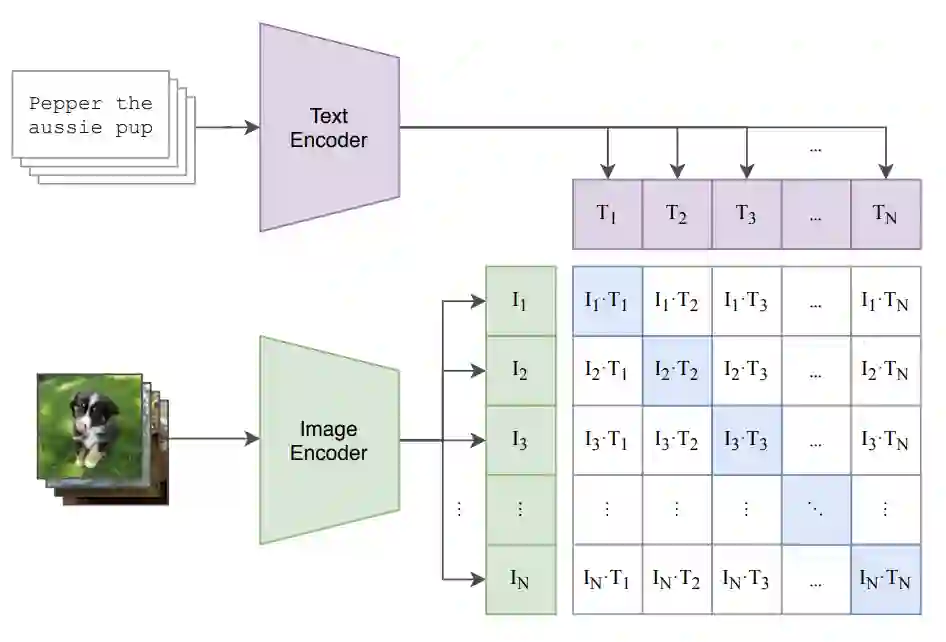
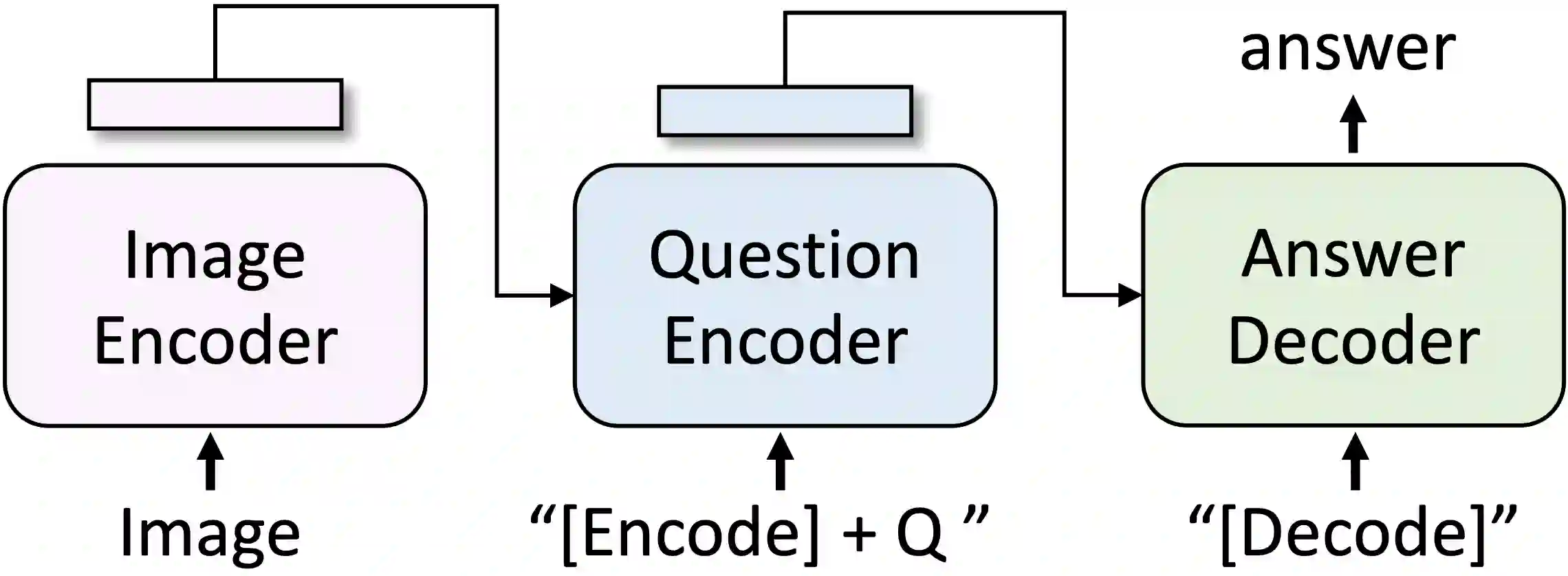
The surge in multimodal AI's success has sparked concerns over data privacy in vision-and-language tasks. While CLIP has revolutionized multimodal learning through joint training on images and text, its potential to unintentionally disclose sensitive information necessitates the integration of privacy-preserving mechanisms. We introduce a differentially private adaptation of the Contrastive Language-Image Pretraining (CLIP) model that effectively addresses privacy concerns while retaining accuracy. Our proposed method, Dp-CLIP, is rigorously evaluated on benchmark datasets encompassing diverse vision-and-language tasks such as image classification and visual question answering. We demonstrate that our approach retains performance on par with the standard non-private CLIP model. Furthermore, we analyze our proposed algorithm under linear representation settings. We derive the convergence rate of our algorithm and show a trade-off between utility and privacy when gradients are clipped per-batch and the loss function does not satisfy smoothness conditions assumed in the literature for the analysis of DP-SGD.
翻译:多模态AI的成功浪潮引发了视觉-语言任务中的数据隐私担忧。尽管CLIP通过图像与文本的联合训练革新了多模态学习,但其无意中泄露敏感信息的潜在风险,使得集成隐私保护机制成为必要。我们提出了一种对比式语言-图像预训练(CLIP)模型的差分隐私适配方法,能在有效解决隐私问题的同时保持准确性。所提出的方法Dp-CLIP在涵盖图像分类、视觉问答等多样化视觉-语言任务的基准数据集上进行了严格评估。研究表明,我们的方法在性能上与标准非隐私CLIP模型相当。此外,我们在线性表示框架下分析了该算法,推导出其收敛速率,并揭示了在梯度按批次裁剪且损失函数不满足DP-SGD文献中假设的光滑性条件时,效用与隐私之间的权衡关系。