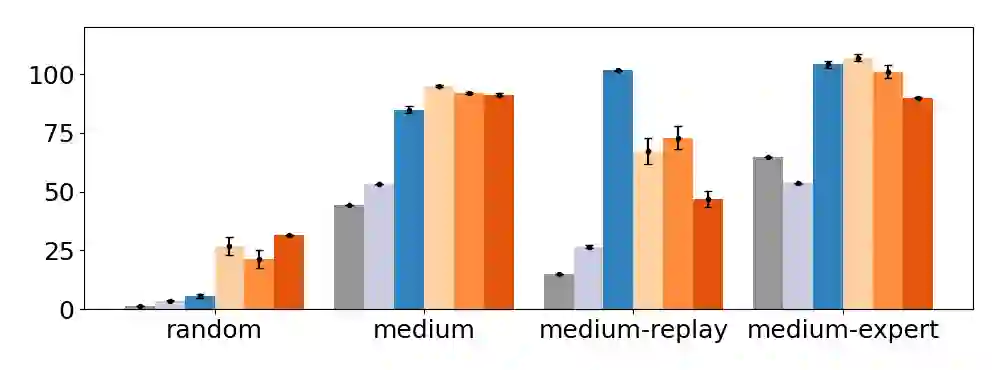
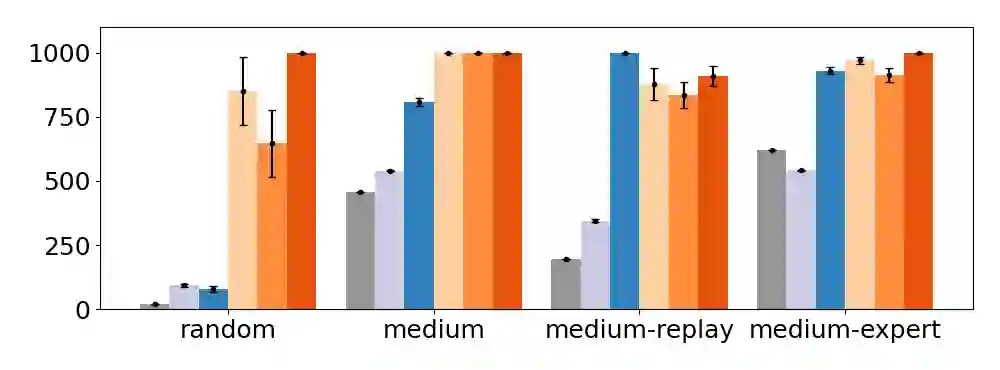
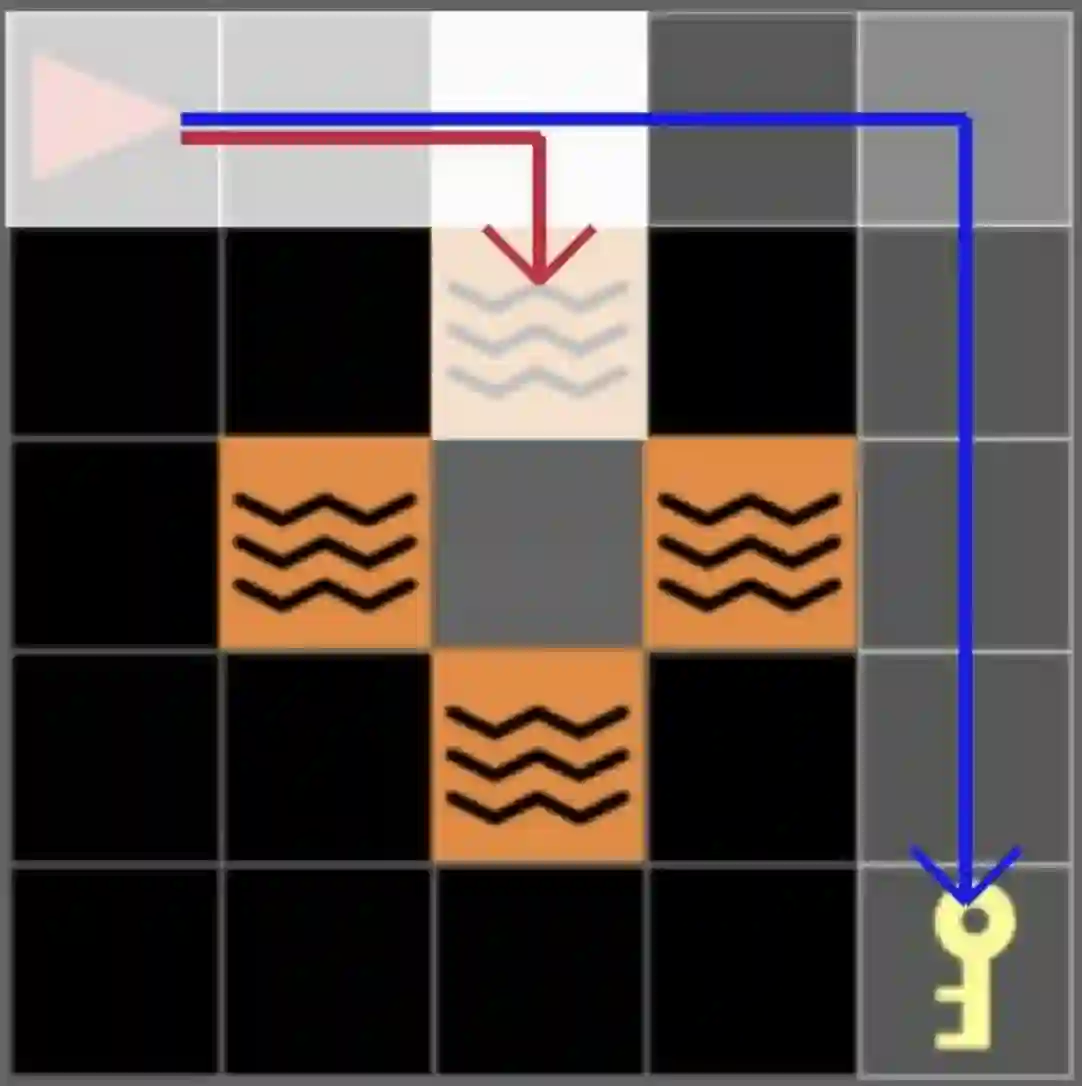
We present a novel observation about the behavior of offline reinforcement learning (RL) algorithms: on many benchmark datasets, offline RL can produce well-performing and safe policies even when trained with "wrong" reward labels, such as those that are zero everywhere or are negatives of the true rewards. This phenomenon cannot be easily explained by offline RL's return maximization objective. Moreover, it gives offline RL a degree of robustness that is uncharacteristic of its online RL counterparts, which are known to be sensitive to reward design. We demonstrate that this surprising robustness property is attributable to an interplay between the notion of pessimism in offline RL algorithms and certain implicit biases in common data collection practices. As we prove in this work, pessimism endows the agent with a "survival instinct", i.e., an incentive to stay within the data support in the long term, while the limited and biased data coverage