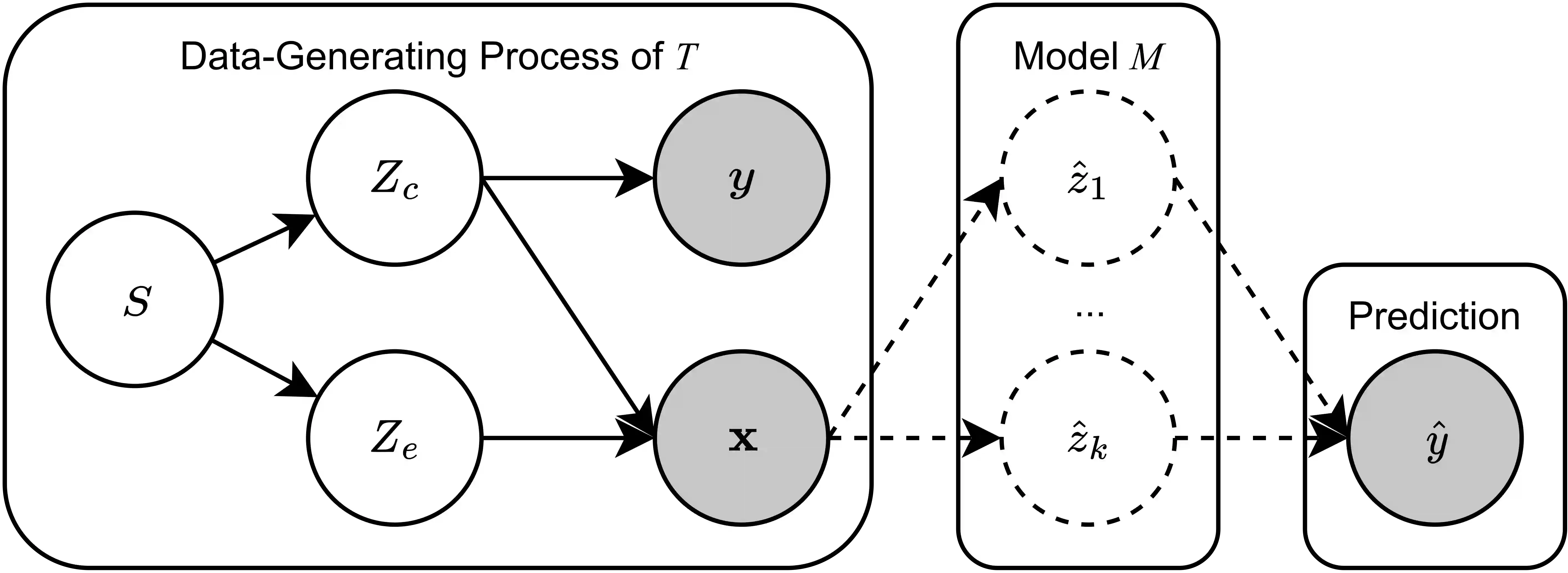
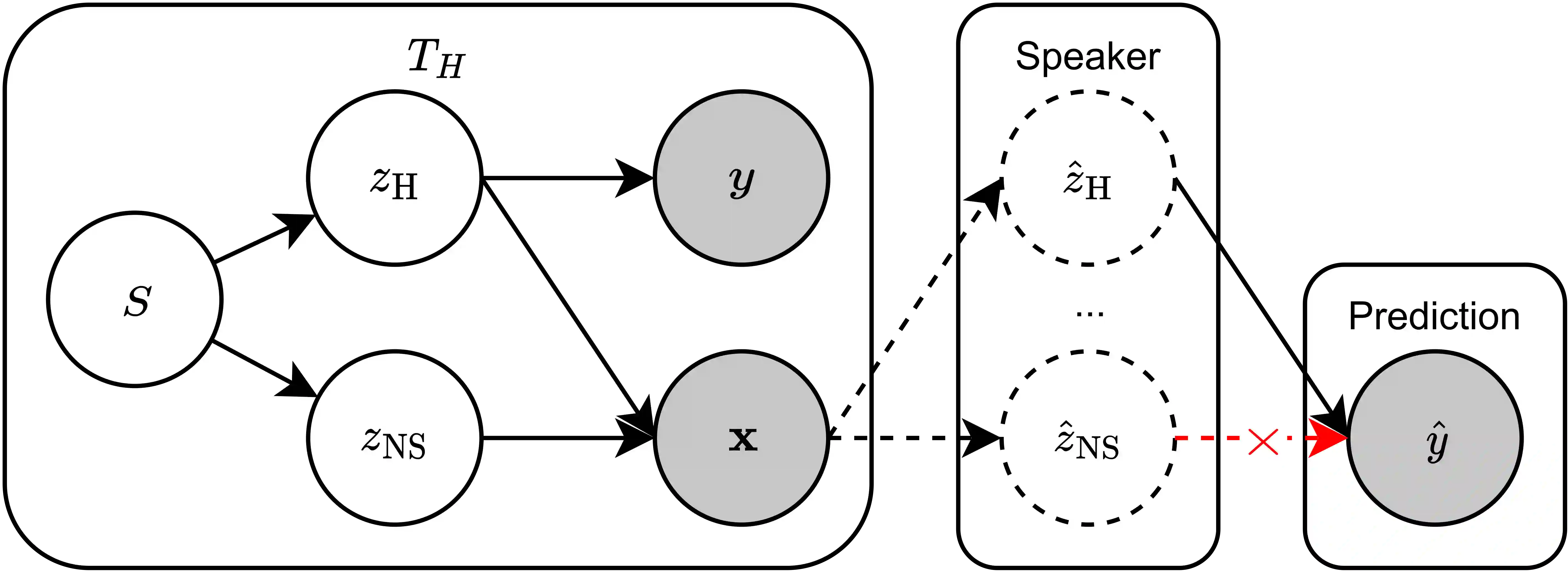
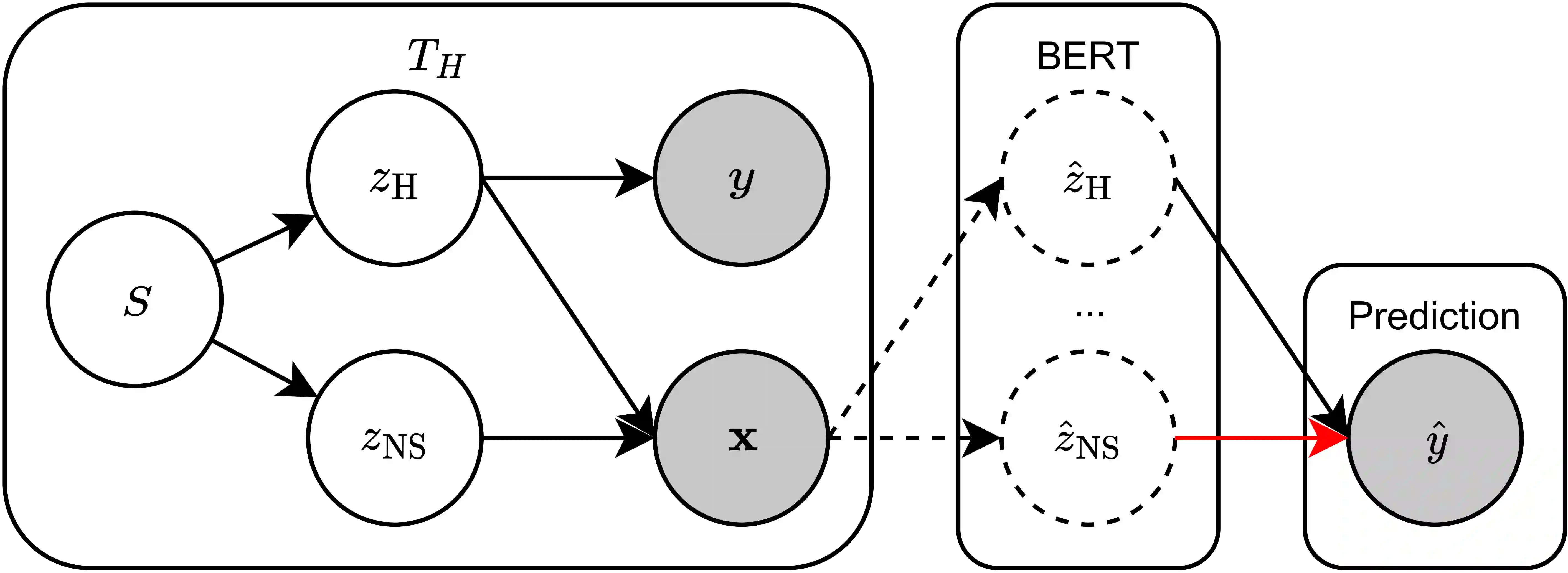
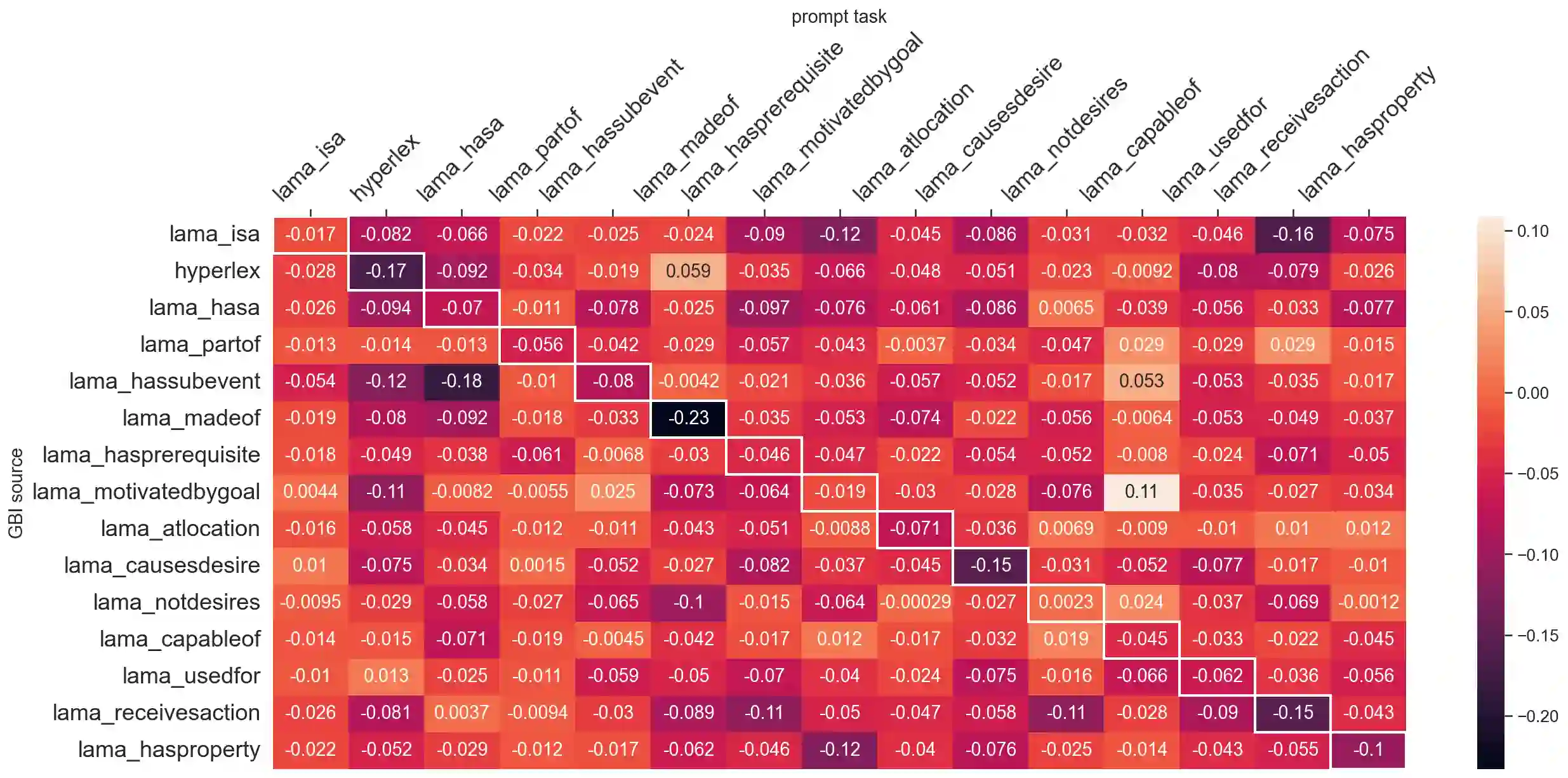
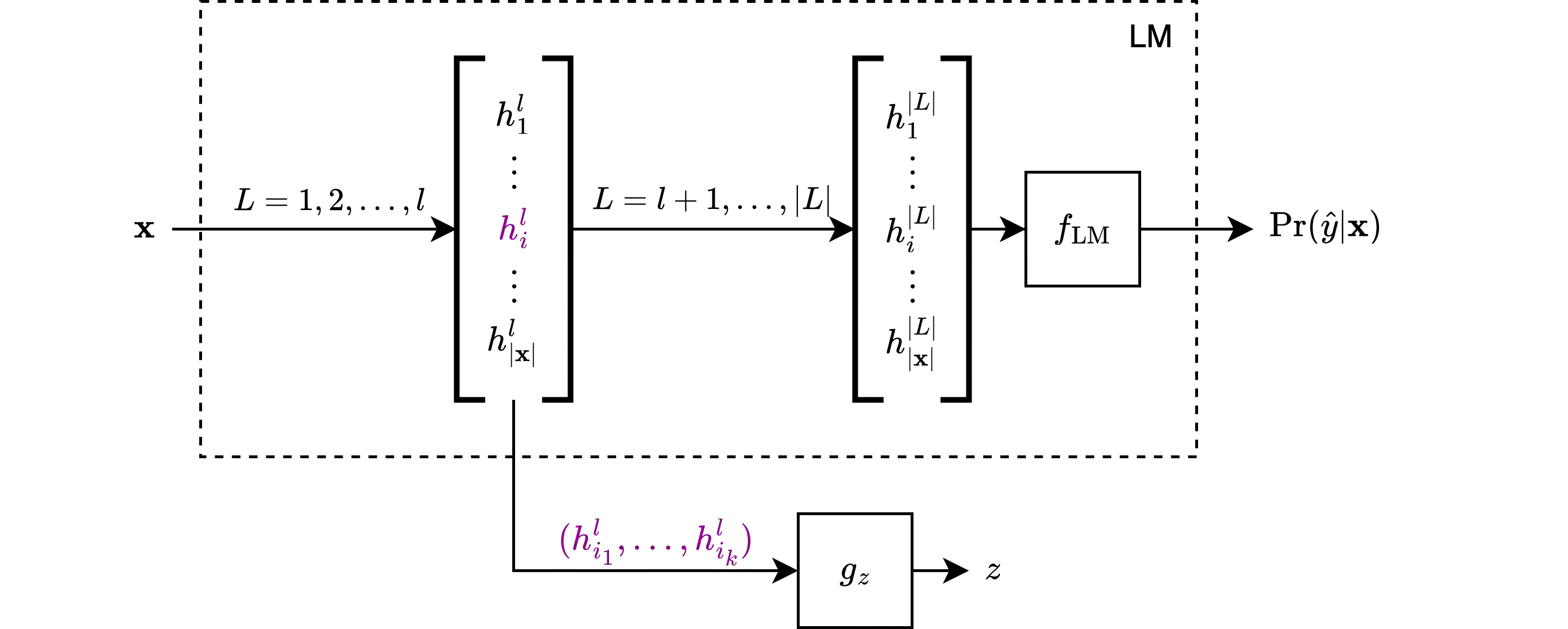Despite the recent success of large pretrained language models (LMs) on a variety of prompting tasks, these models can be alarmingly brittle to small changes in inputs or application contexts. To better understand such behavior and motivate the design of more robust