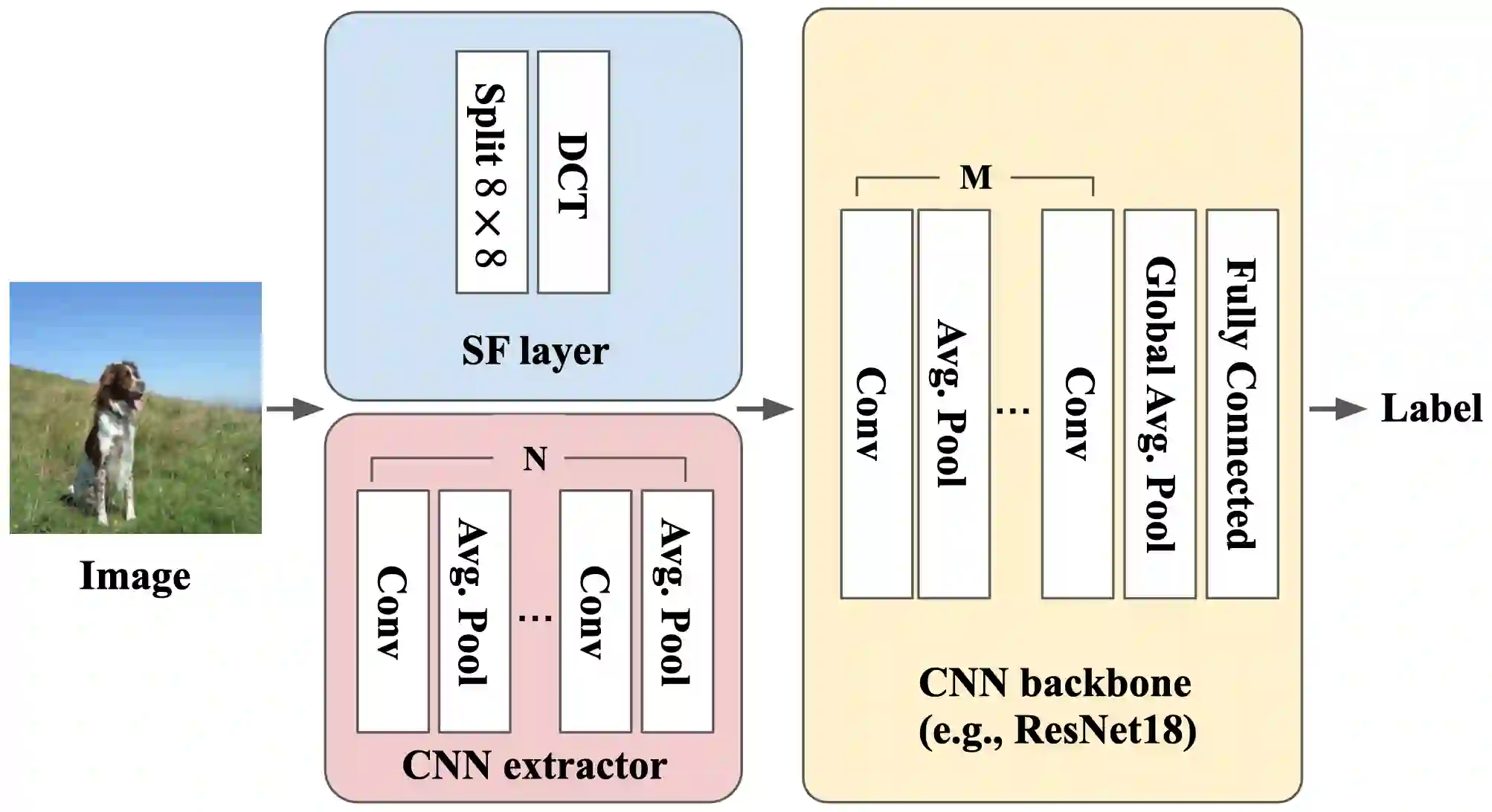
Convolutional Neural Networks (CNNs) have dominated the majority of computer vision tasks. However, CNNs' vulnerability to adversarial attacks has raised concerns about deploying these models to safety-critical applications. In contrast, the Human Visual System (HVS), which utilizes spatial frequency channels to process visual signals, is immune to adversarial attacks. As such, this paper presents an empirical study exploring the vulnerability of CNN models in the frequency domain. Specifically, we utilize the discrete cosine transform (DCT) to construct the Spatial-Frequency (SF) layer to produce a block-wise frequency spectrum of an input image and formulate Spatial Frequency CNNs (SF-CNNs) by replacing the initial feature extraction layers of widely-used CNN backbones with the SF layer. Through extensive experiments, we observe that SF-CNN models are more robust than their CNN counterparts under both white-box and black-box attacks. To further explain the robustness of SF-CNNs, we compare the SF layer with a trainable convolutional layer with identical kernel sizes using two mixing strategies to show that the lower frequency components contribute the most to the adversarial robustness of SF-CNNs. We believe our observations can guide the future design of robust CNN models.
翻译:卷积神经网络(CNN)已主导了大部分计算机视觉任务。然而,CNN对对抗攻击的脆弱性引发了对其部署于安全关键型应用的担忧。相较而言,利用空间频率通道处理视觉信号的人类视觉系统(HVS)则对对抗攻击具有免疫性。为此,本文通过实证研究探索CNN模型在频率域中的脆弱性。具体而言,我们利用离散余弦变换(DCT)构建空间频率(SF)层以生成输入图像的块级频谱,并通过将广泛使用的CNN主干网络初始特征提取层替换为SF层,构建空间频率卷积神经网络(SF-CNN)。通过大量实验,我们观察到SF-CNN模型在白盒与黑盒攻击下均比传统CNN模型具有更强的鲁棒性。为进一步解释SF-CNN的鲁棒性,我们采用两种混合策略,将SF层与具有相同卷积核尺寸的可训练卷积层进行对比,结果表明低频分量对SF-CNN的对抗鲁棒性贡献最大。我们认为该发现可指导未来鲁棒CNN模型的设计。