further constrains the set of survival policies. Formally, given a reward class -- which may not even contain the true reward -- we identify conditions on the training data distribution that enable offline RL to learn a near-optimal and safe policy from any reward within the class. We argue that the survival instinct should be taken into account when interpreting results from existing offline RL benchmarks and when creating future ones. Our empirical and theoretical results suggest a new paradigm for RL, whereby an agent is nudged to learn a desirable behavior with imperfect reward but purposely biased data coverage.
翻译:我们提出了一个关于离线强化学习算法行为的新观察:在许多基准数据集上,即使使用“错误”的奖励标签(例如全零标签或真实奖励的相反数)进行训练,离线强化学习仍能产生性能良好且安全的策略。这种现象无法单纯通过离线强化学习的回报最大化目标来解释。此外,这赋予了离线强化学习一种其在线对应物(以对奖励设计敏感著称)所不具备的鲁棒性。我们证明,这种惊人的鲁棒性属性源于离线强化学习算法中的悲观主义概念与常见数据收集实践中的某些隐性偏差之间的相互作用。正如本文所证明的,悲观主义赋予智能体一种“生存本能”,即长期停留在数据支持范围内的激励,而有限且存在偏差的数据覆盖进一步约束了生存策略的集合。形式上,给定一个可能甚至不包含真实奖励的奖励类,我们确定了训练数据分布的条件,使得离线强化学习能够从该奖励类中的任意奖励学习到接近最优且安全的策略。我们认为,在解释现有离线强化学习基准测试的结果以及创建新基准时,应考虑这种生存本能。我们的实证与理论结果表明了一种新的强化学习范式,其中智能体通过不完美的奖励但刻意有偏差的数据覆盖被引导学习期望的行为。