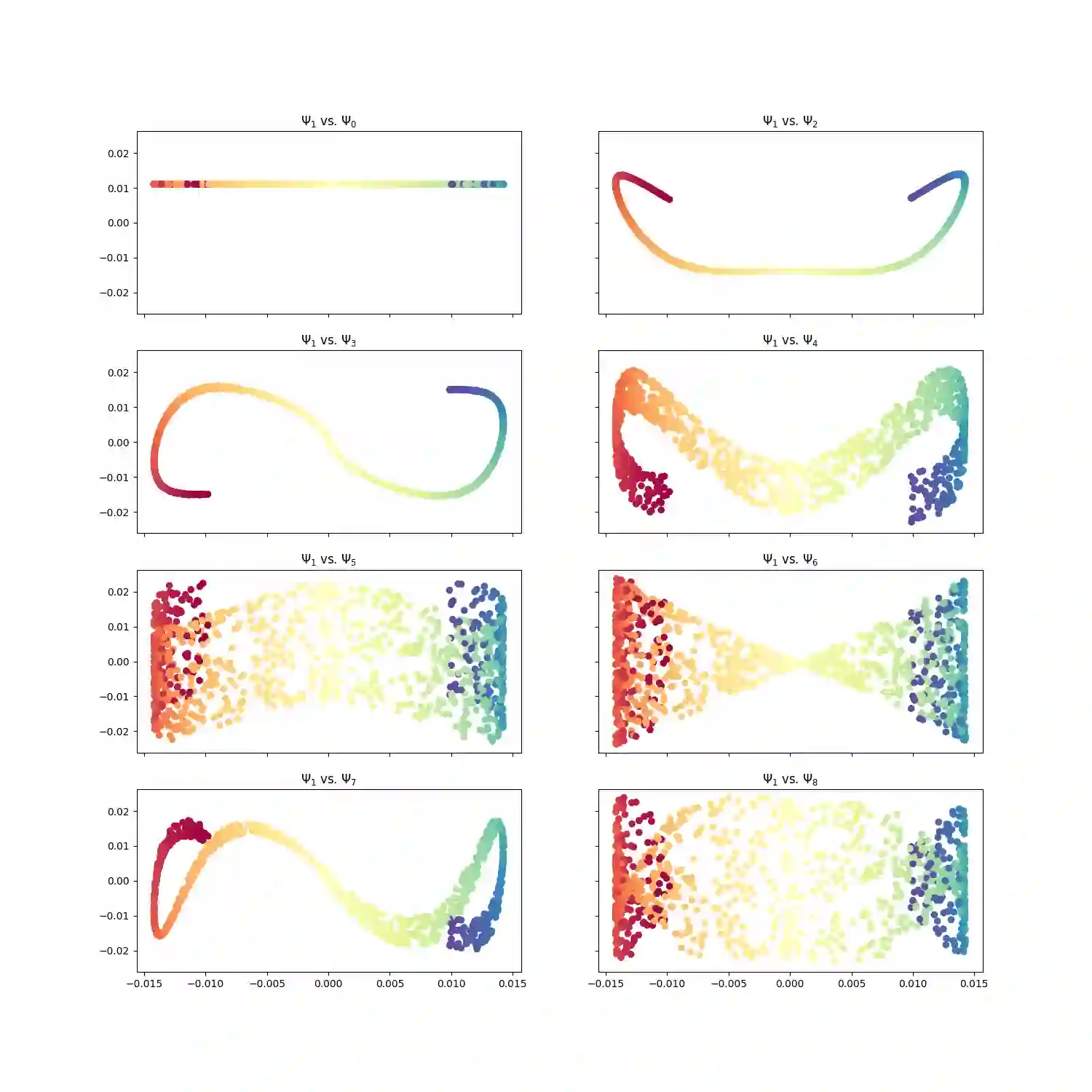
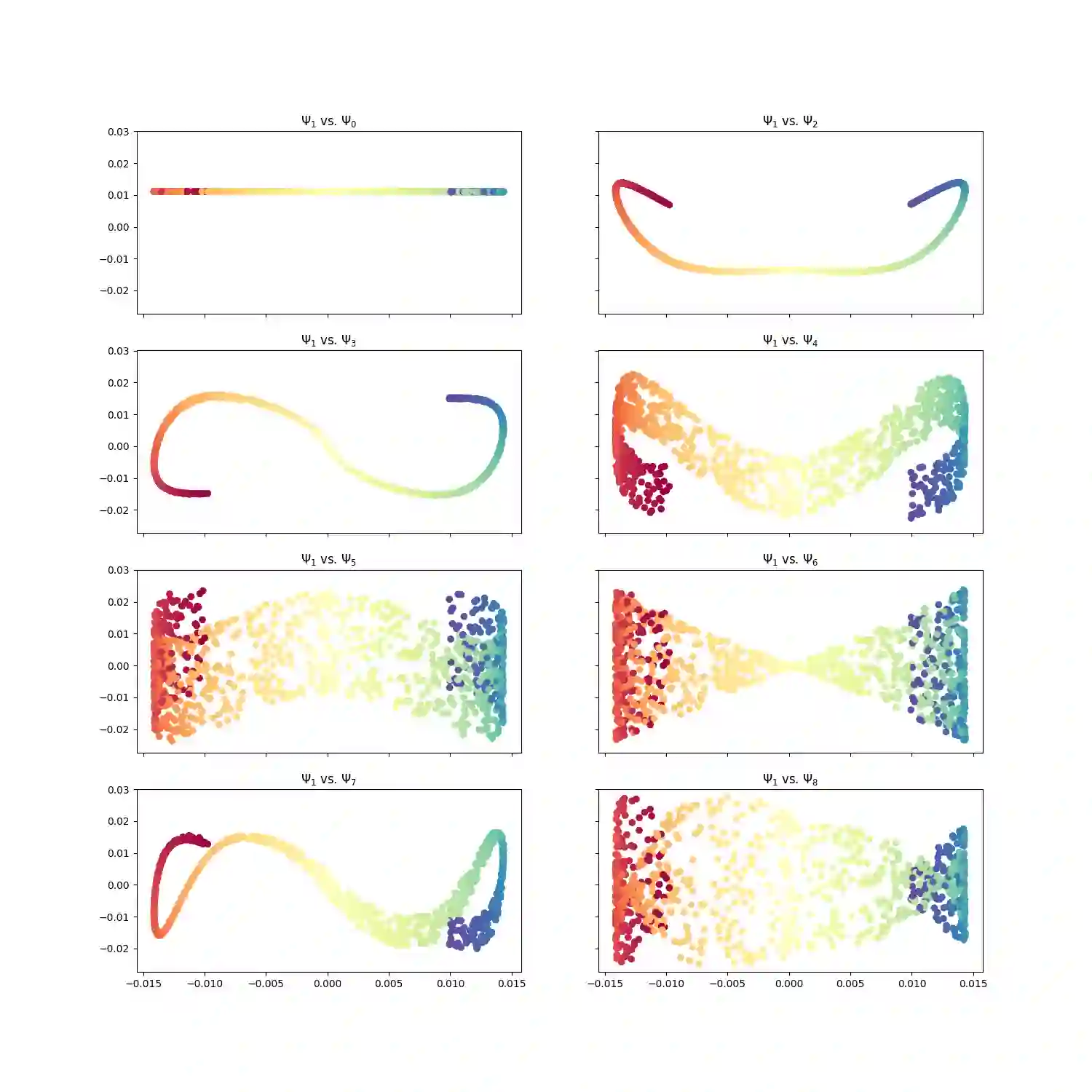
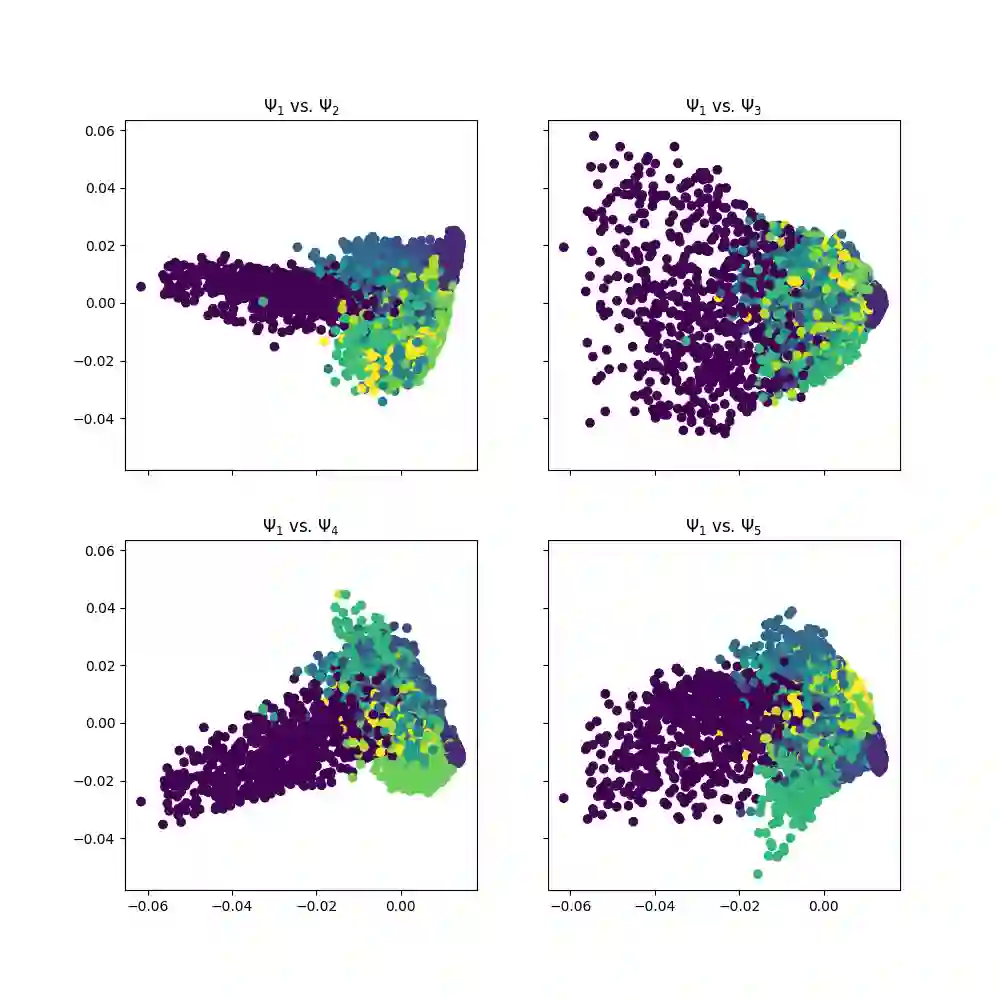
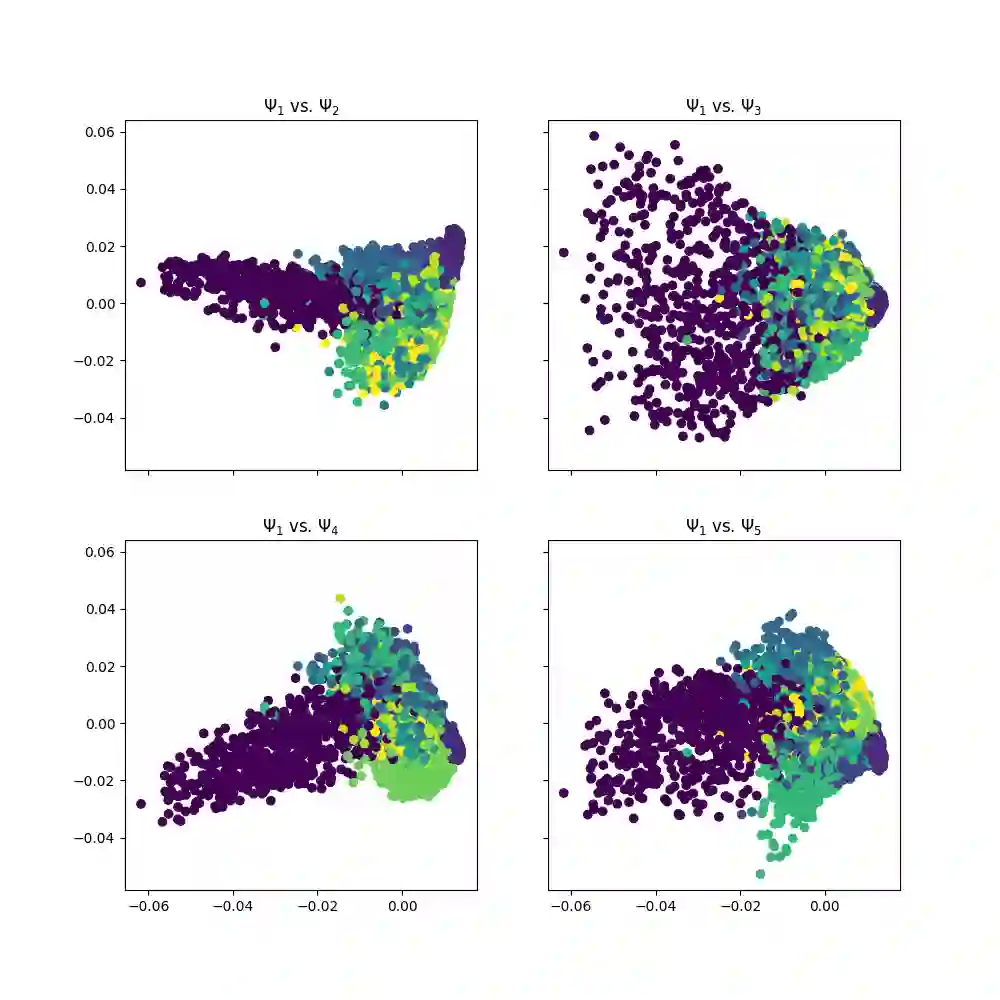
With the emergence of Artificial Intelligence, numerical algorithms are moving towards more approximate approaches. For methods such as PCA or diffusion maps, it is necessary to compute eigenvalues of a large matrix, which may also be dense depending on the