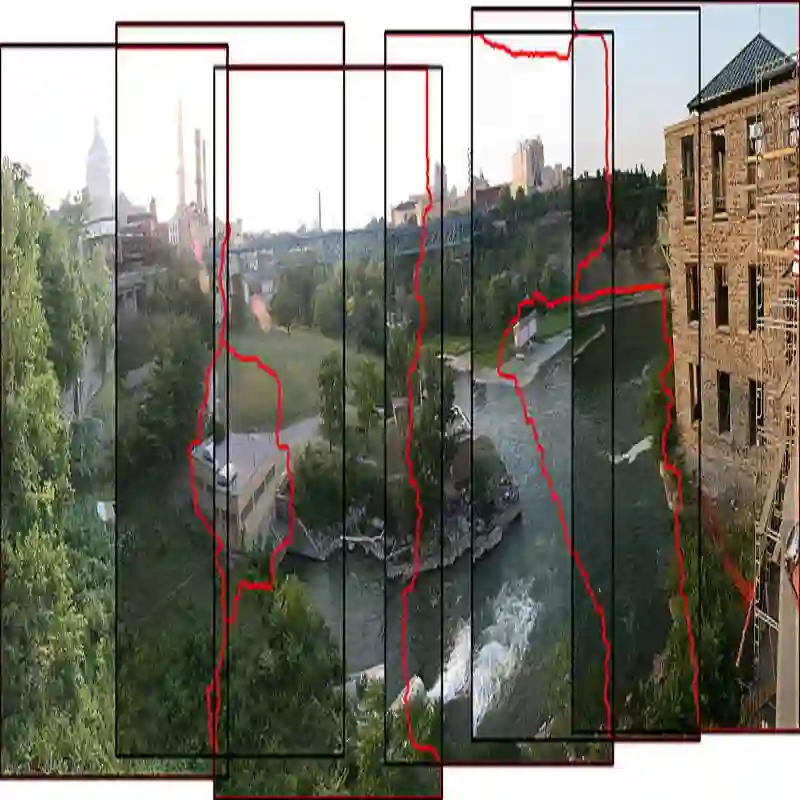
Traditional image stitching approaches tend to leverage increasingly complex geometric features (point, line, edge, etc.) for better performance. However, these hand-crafted features are only suitable for specific natural scenes with adequate geometric structures. In contrast, deep stitching schemes overcome the adverse conditions by adaptively learning robust semantic features, but they cannot handle large-parallax cases due to homography-based registration. To solve these issues, we propose UDIS++, a parallax-tolerant unsupervised deep image stitching technique. First, we propose a robust and flexible warp to model the image registration from global homography to local thin-plate spline motion. It provides accurate alignment for overlapping regions and shape preservation for non-overlapping regions by joint optimization concerning alignment and distortion. Subsequently, to improve the generalization capability, we design a simple but effective iterative strategy to enhance the warp adaption in cross-dataset and cross-resolution applications. Finally, to further eliminate the parallax artifacts, we propose to composite the stitched image seamlessly by unsupervised learning for seam-driven composition masks. Compared with existing methods, our solution is parallax-tolerant and free from laborious designs of complicated geometric features for specific scenes. Extensive experiments show our superiority over the SoTA methods, both quantitatively and qualitatively. The code will be available at https://github.com/nie-lang/UDIS2.
翻译:传统图像拼接方法倾向于利用日益复杂的几何特征(如点、线、边缘等)来提升性能。然而,这些手工设计的特征仅适用于具有充足几何结构的特定自然场景。相比之下,深度拼接方案通过自适应学习鲁棒的语义特征来克服不利条件,但由于基于单应性变换的配准,无法处理大视差情况。为解决这些问题,我们提出UDIS++——一种容忍视差的非监督深度图像拼接技术。首先,我们提出一种鲁棒且灵活的形变模型,将图像配准从全局单应性变换到局部薄板样条运动。该模型通过联合优化对齐与形变,为重叠区域提供精确对齐,同时为非重叠区域保持形状。随后,为提升泛化能力,我们设计了一种简单但有效的迭代策略,增强形变在跨数据集和跨分辨率应用中的适应性。最后,为进一步消除视差伪影,我们通过非监督学习提出一种基于接缝驱动的合成掩膜的无缝拼接方法。与现有方法相比,我们的解决方案能容忍视差,且无需为特定场景设计繁琐的复杂几何特征。大量实验在定量和定性上均证实了本方法优于当前最优技术。代码将开源在https://github.com/nie-lang/UDIS2。