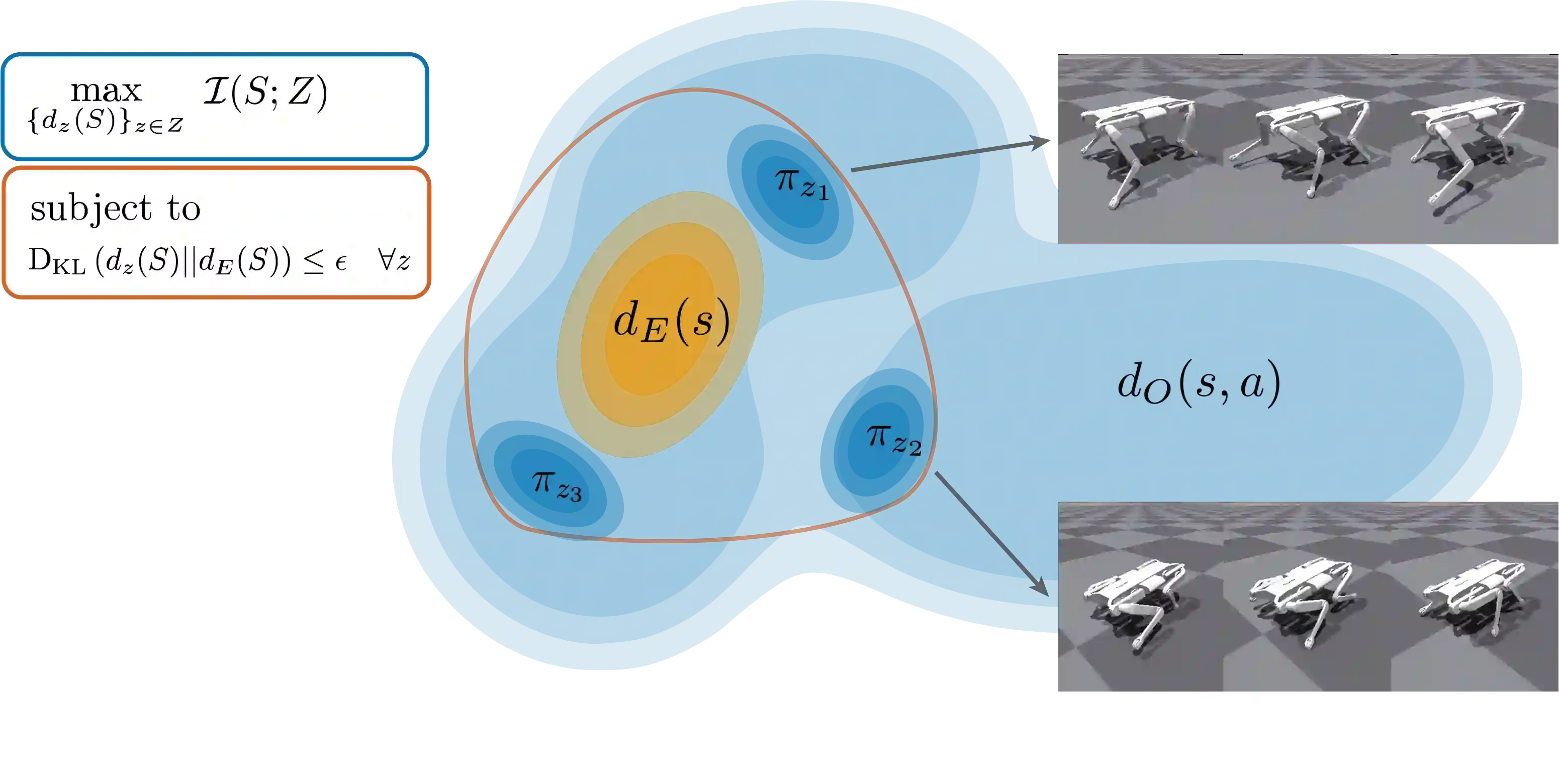
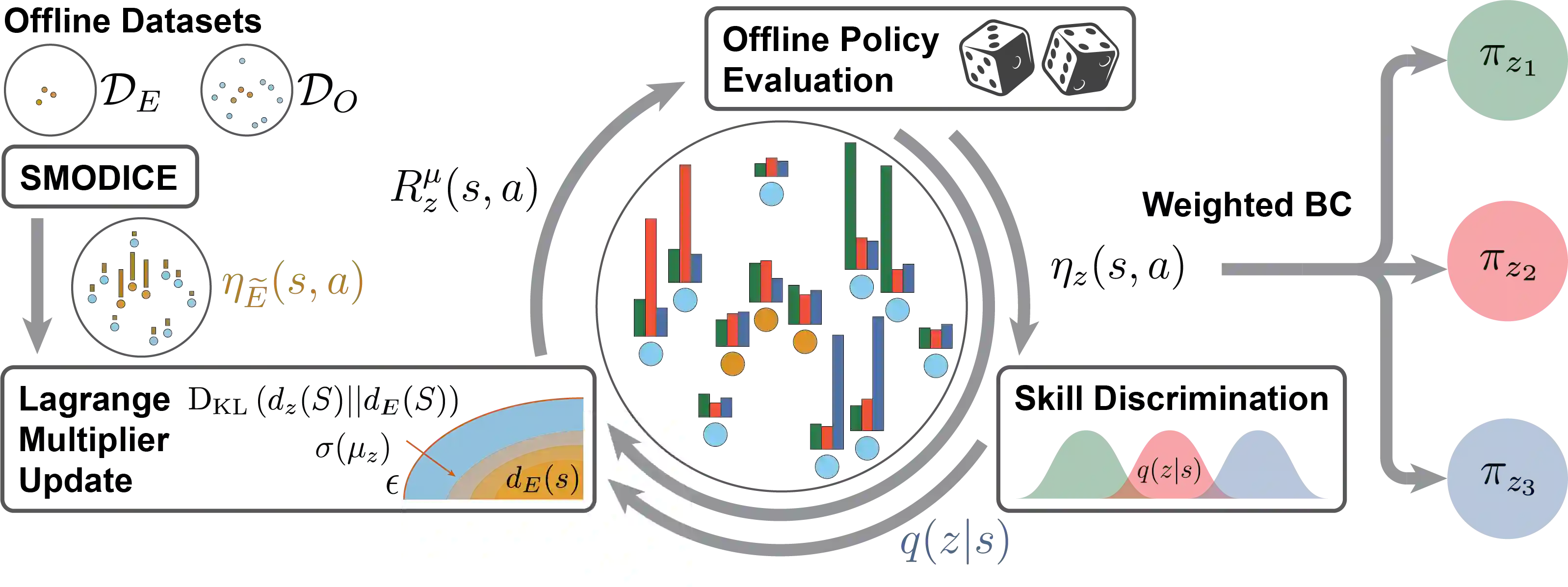
There has been significant recent progress in the area of unsupervised skill discovery, utilizing various information-theoretic objectives as measures of diversity. Despite these advances, challenges remain: current methods require significant online interaction, fail to leverage vast amounts of available task-agnostic data and typically lack a quantitative measure of skill utility. We address these challenges by proposing a principled offline algorithm for unsupervised skill discovery that, in addition to maximizing diversity, ensures that each learned skill imitates state-only expert demonstrations to a certain degree. Our main analytical contribution is to connect Fenchel duality, reinforcement learning, and unsupervised skill discovery to maximize a mutual information objective subject to KL-divergence state occupancy constraints. Furthermore, we demonstrate the effectiveness of our method on the standard offline benchmark D4RL and on a custom offline dataset collected from a 12-DoF quadruped robot for which the policies trained in simulation transfer well to the real robotic system.
翻译:在无监督技能发现领域,近期取得了显著进展,这些进展利用各种信息论目标函数作为多样性的衡量标准。尽管取得这些进步,仍然存在挑战:当前方法需要大量的在线交互,无法利用大量可用的任务无关数据,并且通常缺乏对技能实用性的定量度量。我们通过提出一种原则性的离线无监督技能发现算法来应对这些挑战,该算法除了最大化多样性外,还确保每个学习到的技能在某种程度上模仿仅包含状态信息的专家演示。我们的主要分析贡献在于将芬切尔对偶性、强化学习和无监督技能发现联系起来,以在KL散度状态占用约束下最大化互信息目标。此外,我们在标准离线基准测试D4RL以及从一台12自由度四足机器人收集的自定义离线数据集上展示了我们方法的有效性,在该数据集上训练的策略能够很好地迁移到真实机器人系统。