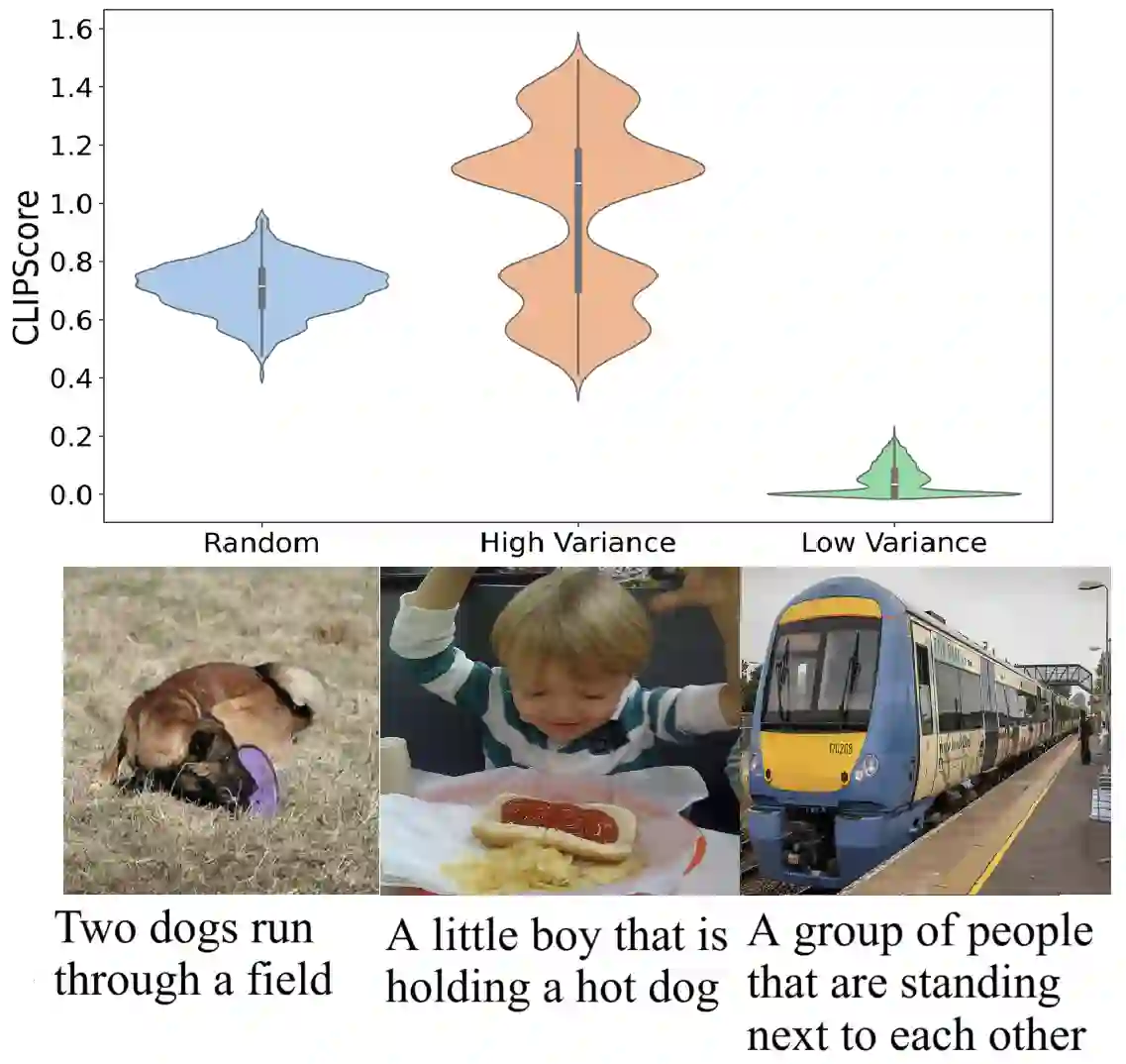
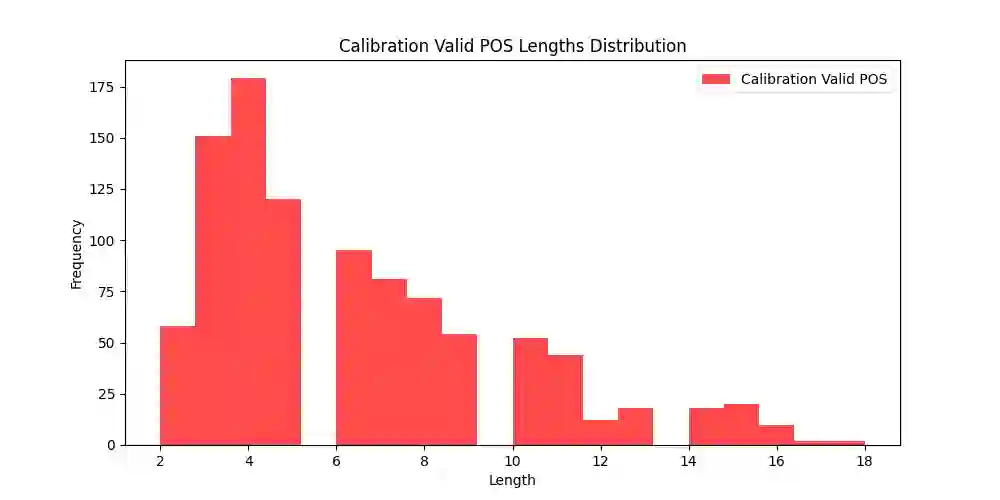
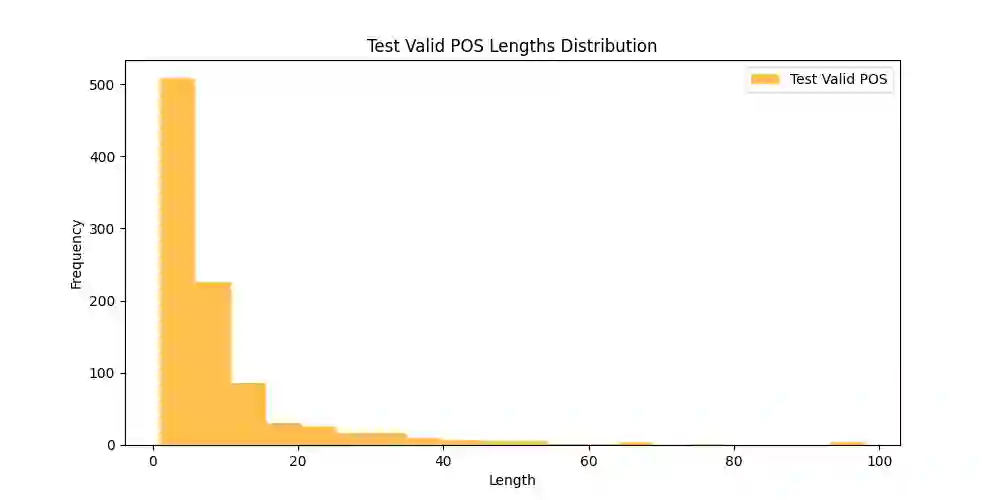
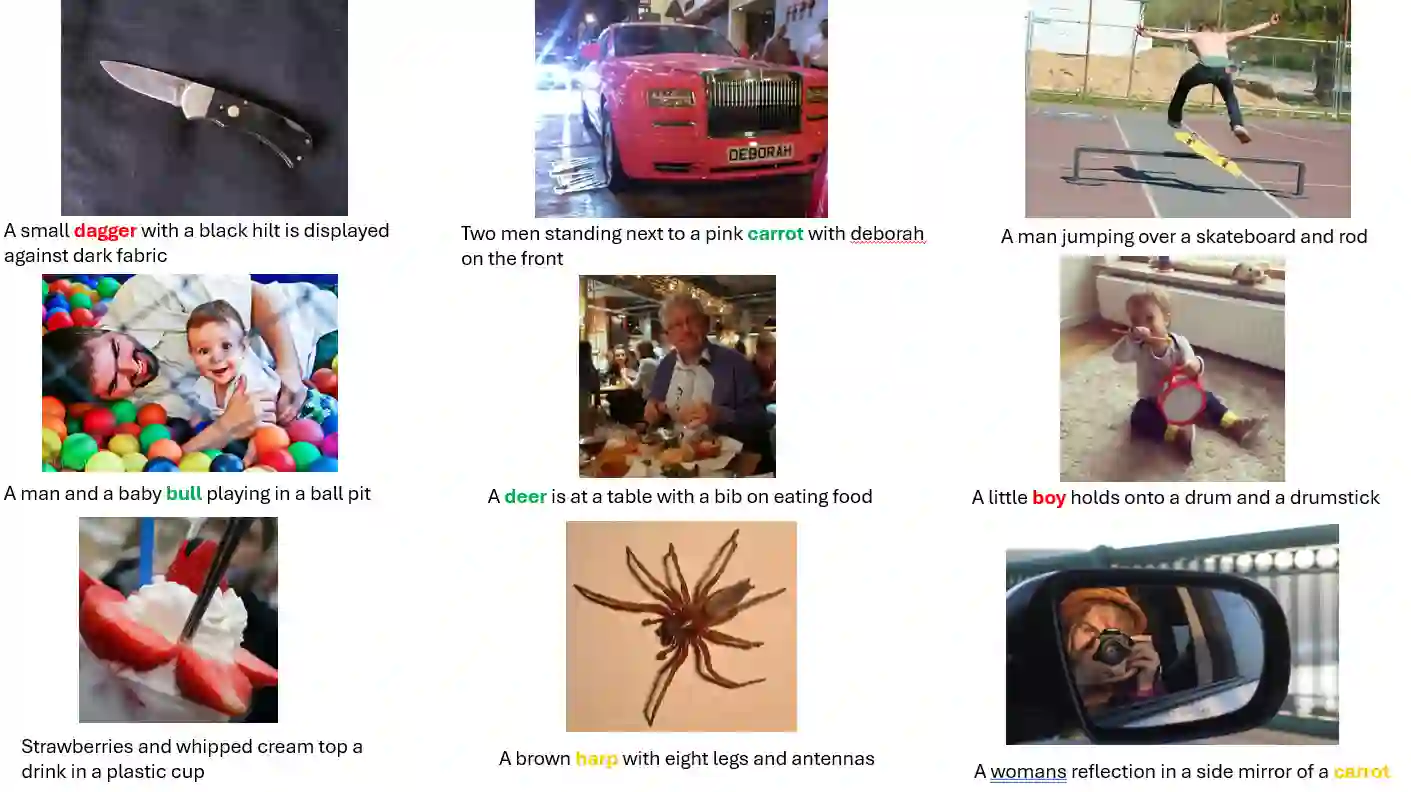
This study explores current limitations of learned image captioning evaluation metrics, specifically the lack of granular assessment for individual word misalignments within captions, and the reliance on single-point quality estimates without considering uncertainty. To address these limitations, we propose a simple yet effective strategy