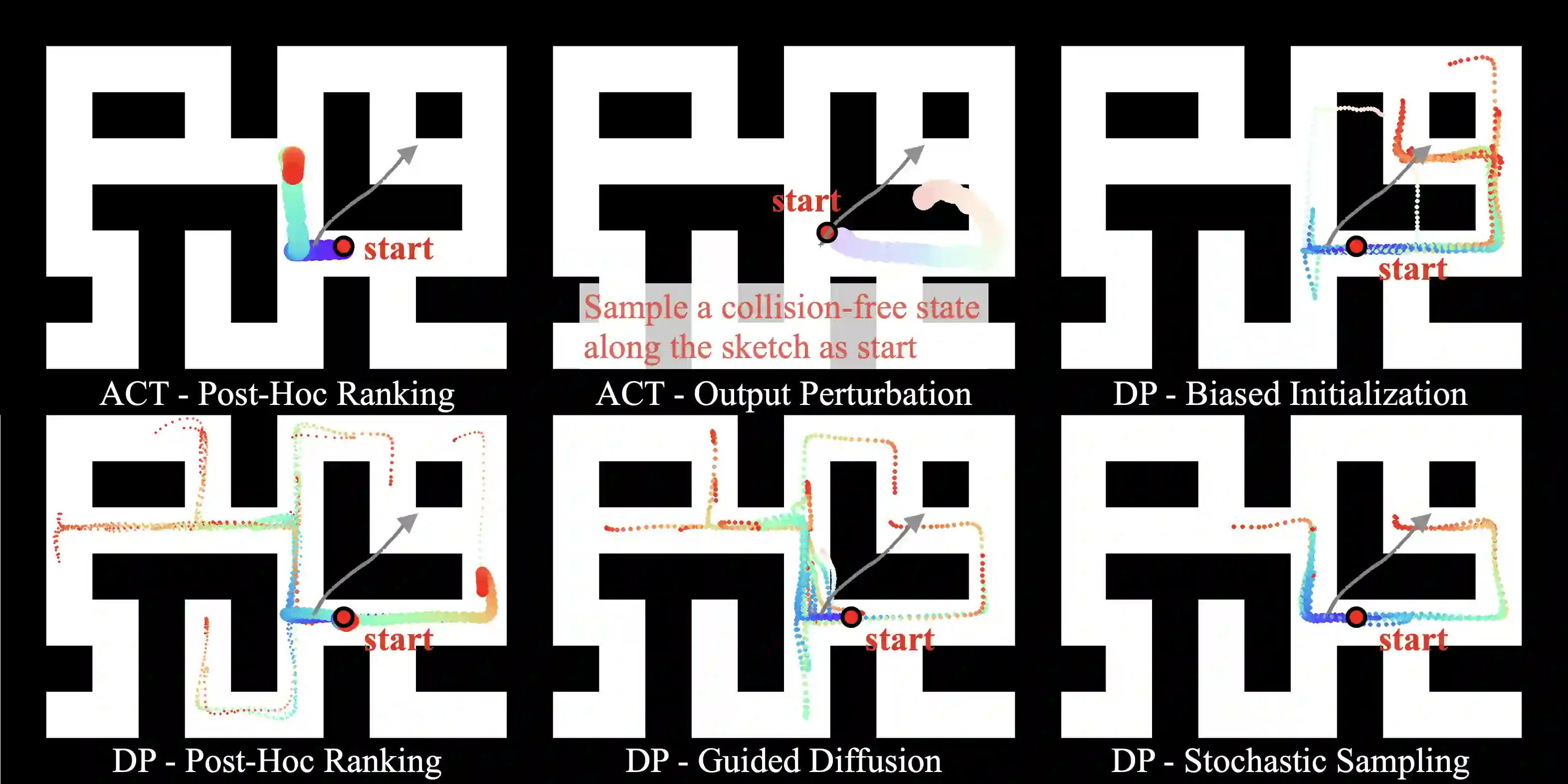
Generative policies trained with human demonstrations can autonomously accomplish multimodal, long-horizon tasks. However, during inference, humans are often removed from the policy execution loop, limiting the ability to guide a pre-trained policy towards a specific sub-goal or trajectory shape among multiple predictions. Naive human intervention may inadvertently exacerbate distribution shift, leading to constraint violations or execution failures. To better align policy output with human intent without inducing out-of-distribution errors, we propose an Inference-Time Policy Steering (ITPS) framework that leverages human interactions to bias the generative sampling process, rather than fine-tuning the policy on interaction data. We evaluate ITPS across three simulated and real-world benchmarks, testing three forms of human interaction and associated alignment distance metrics. Among six sampling strategies, our proposed stochastic sampling with diffusion policy achieves the best trade-off between alignment and distribution shift. Videos are available at https://yanweiw.github.io/itps/.
翻译:基于人类演示训练的生成式策略能够自主完成多模态、长周期任务。然而在推理过程中,人类往往被排除在策略执行循环之外,这限制了将预训练策略引导至特定子目标或在多预测结果中选择特定轨迹形态的能力。简单的人工干预可能无意中加剧分布偏移,导致约束违反或执行失败。为了在不引发分布外误差的前提下更好地使策略输出与人类意图对齐,我们提出了推理时策略引导框架,该框架利用人机交互来偏置生成式采样过程,而非基于交互数据对策略进行微调。我们在三个仿真与真实世界基准测试中评估了ITPS框架,测试了三种形式的人机交互及相应的对齐距离度量。在六种采样策略中,我们提出的基于扩散策略的随机采样方法在对齐度与分布偏移之间取得了最佳平衡。演示视频详见 https://yanweiw.github.io/itps/。