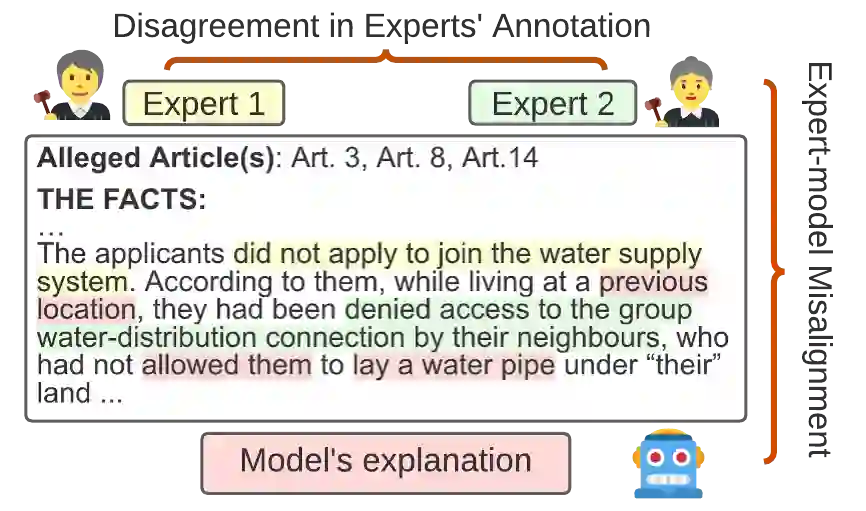
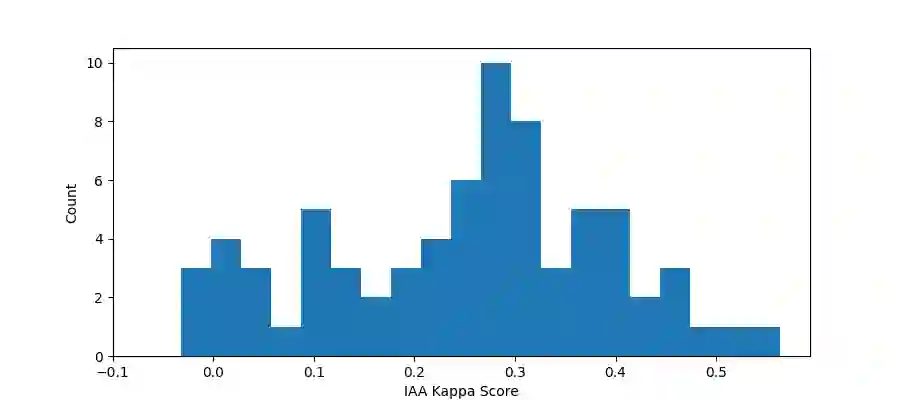
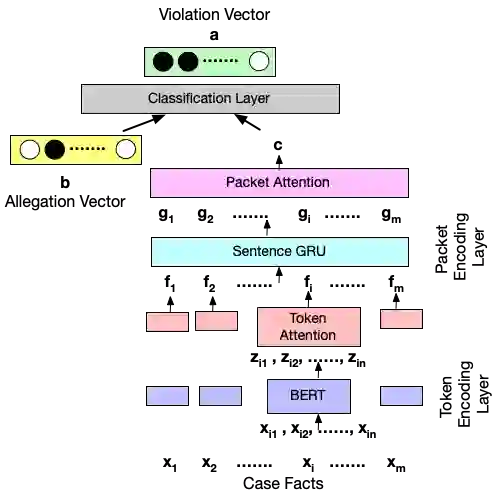
In legal NLP, Case Outcome Classification (COC) must not only be accurate but also trustworthy and explainable. Existing work in explainable COC has been limited to annotations by a single expert. However, it is well-known that lawyers may disagree in their assessment of case facts. We hence collect a novel dataset RAVE: Rationale Variation in ECHR1, which is obtained from two experts in the domain of international human rights law, for whom we observe weak agreement. We study their disagreements and build a two-level task-independent taxonomy, supplemented with COC-specific subcategories. To our knowledge, this is the first work in the legal NLP that focuses on human label variation. We quantitatively assess different taxonomy categories and find that disagreements mainly stem from underspecification of the legal context, which poses challenges given the typically limited granularity and noise in COC metadata. We further assess the explainablility of SOTA COC models on RAVE and observe limited agreement between models and experts. Overall, our case study reveals hitherto underappreciated complexities in creating benchmark datasets in legal NLP that revolve around identifying aspects of a case's facts supposedly relevant to its outcome.
翻译:在法律自然语言处理领域,案例结果分类不仅要准确,还需具备可信度和可解释性。现有可解释性案例结果分类研究局限于单一专家标注,但律师对案情事实的评估存在分歧已是共识。为此,我们构建了新型数据集RAVE(欧洲人权法院论据变异性),该数据集由两位国际人权法领域专家标注,其标注一致性较弱。通过研究专家分歧,我们建立了包含两级任务无关分类体系及案例结果分类特定子类别的分析框架。据我们所知,这是法律自然语言处理领域首个聚焦人工标注变异性的研究。我们定量评估了不同分类类别,发现分歧主要源于法律语境定义不充分,这对当前普遍存在的案例结果分类元数据粒度不足和噪声问题提出了挑战。进一步基于RAVE数据集评估当前最优案例结果分类模型的可解释性时,发现模型与专家之间存在有限一致性。总体而言,本案例研究揭示了法律自然语言处理中构建基准数据集时长期被忽视的复杂性——核心在于识别案情事实中与判决结果潜在相关的特征维度。