LMs, we propose a general experimental framework, CALM (Competence-based Analysis of Language Models), where targeted causal interventions are utilized to damage an LM's internal representation of various linguistic properties in order to evaluate its use of each representation in performing a given task. We implement these interventions as gradient-based adversarial attacks, which (in contrast to prior causal probing methodologies) are able to target arbitrarily-encoded representations of relational properties, and carry out a case study of this approach to analyze how BERT-like LMs use representations of several relational properties in performing associated relation prompting tasks. We find that, while the representations LMs leverage in performing each task are highly entangled, they may be meaningfully interpreted in terms of the tasks where they are most utilized; and more broadly, that CALM enables an expanded scope of inquiry in LM analysis that may be useful in predicting and explaining weaknesses of existing LMs.
翻译:尽管大型预训练语言模型(LM)在多种提示任务上取得了近期成功,但这些模型在面对输入或应用上下文的微小变化时可能表现出惊人的脆弱性。为深入理解此类行为并推动更稳健语言模型的设计,我们提出一个通用实验框架CALM(基于能力的语言模型分析),该框架通过针对性因果干预来破坏语言模型对各类语言属性的内部表征,从而评估其在执行特定任务时利用每种表征的程度。我们以基于梯度的对抗攻击实现这些干预(与先前的因果探测方法不同,该方法能够针对关系属性的任意编码表征),并通过案例研究分析BERT类语言模型在执行相关关系提示任务时如何利用多种关系属性的表征。研究发现:语言模型在执行每个任务时所利用的表征虽高度纠缠,但可根据其最常被使用的任务进行有意义的解释;更广泛而言,CALM拓展了语言模型分析的研究范围,有助于预测和解释现有语言模型的弱点。