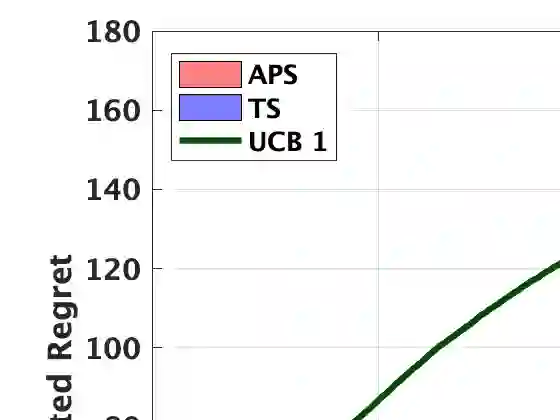
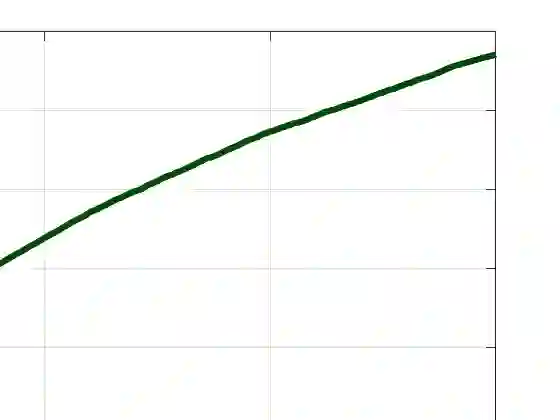
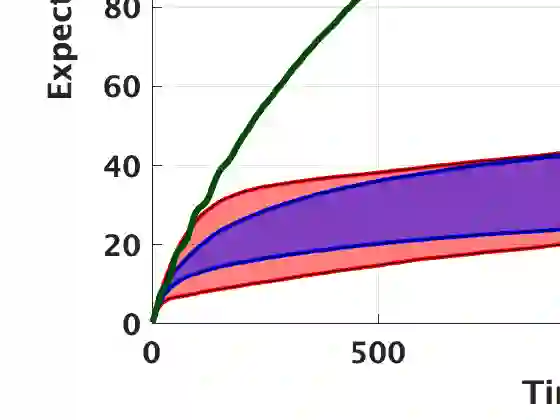
We develop a general theory to optimize the frequentist regret for sequential learning problems, where efficient bandit and reinforcement learning algorithms can be derived from unified Bayesian principles. We propose a novel optimization approach to generate "algorithmic beliefs" at each round, and use Bayesian posteriors to make decisions. The optimization objective to create "algorithmic beliefs," which we term "Algorithmic Information Ratio," represents an intrinsic complexity measure that effectively characterizes the frequentist regret of any algorithm. To the best of our knowledge, this is the first systematical approach to make Bayesian-type algorithms prior-free and applicable to adversarial settings, in a generic and optimal manner. Moreover, the algorithms are simple and often efficient to implement. As a major application, we present a novel algorithm for multi-armed bandits that achieves the "best-of-all-worlds" empirical performance in the stochastic, adversarial, and non-stationary environments. And we illustrate how these principles can be used in linear bandits, bandit convex optimization, and reinforcement learning.
翻译:我们发展了一套通用理论,用以优化序贯学习问题中的频率派遗憾值,该理论能够从统一的贝叶斯原理推导出高效的臂机与强化学习算法。我们提出了一种新颖的优化方法,在每一轮中生成“算法信念”,并利用贝叶斯后验进行决策。用于创建“算法信念”的优化目标被称为“算法信息比”,它代表一种内在复杂度度量,能够有效刻画任意算法的频率派遗憾值。据我们所知,这是首次以通用且最优的方式,系统性地使贝叶斯类型算法摆脱先验依赖并适用于对抗性场景。此外,这些算法简单且通常易于实现。作为主要应用,我们提出了一种多臂赌博机的新算法,该算法在随机、对抗性和非平稳环境中实现了“全环境最优”的实证性能,并进一步阐释了这些原理如何应用于线性臂机、臂机凸优化以及强化学习。