kernel. A global method, i.e. a method that requires all data points simultaneously, scales with the data dimension N and not with the intrinsic dimension d; the complexity for an exact dense eigendecomposition leads to $\mathcal{O}(N^{3})$. We have combined the two frameworks, $\mathsf{datafold}$ and $\mathsf{GOFMM}$. The first framework computes diffusion maps, where the computational bottleneck is the eigendecomposition while with the second framework we compute the eigendecomposition approximately within the iterative Lanczos method. A hierarchical approximation approach scales roughly with a runtime complexity of $\mathcal{O}(Nlog(N))$ vs. $\mathcal{O}(N^{3})$ for a classic approach. We evaluate the approach on two benchmark datasets -- scurve and MNIST -- with strong and weak scaling using OpenMP and MPI on dense matrices with maximum size of $100k\times100k$.
翻译:随着人工智能的兴起,数值算法正趋向于采用近似方法。对于主成分分析或扩散映射等方法,需要计算大型矩阵的特征值,这些矩阵可能因核函数的不同而变得稠密。全局方法(即需要同时利用所有数据点的方法)的复杂度与数据维度N相关,而非内在维度d;精确稠密特征分解的复杂度为$\mathcal{O}(N^{3})$。我们结合了$\mathsf{datafold}$和$\mathsf{GOFMM}$两个框架:前者用于计算扩散映射,其计算瓶颈在于特征分解;而后者在迭代Lanczos方法中近似计算特征分解。层次化近似方法的运行时间复杂度约为$\mathcal{O}(N\log(N))$,而传统方法为$\mathcal{O}(N^{3})$。我们在两个基准数据集——scurve和MNIST——上,利用OpenMP和MPI对最大规模为$100k\times100k$的稠密矩阵进行了强扩展与弱扩展评估。