for generating and calibrating CLIPScore distributions. Leveraging a model-agnostic conformal risk control framework, we calibrate CLIPScore values for task-specific control variables, to tackle the aforementioned two limitations. Experimental results demonstrate that using conformal risk control, over the distributions produced with simple methods such as input masking, can achieve competitive performance compared to more complex approaches. Our method effectively detects misaligned words, while providing formal guarantees aligned with desired risk levels, and improving the correlation between uncertainty estimations and prediction errors, thus enhancing the overall reliability of caption evaluation metrics.
翻译:本研究探讨了当前基于学习的图像描述评估指标的局限性,具体表现为缺乏对描述中单个词汇错位的细粒度评估,以及依赖单点质量估计而未考虑不确定性。为应对这些局限,我们提出了一种简单而有效的策略,用于生成和校准CLIPScore分布。通过利用模型无关的保形风险控制框架,我们针对特定任务的控制变量校准CLIPScore值,以解决上述两个问题。实验结果表明,与输入掩码等简单方法生成的分布结合使用保形风险控制,相比更复杂的方法能获得具有竞争力的性能。我们的方法能有效检测错位词汇,同时提供与期望风险水平一致的形式化保证,并改善不确定性估计与预测误差之间的相关性,从而提升描述评估指标的整体可靠性。