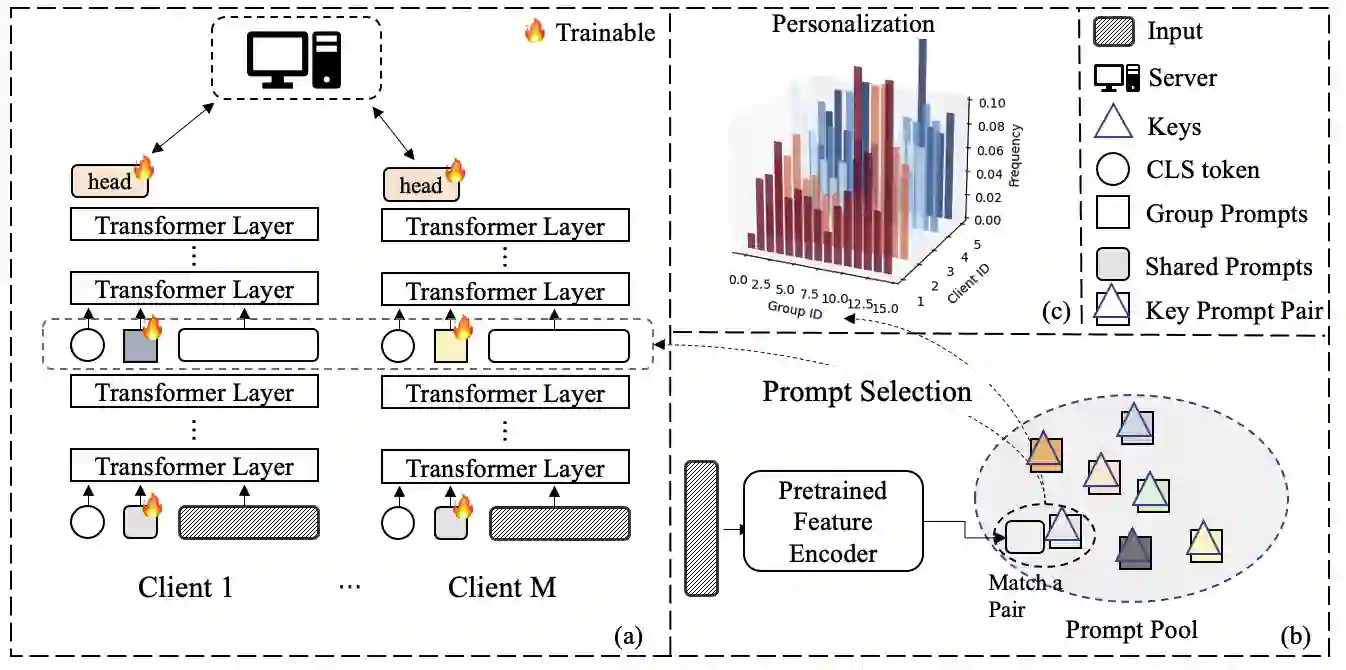
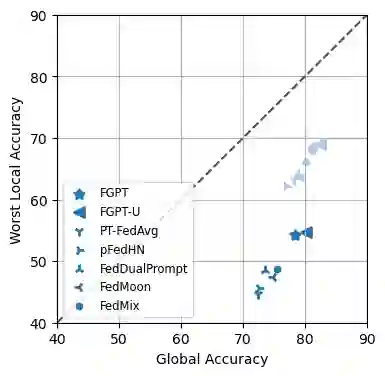
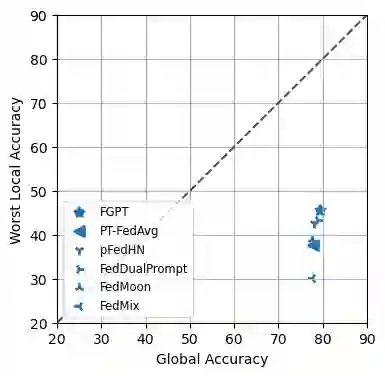
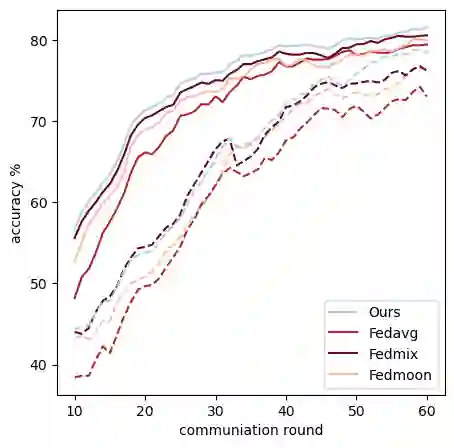
Transformers have achieved remarkable success in various machine-learning tasks, prompting their widespread adoption. In this paper, we explore their application in the context of federated learning (FL), with a particular focus on heterogeneous scenarios where individual clients possess diverse local datasets. To meet the computational and communication demands of FL, we leverage pre-trained Transformers and use an efficient prompt-tuning strategy. Our strategy introduces the concept of learning both shared and group prompts, enabling the acquisition of universal knowledge and group-specific knowledge simultaneously. Additionally, a prompt selection module assigns personalized group prompts to each input, aligning the global model with the data distribution of each client. This approach allows us to train a single global model that can automatically adapt to various local client data distributions without requiring local fine-tuning. In this way, our proposed method effectively bridges the gap between global and personalized local models in Federated Learning and surpasses alternative approaches that lack the capability to adapt to previously unseen clients. The effectiveness of our approach is rigorously validated through extensive experimentation and ablation studies.
翻译:Transformer已在各类机器学习任务中取得了显著成功,促使其被广泛采用。本文探索其在联邦学习场景中的应用,特别聚焦于各客户端拥有异质本地数据集的异构场景。为满足联邦学习的计算与通信需求,我们采用预训练Transformer并引入高效的提示调优策略。该策略提出同时学习共享提示与组提示的概念,从而同步获取通用知识与组特定知识。此外,提示选择模块为每个输入分配个性化组提示,使全局模型与各客户端的数据分布对齐。该方法可训练单一全局模型,无需本地微调即可自动适应不同客户端的本地数据分布。通过这种方式,我们提出的方法有效弥合了联邦学习中全局模型与个性化本地模型之间的差距,并超越了那些无法适应未见客户端的替代方案。大量实验与消融研究严格验证了该方法的有效性。